
从此,SQL 不写一行,智能体全帮我搞定!


最近我零成本在本地搭了一个 SQL 智能体,不接入云、不付费、支持自然语言问答,简直是我日常开发提效的天花板。原来那些写 SQL 查业务数据、调接口前找字段、优化复杂 JOIN 的痛点,现在统统交给 AI 来搞定,精准又高效。
全程本地运行,无需担心数据外泄,也不需要依赖第三方平台,更重要的是 —— 完全开源、零成本,硬核好玩!
本篇文章就来分享我如何用最简单的方式,把自己的数据库"喂"给一个懂 SQL 的 AI,打造一个真正为开发者量身定制的"本地数据助理"。SQL 再也不是负担,而是乐趣。👨💻🚀
为什么要搭建本地 SQL 智能体?
在平常的开发工作中,我们常常需要根据业务需求写各种 SQL 查询。尤其在面对复杂的数据库时,编写 SQL 语句时要查找表结构、字段类型、外键关系等,往往需要花费大量时间和精力。虽然 SQL 写得多了,但还是容易出错,特别是写复杂的联合查询(JOIN)和子查询时。再加上开发过程中需求变化频繁,修改 SQL 成了必不可少的工作。
于是,我开始思考:有没有一种方式,可以让 AI 代替我写 SQL,自动理解我的需求并给出精准的查询语句?
市面上确实有不少 AI 工具可以生成 SQL,但它们大多需要把数据库结构甚至数据上传到云端。对于企业级项目或者涉及敏感数据的场景,这显然是不可接受的。
首先是基于安全,其次都是其次
所以我的目标很明确:
- 完全本地化:数据不出本机,杜绝泄露风险
- 零成本:不依赖付费 API,开源方案搞定
- 足够智能:能理解自然语言,生成准确的 SQL
技术方案选型
经过一些调研和实验,我决定结合以下技术栈来搭建这个"SQL 智能体":
| 组件 | 作用 | 说明 |
|---|---|---|
| Ollama | 本地大模型运行框架 | 支持一键部署各种开源模型 |
| Qwen2.5:7B | 对话大模型 | 阿里开源,中文理解能力强 |
| nomic-embed-text | 文本嵌入模型 | 将 DDL 转为向量,支持语义检索 |
| Anything LLM | 知识库 + 对话界面 | 开箱即用,支持文档投喂 |
整个方案的核心思路是:把数据库的 DDL(表结构定义)作为知识库投喂给 AI,当用户用自然语言提问时,AI 会基于这些表结构信息生成对应的 SQL 语句。
环境准备
在开始之前,确保你的机器满足以下条件:
- 内存:建议 16GB 以上(运行 7B 模型至少需要 8GB)
- 硬盘:预留 10GB 以上空间存放模型文件
- 系统:macOS / Linux / Windows 均可
实现步骤
安装 Ollama 并下载模型
Ollama 是一个非常方便的本地大模型运行框架,支持 macOS、Linux 和 Windows。访问 Ollama 官网 下载安装包,安装过程非常简单,一路下一步即可。
安装完成后,打开终端拉取我们需要的两个模型。
拉取对话模型 Qwen2.5:
ollama pull qwen2.5
根据你的电脑配置,可以选择不同参数量的版本。7B 版本大约 4.7GB,14B 版本约 9GB,配置好的机器可以尝试更大的模型以获得更好的效果。
拉取嵌入模型 nomic-embed-text:
ollama pull nomic-embed-text
nomic-embed-text 是一个高性能的开源嵌入模型,支持 8192 token 的大上下文窗口,非常适合处理较长的 DDL 文件。模型基于 nomic-bert 架构,参数量 137M,体积只有 274MB,对硬件要求很低。
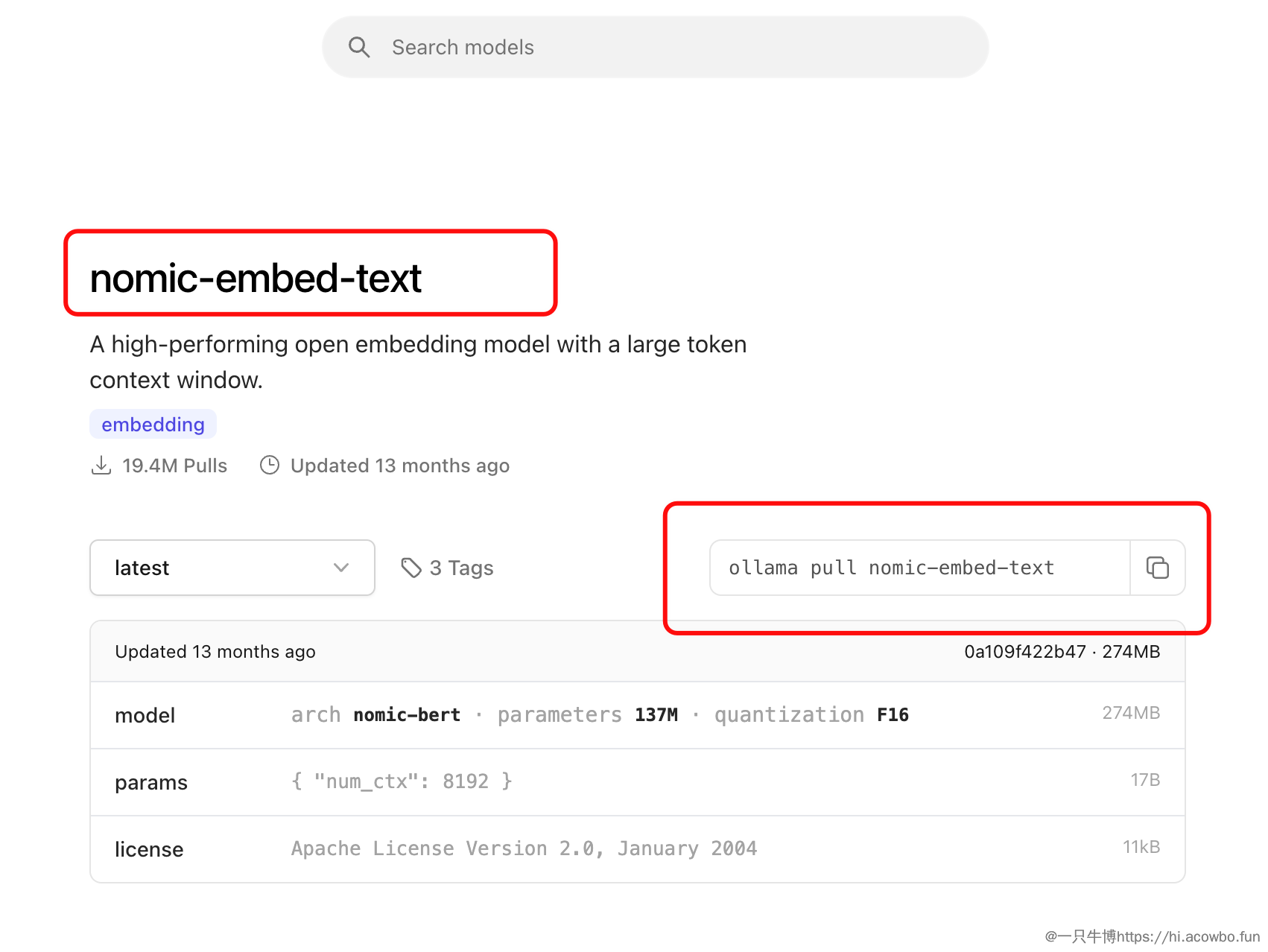
拉取完成后,可以用 ollama list 命令查看已安装的模型:
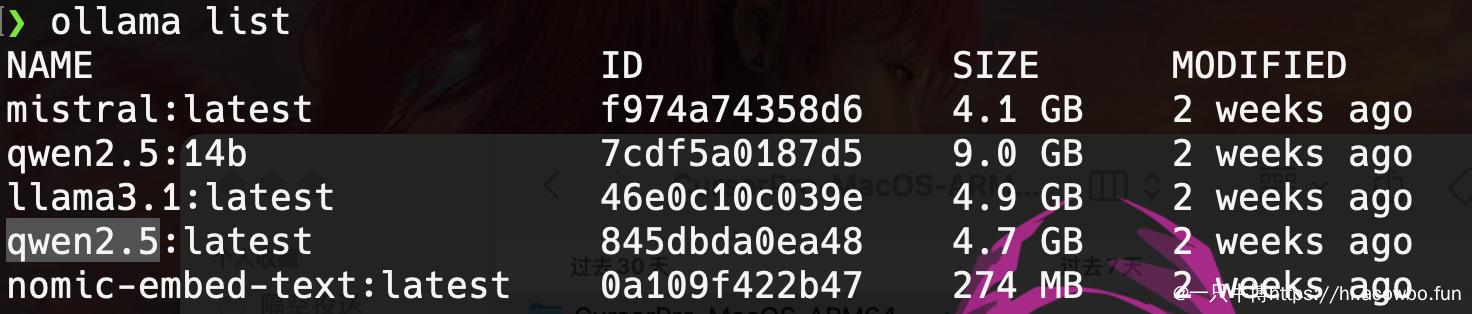
可以看到我本地已经安装了 qwen2.5:latest(4.7GB)和 nomic-embed-text:latest(274MB),这两个模型就是我们搭建 SQL 智能体的核心。
安装并配置 Anything LLM
Anything LLM 是一个开源的本地知识库工具,提供了友好的图形界面,支持文档投喂、向量检索和对话功能。访问 Anything LLM 官网 下载对应系统的安装包。
安装完成后,打开 Anything LLM,进入设置页面进行配置。
配置 LLM 提供商:
在「人工智能提供商」→「LLM 首选项」中,选择 Ollama 作为 LLM 提供商,这样就可以使用本地运行的大模型了。
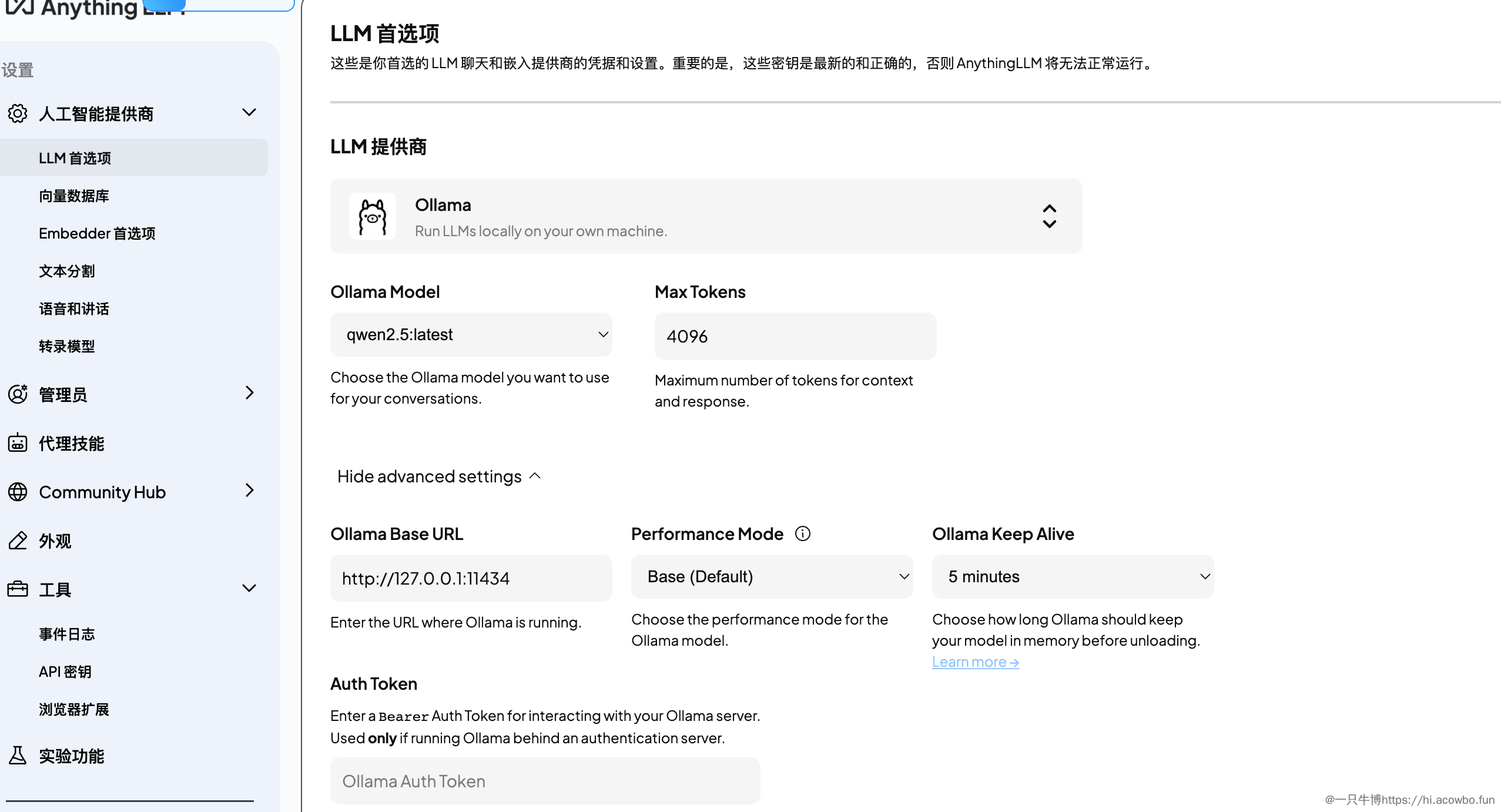
关键配置项:
- LLM 提供商:选择 Ollama
- Ollama Model:选择 qwen2.5:latest
- Max Tokens:设置为 4096(根据需要调整)
- Ollama Base URL:默认 http://127.0.0.1:11434
- Ollama Keep Alive:建议设置 5 分钟,避免频繁加载模型
配置嵌入引擎:
在「人工智能提供商」→「Embedder 首选项」中,同样选择 Ollama,并指定嵌入模型为 nomic-embed-text。
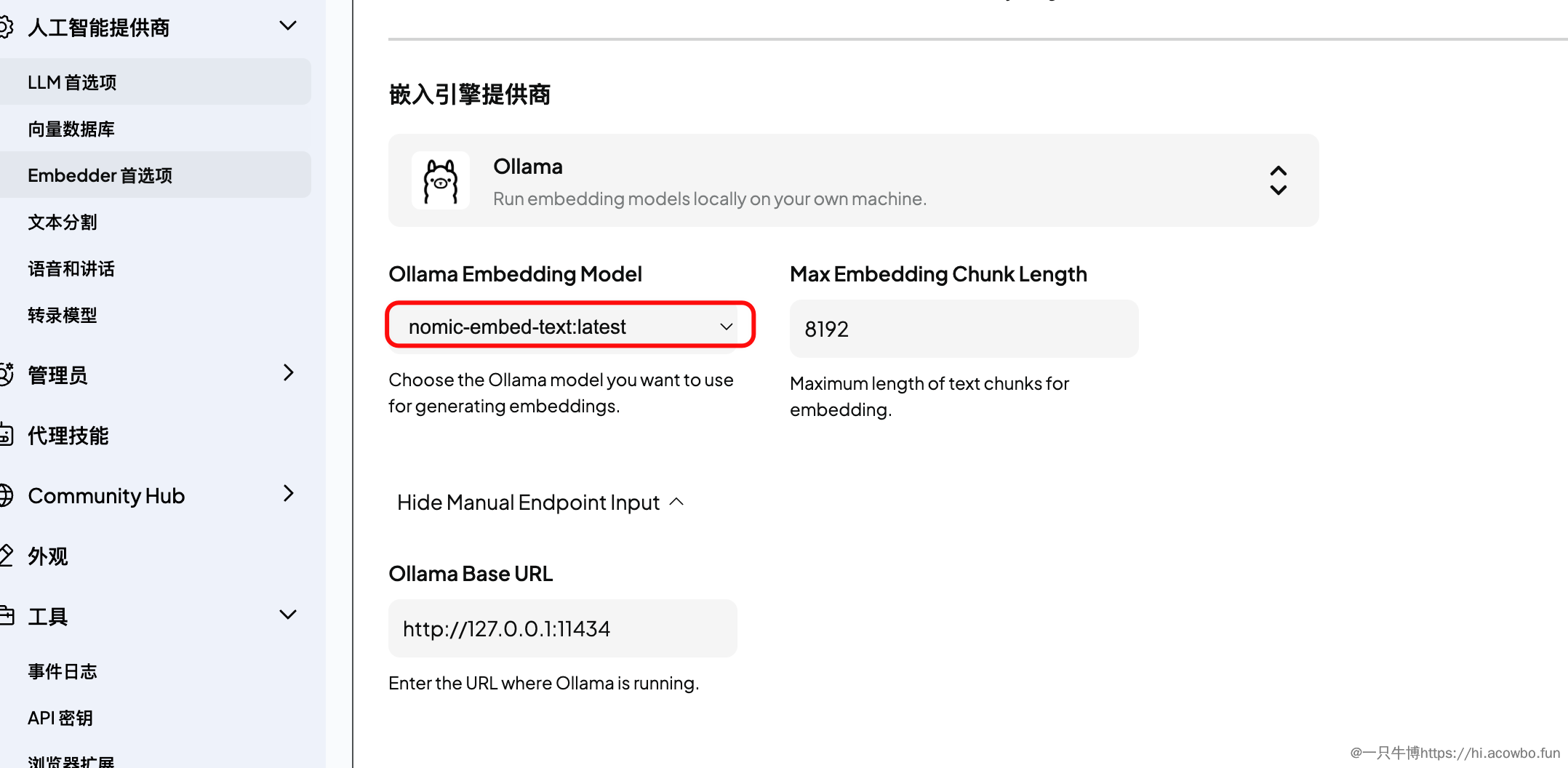
关键配置项:
- 嵌入引擎提供商:选择 Ollama
- Ollama Embedding Model:选择 nomic-embed-text:latest
- Max Embedding Chunk Length:设置为 8192(充分利用模型的上下文窗口)
创建工作区并投喂 DDL
配置完成后,就可以创建工作区并投喂数据库的 DDL 信息了。
准备 DDL 文件:
把你数据库的表结构导出为 DDL 文件(.sql 或 .txt 格式都可以)。DDL 文件应该包含完整的建表语句,包括字段名、字段类型、注释、索引、外键等信息。注释越详细,AI 生成的 SQL 就越准确。
示例 DDL 片段:
CREATE TABLE tb_bill (
id BIGINT PRIMARY KEY COMMENT '账单ID',
name VARCHAR(100) COMMENT '账单名称',
amount DECIMAL(10,2) COMMENT '金额',
category_id BIGINT COMMENT '分类ID',
is_deleted TINYINT DEFAULT 0 COMMENT '是否删除:0-否,1-是',
create_time DATETIME COMMENT '创建时间'
) COMMENT '账单表';
CREATE TABLE tb_category (
id BIGINT PRIMARY KEY COMMENT ‘分类ID’,
name VARCHAR(50) COMMENT ‘分类名称’,
type TINYINT COMMENT ‘类型:0-支出,1-收入’
) COMMENT ‘分类表’;
上传文档到工作区:
在 Anything LLM 中新建一个工作区(比如叫 "sql-assistant"),然后把 DDL 文件拖拽上传。上传后需要把文件从左侧的「My Documents」移动到右侧的工作区中,这样 AI 才能基于这些文档进行问答。
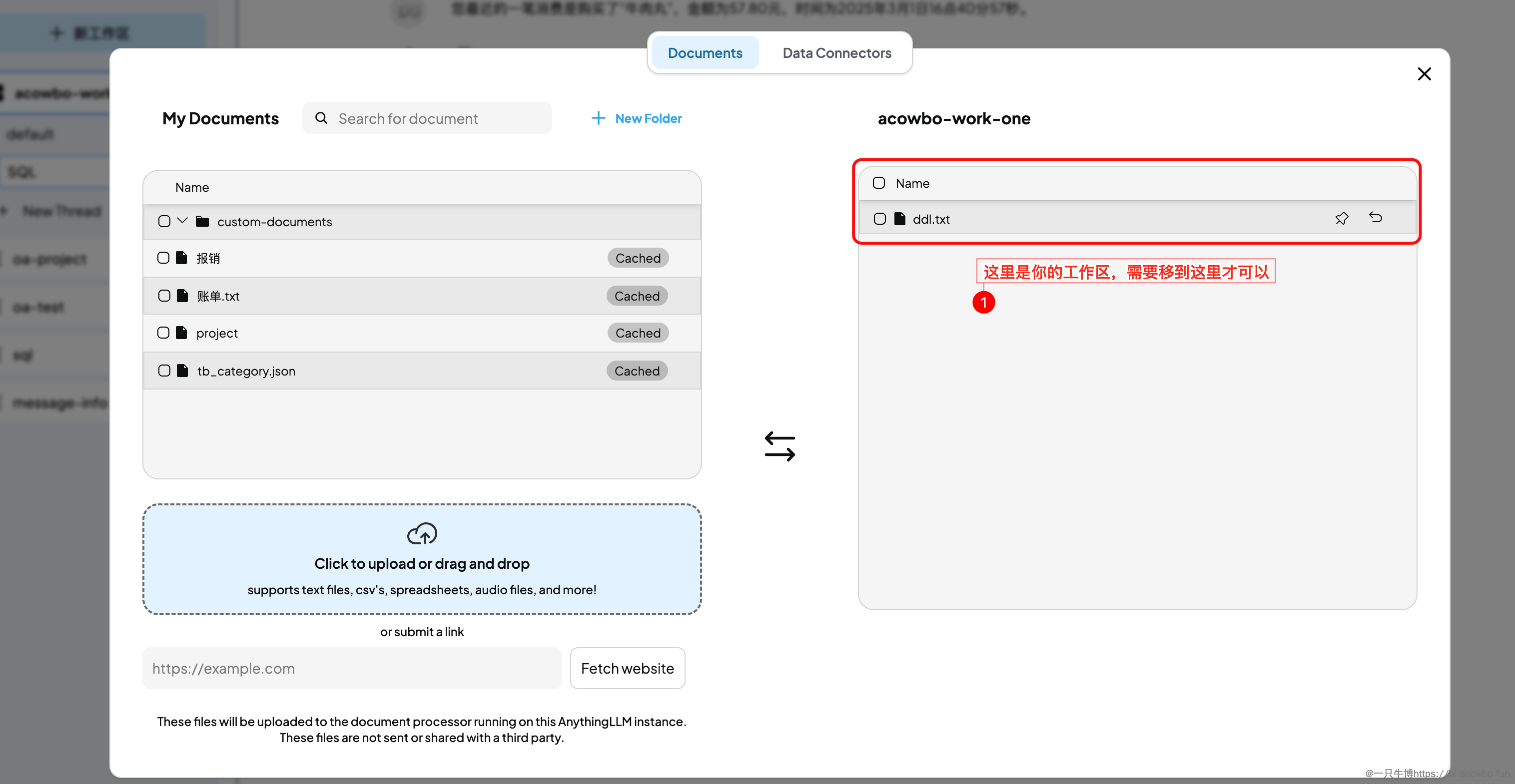
界面左侧是文档库,右侧是当前工作区。把 ddl.txt 移到工作区后,系统会自动对文档进行向量化处理,建立语义索引。底部有一行提示:「These files are not sent or shared with a third party」,再次确认了数据的安全性。
开始自然语言问答
一切准备就绪,现在可以用自然语言向 AI 提问了!
比如我想查询「日用消费最高的一次」,直接在对话框输入这句话,AI 就会根据投喂的 DDL 信息,自动生成对应的 SQL:

AI 生成的 SQL:
SELECT tb_bill.id AS billId, tb_bill.amount AS amount, tb_bill.name AS name, tb_bill.create_time AS createTime
FROM tb_bill
JOIN tb_category ON tb_bill.category_id = tb_category.id
WHERE tb_category.type = 0 AND tb_bill.is_deleted = 0 AND tb_category.name LIKE '%日用%'
ORDER BY tb_bill.amount DESC LIMIT 1;
可以看到 AI 准确理解了我的意图:
- 关联了 tb_bill 和 tb_category 两张表
- 筛选条件包括:支出类型(type=0)、未删除(is_deleted=0)、分类名包含"日用"
- 按金额降序排列,取第一条
底部还显示了引用来源(ddl.txt),说明 AI 确实是基于我投喂的表结构信息来生成 SQL 的。响应时间 3.6 秒,速度 23.29 tok/s,在本地 7B 模型上这个表现相当不错了。
使用技巧
在实际使用过程中,我总结了几个提升效果的技巧:
DDL 注释要详细:字段注释、表注释写得越清楚,AI 理解得越准确。比如 is_deleted TINYINT COMMENT '是否删除:0-否,1-是' 比单纯的 is_deleted TINYINT 效果好很多。
提问要具体:「查询最近一周的订单」比「查订单」效果好。如果 AI 生成的 SQL 不对,可以补充更多上下文信息。
复杂查询分步来:对于特别复杂的查询,可以先让 AI 生成基础 SQL,再逐步添加条件和优化。
定期更新 DDL:如果数据库结构有变化,记得更新工作区中的 DDL 文件,保持知识库的准确性。
总结
整套方案从安装到配置完成大约只需要 30 分钟,之后就可以享受自然语言生成 SQL 的便利了。Ollama + Qwen2.5 + Anything LLM 的组合在本地运行完全够用,7B 模型对于日常的 SQL 生成任务绑绑有余。最关键的是数据全程不出本机,对于处理敏感业务数据的场景来说,这种本地化方案是目前最稳妥的选择。
