在人工智能应用日益普及的今天,大语言模型(LLM)的上下文窗口不断扩大,但令牌成本仍然是实际应用中的重要考量因素。传统的JSON格式虽然通用,但其冗余的标点符号和冗长的结构在LLM提示中造成了显著的令牌浪费。
一、TOON格式的核心价值
令牌效率的革命性提升
TOON(Token-Oriented Object Notation)是一种专为LLM设计的紧凑、人类可读的数据编码格式。它通过结合YAML的缩进结构和CSV的表格布局,实现了对JSON数据模型的无损序列化,同时在令牌效率上实现了显著突破。
基准验证数据证明:
- 1. 在包含嵌套或半统一结构的混合数据集上,TOON相比标准JSON节省21.8% 的令牌
- 2. 在统一的对象数组场景下,令牌节省可达30-60%
- 3. 准确率表现优异:在209个数据检索问题中达到73.9% 的准确率,优于JSON的69.7%

二、技术架构与设计哲学
1. 深度优化的语法设计
TOON采用极简语法,消除了冗余的标点符号:
users[3]{id,name,role,lastLogin}:
1,Alice,admin,2025-01-15
2,Bob,user,2025-01-14
3,Charlie,user,2025-01-13
对比等效的JSON表示:
{
"users": [
{
"id": 1,
"name": "Alice",
"role": "admin",
"lastLogin": "2025-01-15"
},
// ... 更多对象
]
}
2. 智能的表格化数组
TOON的核心优势在于对统一对象数组的优化处理:
1. 字段声明仅出现一次,数据以行形式流式传输
2. 显式长度声明(如[3])为LLM提供验证机制
3. 支持多种分隔符(逗号、制表符、管道符)
3. 可选的关键字折叠
v1.5规范引入的关键字折叠功能,进一步减少令牌使用:
data:
metadata:
items[2]: a,b
data.metadata.items[2]: a,b
三、性能表现与适用场景
准确性优势明显
在多模型基准中,TOON展现出卓越的准确性和效率平衡:
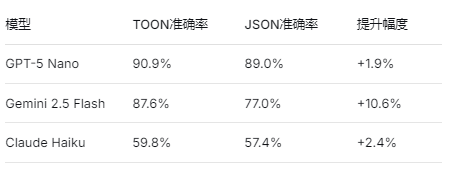
claude-haiku-4-5-20251001
→ TOON ████████████░░░░░░░░ 59.8% (125/209)
JSON ███████████░░░░░░░░░ 57.4% (120/209)
YAML ███████████░░░░░░░░░ 56.0% (117/209)
XML ███████████░░░░░░░░░ 55.5% (116/209)
JSON compact ███████████░░░░░░░░░ 55.0% (115/209)
CSV ██████████░░░░░░░░░░ 50.5% (55/109)
gemini-2.5-flash
→ TOON ██████████████████░░ 87.6% (183/209)
CSV █████████████████░░░ 86.2% (94/109)
JSON compact ████████████████░░░░ 82.3% (172/209)
YAML ████████████████░░░░ 79.4% (166/209)
XML ████████████████░░░░ 79.4% (166/209)
JSON ███████████████░░░░░ 77.0% (161/209)
gpt-5-nano
→ TOON ██████████████████░░ 90.9% (190/209)
JSON compact ██████████████████░░ 90.9% (190/209)
JSON ██████████████████░░ 89.0% (186/209)
CSV ██████████████████░░ 89.0% (97/109)
YAML █████████████████░░░ 87.1% (182/209)
XML ████████████████░░░░ 80.9% (169/209)
grok-4-fast-non-reasoning
→ TOON ███████████░░░░░░░░░ 57.4% (120/209)
JSON ███████████░░░░░░░░░ 55.5% (116/209)
JSON compact ███████████░░░░░░░░░ 54.5% (114/209)
YAML ███████████░░░░░░░░░ 53.6% (112/209)
XML ███████████░░░░░░░░░ 52.6% (110/209)
CSV ██████████░░░░░░░░░░ 52.3% (57/109)
👥 Uniform employee records ┊ Tabular: 100%
│
CSV ███████████████████░ 46,954 tokens
TOON ████████████████████ 49,831 tokens (+6.1% vs CSV)
├─ vs JSON (−60.7%) 126,860 tokens
├─ vs JSON compact (−36.8%) 78,856 tokens
├─ vs YAML (−50.0%) 99,706 tokens
└─ vs XML (−66.0%) 146,444 tokens
📈 Time-series analytics data ┊ Tabular: 100%
│
CSV ██████████████████░░ 8,388 tokens
TOON ████████████████████ 9,120 tokens (+8.7% vs CSV)
├─ vs JSON (−59.0%) 22,250 tokens
├─ vs JSON compact (−35.8%) 14,216 tokens
├─ vs YAML (−48.9%) 17,863 tokens
└─ vs XML (−65.7%) 26,621 tokens
⭐ Top 100 GitHub repositories ┊ Tabular: 100%
│
CSV ███████████████████░ 8,513 tokens
TOON ████████████████████ 8,745 tokens (+2.7% vs CSV)
├─ vs JSON (−42.3%) 15,145 tokens
├─ vs JSON compact (−23.7%) 11,455 tokens
├─ vs YAML (−33.4%) 13,129 tokens
└─ vs XML (−48.8%) 17,095 tokens
──────────────────────────────────── Total ────────────────────────────────────
CSV ███████████████████░ 63,855 tokens
TOON ████████████████████ 67,696 tokens (+6.0% vs CSV)
├─ vs JSON (−58.8%) 164,255 tokens
├─ vs JSON compact (−35.2%) 104,527 tokens
├─ vs YAML (−48.2%) 130,698 tokens
└─ vs XML (−64.4%) 190,160 tokens
🛒 E-commerce orders with nested structures ┊ Tabular: 33%
│
TOON █████████████░░░░░░░ 72,771 tokens
├─ vs JSON (−33.1%) 108,806 tokens
├─ vs JSON compact (+5.5%) 68,975 tokens
├─ vs YAML (−14.2%) 84,780 tokens
└─ vs XML (−40.5%) 122,406 tokens
🧾 Semi-uniform event logs ┊ Tabular: 50%
│
TOON █████████████████░░░ 153,211 tokens
├─ vs JSON (−15.0%) 180,176 tokens
├─ vs JSON compact (+19.9%) 127,731 tokens
├─ vs YAML (−0.8%) 154,505 tokens
└─ vs XML (−25.2%) 204,777 tokens
🧩 Deeply nested configuration ┊ Tabular: 0%
│
TOON ██████████████░░░░░░ 631 tokens
├─ vs JSON (−31.3%) 919 tokens
├─ vs JSON compact (+11.9%) 564 tokens
├─ vs YAML (−6.2%) 673 tokens
└─ vs XML (−37.4%) 1,008 tokens
──────────────────────────────────── Total ────────────────────────────────────
TOON ████████████████░░░░ 226,613 tokens
├─ vs JSON (−21.8%) 289,901 tokens
├─ vs JSON compact (+14.9%) 197,270 tokens
├─ vs YAML (−5.6%) 239,958 tokens
└─ vs XML (−31.0%) 328,191 tokens
适用场景分析
- 1. 理想场景:统一的对象数组(表格适合度≈100%)
- 2. 良好场景:半统一数组(表格适合度40-60%)
- 3. 不推荐:深度嵌套结构(表格适合度≈0%)
四、实际应用与集成方案
快速开始示例
npx @toon-format/cli data.json -o output.toon
npx @toon-format/cli data.json --stats
TypeScript集成
import { encode, decode } from '@toon-format/toon'
const data = {
items: [
{ sku: 'A1', qty: 2, price: 9.99 },
{ sku: 'B2', qty: 1, price: 14.5 }
]
}
const toonString = encode(data)
// items[2]{sku,qty,price}:
// A1,2,9.99
// B2,1,14.5
const restoredData = decode(toonString)
LLM提示词最佳实践
```toon
context:
task: 分析用户行为数据
timeframe: 2025年1月
metrics: [clickRate,conversion,retention]
users[3]{id,segment,activityScore}:
1,premium,0.89
2,standard,0.67
3,premium,0.92
请基于以上数据生成分析报告。保持TOON格式输出结果。
五、未来展望与行业影响
TOON代表了数据序列化格式的重要演进方向:
1. 成本优化:显著降低LLM应用的令牌消耗
2. 准确性提升:结构化设计减少模型解析错误
3. 开发者友好:保持人类可读性的同时提升机器效率
随着AI应用对效率要求的不断提高,TOON这种专门为LLM优化的数据格式,有望成为AI工程领域的重要基础设施。
总结
TOON通过创新的语法设计和深度优化,在保持数据完整性的同时,为LLM应用提供了显著的效率提升。其开源特性和活跃的社区支持,使其成为处理结构化LLM数据的理想选择。随着规范的持续完善和生态的不断扩大,TOON有望在AI数据交换领域发挥越来越重要的作用。



