目录
前言:为什么要改进 DQN?
2. Double DQN (DDQN):解决高估问题
2.1 问题根源:Maximization Bias
2.2 数学原理与改进
2.3 PyTorch 代码实现
3. Dueling DQN:网络结构的革新
3.1 直觉理解
3.2 数学公式
3.3 PyTorch 模型结构
4. Prioritized Experience Replay (PER):让经验更有价值
4.1 核心思想
4.2 数学推导:概率与权重修正
4.3 代码逻辑(简化版)
5. 性能对比图示
6. 总结 (Summary)
前言:为什么要改进 DQN?
在上一篇文章中,我们介绍了 DQN (Deep Q-Network),它成功地将深度学习引入了强化学习。然而,原始的 DQN 并不完美,它存在几个显著的问题:
- Q 值高估 (Overestimation Bias):DQN 倾向于高估动作的价值,导致策略不仅不收敛,还可能产生震荡。
- 采样效率低:经验回放池 (Replay Buffer) 是随机采样的,但在训练初期,很多样本可能是“无效”或“重复”的,有些关键样本却被忽略了。
- 状态价值识别难:在某些状态下,无论采取什么动作,结果都差不多(比如游戏结束前的一瞬间),但 DQN 还是会费劲地去计算每个动作的 Q 值。
为了解决这些问题,DeepMind 后续推出了一系列改进算法。今天我们就来深入剖析其中最经典的三大金刚:Double DQN, Dueling DQN, 和 Prioritized Experience Replay (PER)。
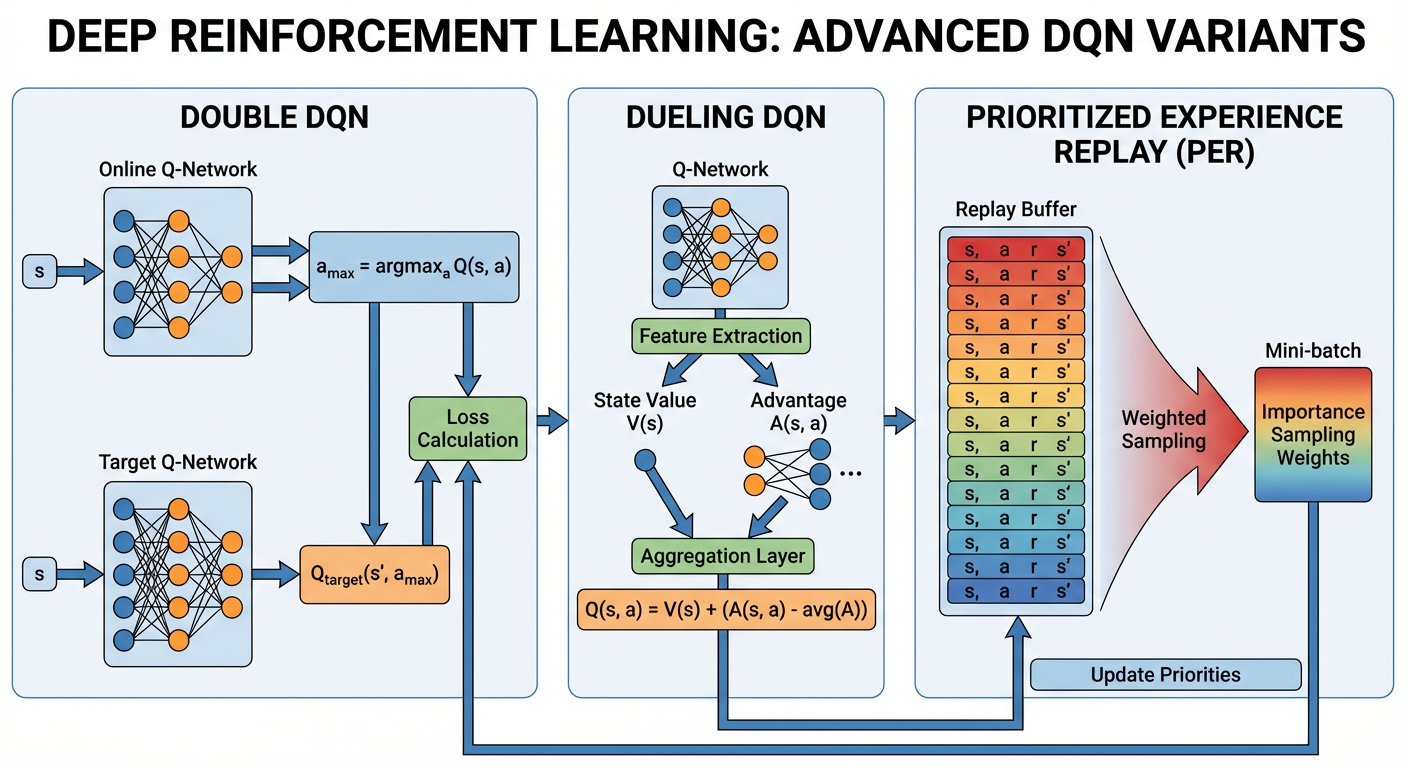
2. Double DQN (DDQN):解决高估问题
2.1 问题根源:Maximization Bias
在标准 DQN 中,目标 Q 值 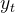 的计算公式是:
的计算公式是:

这里有一个严重的问题:我们在选择动作和评估动作时,用的是同一个网络(目标网络 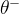 )的最大值操作。
)的最大值操作。
如果目标网络存在误差(这在训练初期是必然的),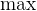 操作会倾向于选择那些被高估的动作,导致误差不断累积。
操作会倾向于选择那些被高估的动作,导致误差不断累积。
2.2 数学原理与改进
Double DQN 的核心思想是解耦 (Decoupling):
- 动作选择 (Selection):使用当前网络 (Main Network,
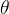 ) 来决定哪个动作是最好的。
) 来决定哪个动作是最好的。 - 动作评估 (Evaluation):使用目标网络 (Target Network, ) 来计算该动作的价值。
改进后的目标公式如下:
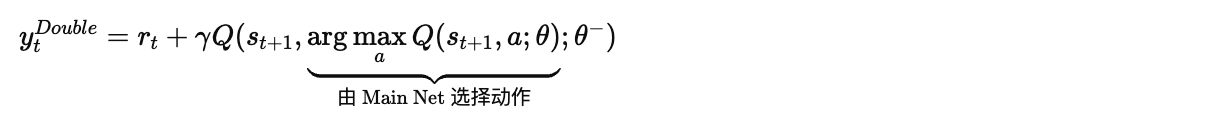
2.3 PyTorch 代码实现
这一改动在代码中非常简单,只需要修改计算 Target Q 值的几行代码:
def compute_loss(self, batch):
states, actions, rewards, next_states, dones = batch
# 1. 计算当前 Q(s, a)
current_q = self.q_net(states).gather(1, actions)
with torch.no_grad():
# === Double DQN 核心修改 ===
# 步骤 A: 使用 Main Net 选择动作 argmax Q(s', a; theta)
next_actions = self.q_net(next_states).argmax(1).unsqueeze(1)
# 步骤 B: 使用 Target Net 评估该动作 Q(s', next_action; theta_target)
next_q = self.target_net(next_states).gather(1, next_actions)
# =========================
target_q = rewards + self.gamma * next_q * (1 - dones)
loss = nn.MSELoss()(current_q, target_q)
return loss
3. Dueling DQN:网络结构的革新
3.1 直觉理解
在很多场景下,状态本身的价值 (Value) 比 动作的价值 (Advantage) 更重要。
- 例子:在一个赛车游戏中,如果前面是一堵墙(状态 (s)),那么无论你向左转还是向右转(动作 (a)),结果都很糟糕。
原始 DQN 直接输出  ,它被迫学习每个动作的每一个细微差别。Dueling DQN 提出将网络拆分为两部分:
,它被迫学习每个动作的每一个细微差别。Dueling DQN 提出将网络拆分为两部分:
- 价值函数 (Value Function) (V(s)):评估当前状态的好坏。
- 优势函数 (Advantage Function) (A(s, a)):评估在该状态下,采取动作 (a) 比平均情况好多少。
3.2 数学公式
逻辑上,Q 值等于 V 值加上 A 值:

但在实际训练中,如果直接相加,神经网络无法区分哪个是 (V) 哪个是 (A)(即不可辨识性问题,Unidentifiability)。为了解决这个问题,我们通常强制让优势函数的平均值为 0。
最终的聚合公式(Aggregation Layer)为:
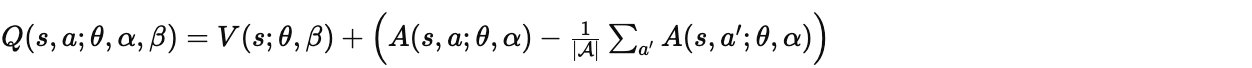
其中:
- 是卷积层共享参数。
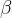 是 (V) 流的参数。
是 (V) 流的参数。 是 (A) 流的参数。
是 (A) 流的参数。
3.3 PyTorch 模型结构
Dueling DQN 改变的是网络模型定义:
class DuelingDQN(nn.Module):
def __init__(self, state_dim, action_dim):
super(DuelingDQN, self).__init__()
# 特征提取层 (共享)
self.feature_layer = nn.Sequential(
nn.Linear(state_dim, 128),
nn.ReLU()
)
# 优势流 (Advantage Stream)
self.advantage_layer = nn.Sequential(
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, action_dim)
)
# 价值流 (Value Stream)
self.value_layer = nn.Sequential(
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, 1) # 输出标量 V(s)
)
def forward(self, x):
features = self.feature_layer(x)
advantage = self.advantage_layer(features)
value = self.value_layer(features)
# === 核心公式:Q = V + (A - mean(A)) ===
q_values = value + (advantage - advantage.mean(dim=1, keepdim=True))
return q_values
4. Prioritized Experience Replay (PER):让经验更有价值
4.1 核心思想
普通的 Replay Buffer 是均匀采样 (Uniform Sampling)。这就像学生复习功课,不管会的还是不会的,都花同样的时间复习,效率极低。
PER 的思想是:我们要优先复习那些“让我们感到意外”的样本。
在强化学习中,“意外”程度由 TD-Error (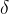 ) 来衡量:
) 来衡量:

TD-Error 越大,说明网络对这个样本预测得越不准,越需要学习。
4.2 数学推导:概率与权重修正
1. 采样概率
样本 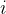 被采样的概率定义为:
被采样的概率定义为:

其中  (
( 是为了防止概率为 0), 控制优先级的程度(0 为均匀采样,1 为完全贪婪)。
是为了防止概率为 0), 控制优先级的程度(0 为均匀采样,1 为完全贪婪)。
2. 重要性采样权重 (Importance Sampling Weights)
因为我们改变了采样分布(不再是均匀分布),这会改变数据的期望值,导致模型有偏。为了修正偏差,我们需要在计算 Loss 时乘以权重 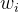 :
:

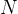 是 Buffer 大小。
是 Buffer 大小。- 从 0 线性增长到 1,用于抵消偏差。
4.3 代码逻辑(简化版)
由于完整的 PER 需要实现 SumTree 树形结构来保证 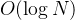 的采样速度,代码较长。这里展示核心的 Loss 计算逻辑:
的采样速度,代码较长。这里展示核心的 Loss 计算逻辑:
def update_with_per(self, beta):
# 1. 从 Buffer 中根据优先级采样
# indices: 样本索引, weights: IS权重, samples: 数据
indices, weights, samples = self.buffer.sample(self.batch_size, beta)
states, actions, rewards, next_states, dones = samples
weights = torch.FloatTensor(weights).to(self.device)
# 2. 计算 Q 值和 Target
current_q = self.q_net(states).gather(1, actions)
next_q = self.target_net(next_states).max(1)[0].unsqueeze(1)
target_q = rewards + self.gamma * next_q * (1 - dones)
# 3. 计算 Element-wise Loss (不求平均)
loss_element = (current_q - target_q).pow(2)
# 4. 加权 Loss
loss = (loss_element * weights).mean()
# 5. 反向传播
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 6. 更新样本优先级 (使用新的 TD-error)
td_errors = (target_q - current_q).detach().abs().cpu().numpy()
self.buffer.update_priorities(indices, td_errors + 1e-6)
5. 性能对比图示
为了直观展示这些改进的效果,我们可以对比在同一环境下(如 CartPole 或 Atari)各算法的收敛速度。
(以下代码用于生成对比示意图)
import matplotlib.pyplot as plt
import numpy as np
# 模拟数据
x = np.linspace(0, 500, 100)
y_dqn = 200 * (1 - np.exp(-x/100)) + np.random.normal(0, 5, 100)
y_double = 200 * (1 - np.exp(-x/80)) + np.random.normal(0, 5, 100)
y_dueling = 200 * (1 - np.exp(-x/60)) + np.random.normal(0, 5, 100)
y_per = 200 * (1 - np.exp(-x/50)) + np.random.normal(0, 5, 100) # 收敛最快
plt.figure(figsize=(10, 6))
plt.plot(x, y_dqn, label='DQN', alpha=0.6, linestyle='--')
plt.plot(x, y_double, label='Double DQN', linewidth=2)
plt.plot(x, y_dueling, label='Dueling DQN', linewidth=2)
plt.plot(x, y_per, label='Dueling + PER', linewidth=2, color='red')
plt.title("Performance Comparison: DQN Variants")
plt.xlabel("Episodes")
plt.ylabel("Score")
plt.legend()
plt.grid(True)
plt.show()
结论:通常情况下,Dueling DQN + Double DQN + PER 的组合(通常被称为 Rainbow 的雏形)能获得最快、最稳定的收敛效果。
6. 总结 (Summary)
今天我们深入探讨了 DQN 的家族成员:
最后的一个小彩蛋:如果你把 Double, Dueling, PER, Multi-step, Distributional, Noisy Nets 等所有改进全加在一起,就构成了强化学习界的“六边形战士” —— Rainbow DQN!
希望这篇文章能帮你打通 DQN 进阶的任督二脉!动手写代码试试吧!加油!


