
Depth Anything 3:从任意视角重建视觉空间的革命性突破


字节跳动Seed团队推出的Depth Anything 3(DA3)标志着3D计算机视觉领域的重大突破。这一统一模型能够从任意数量的视角(无论是否已知相机位姿)恢复3D视觉空间,仅使用普通的Transformer架构和深度-射线预测目标,就在3D重建和相机位姿估计任务上取得了最先进的成果。

一、核心方法与架构创新
1. 几何建模:深度-射线表示法
DA3的核心创新在于其深度-射线表示法,该方法通过两个互补输出为每个像素编码3D几何信息:
1. 深度图 $D(u,v)$:标准的每像素深度值
2. 射线图 $r = (t, d)$:6维向量,编码射线原点$t$(相机中心)和方向$d$(反投影的像素方向)
世界坐标系中的3D点$P$通过以下公式计算:
这种表示法相比传统方法具有显著优势。射线方向$d$特意不做归一化处理,保留了投影尺度信息,这对精确重建至关重要。
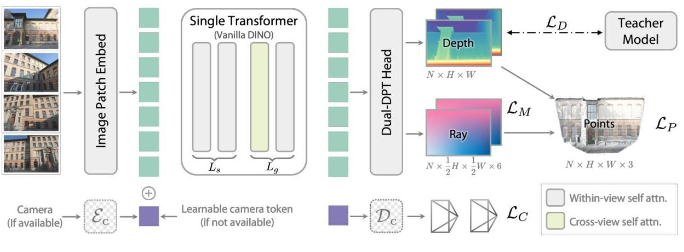
2. 架构设计:简约而不简单
DA3的架构包含三个主要组件:
1. 单一Transformer骨干网络:采用标准Vision Transformer(如DINOv2-ViT-L),无需任何架构修改,充分利用大规模预训练获得的强大特征表示能力。
2. 输入自适应的跨视角注意力机制:Transformer层分为两组——初始层($L_s$)在各图像内独立应用自注意力,后续层($L_g$)通过动态重排输入标记,在跨视角和视角内注意力之间交替。这种设计自然地适应不同的输入场景。
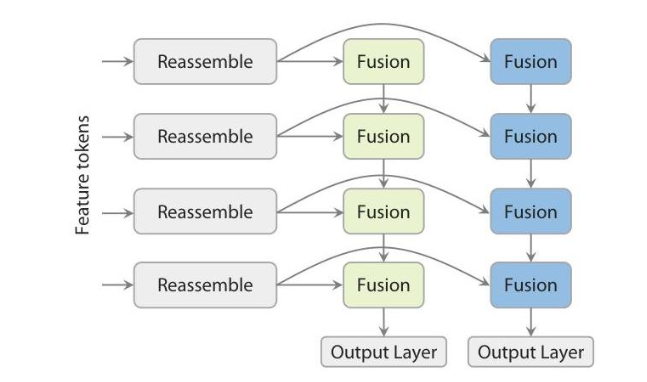
3. 双DPT预测头:特征通过共享的重组装模块后,分流到两个独立的融合层集合——一个优化用于深度预测,另一个用于射线预测,最后通过独立的输出层生成结果。
二、师生训练范式:突破数据限制
DA3通过创新的师生训练方法,克服了真实世界3D数据噪声多、不完整的限制:
DA3-教师模型开发:首先在合成数据上训练强大的单目深度估计模型。该教师模型是Depth Anything 2的增强版本,在涵盖多样化场景的扩展合成数据集上训练。
伪标签生成:对于真实世界数据集,DA3-教师模型生成高质量、密集的伪深度标签,通过RANSAC最小二乘法与原始稀疏真值进行稳健对齐。
训练目标:模型通过加权组合的L1损失进行优化:
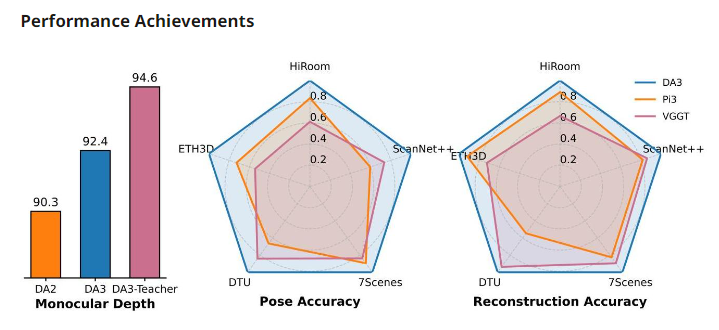
三、性能成就:全面领先的技术指标
在新引入的Visual Geometry Benchmark(包含5个数据集的89个场景)上,DA3在多个3D视觉任务中确立了新的技术标杆:
相机位姿估计:DA3-Giant在相机位姿精度上相比VGGT等先前最优方法实现了35.7% 的平均提升,在ScanNet++等挑战性数据集上表现出33% 的相对增益。
3D重建:该模型在几何重建方面创下新纪录,在所有五种无位姿评估设置中均优于竞争对手,相比VGGT平均提升23.6%,相比Pi3提升21.5%。
效率优势:值得注意的是,DA3-Large模型(0.36B参数)在十个重建设置中的五个上都优于VGGT(1.19B参数),尽管规模仅为后者的三分之一,这突显了显著的效率提升。
四、应用扩展与实用价值
DA3的多功能性超越了基本的几何估计,延伸到实际应用中:
前馈新颖视角合成:当适配用于3D高斯泼溅时,DA3在渲染质量指标(PSNR、SSIM、LPIPS)上显著优于专门方法(pixelSplat、MVSplat、DepthSplat)。
度量深度估计:专门的DA3-metric变体在ETH3D基准测验中取得了最先进的结果,并在标准数据集(NYUv2、KITTI、SUN-RGBD、DIODE)上表现出竞争力。
多样化场景的鲁棒性:DA3的鲁棒性延伸到具有挑战性的真实世界场景,从建筑地标到复杂的室内环境。该模型成功处理了尺度变化、光照条件和结构复杂性,这些因素常常挑战传统的3D重建方法。

五、重要意义与未来方向
Depth Anything 3代表了3D计算机视觉向简约基础模型的范式转变。通过证明单个未经修改的Transformer能够在多样化3D任务中实现最先进的性能,DA3挑战了普遍认知——即复杂、专门的架构对于高质量的3D理解是必要的。
这项工作强调利用大规模预训练模型,结合精心设计的几何表示和鲁棒的训练范式,为统一3D感知的未来研究提供了模板。在保持效率提升的同时实现显著的性能改进(位姿估计提升高达35.7%),表明这种方法可以 democratize 高质量3D视觉能力的访问。
综合基准测验的引入以及发布模型和数据集的承诺,进一步将DA3定位为推动该领域发展的重要基础。这项工作代表了向通用、可扩展和实用的3D理解系统迈出的重要一步,是实现能够以类人空间智能感知、理解和推理物理世界的多功能3D基础模型的重要里程碑。
