
vLLM 重要更新

vLLM 作为目前最受欢迎的开源 LLM 推理和服务框架,近期发布了一系列重大更新。本文将详细解读 vLLM 团队在2025年12月密集发布的六项核心技术进展,涵盖路由负载均衡、推测解码、幻觉检测、多模态服务、语义路由及大规模部署等关键领域。
目录
- vLLM Router:高性能智能负载均衡器
- Speculators v0.3.0:推测解码训练支持
- HaluGate:实时幻觉检测管道
- 编码器解耦(EPD):多模态模型服务优化
- AMD × vLLM 语义路由器:混合模型智能协作
- 大规模服务:DeepSeek @ 2.2k tok/s/H200
1. vLLM Router:高性能智能负载均衡器
发布日期:2025年12月13日
在大规模生产环境中,高效管理请求分发至多个模型副本至关重要。传统负载均衡器往往缺乏对 LLM 推理有状态特性(如 KV 缓存)的感知,无法处理复杂的服务模式(如 Prefill/Decode 分离)。
核心架构
vLLM Router 是一款专为 vLLM 打造的高性能、轻量级负载均衡器,采用 Rust 构建以实现最小开销。它作为智能、状态感知的负载均衡器,位于客户端和 vLLM 工作节点集群之间。
 vLLM Router 架构示意图
vLLM Router 架构示意图
智能负载均衡策略
vLLM Router 提供多种负载均衡算法:
策略 | 特点 |
|---|---|
一致性哈希 | 确保相同路由键的请求"粘性"路由到同一工作节点,最大化 KV 缓存复用 |
Power of Two | 低开销随机选择策略,提供优秀的负载分配 |
轮询 & 随机 | 无状态负载分配的标准策略 |
原生 Prefill/Decode 分离支持
Router 作为 vLLM 最先进服务架构的编排层:
- 智能将新请求路由到 Prefill 工作组
- 完成后,将请求状态定向到适当的 Decode 工作节点进行 token 生成
- 支持 NIXL 和 NCCL-based 分离后端
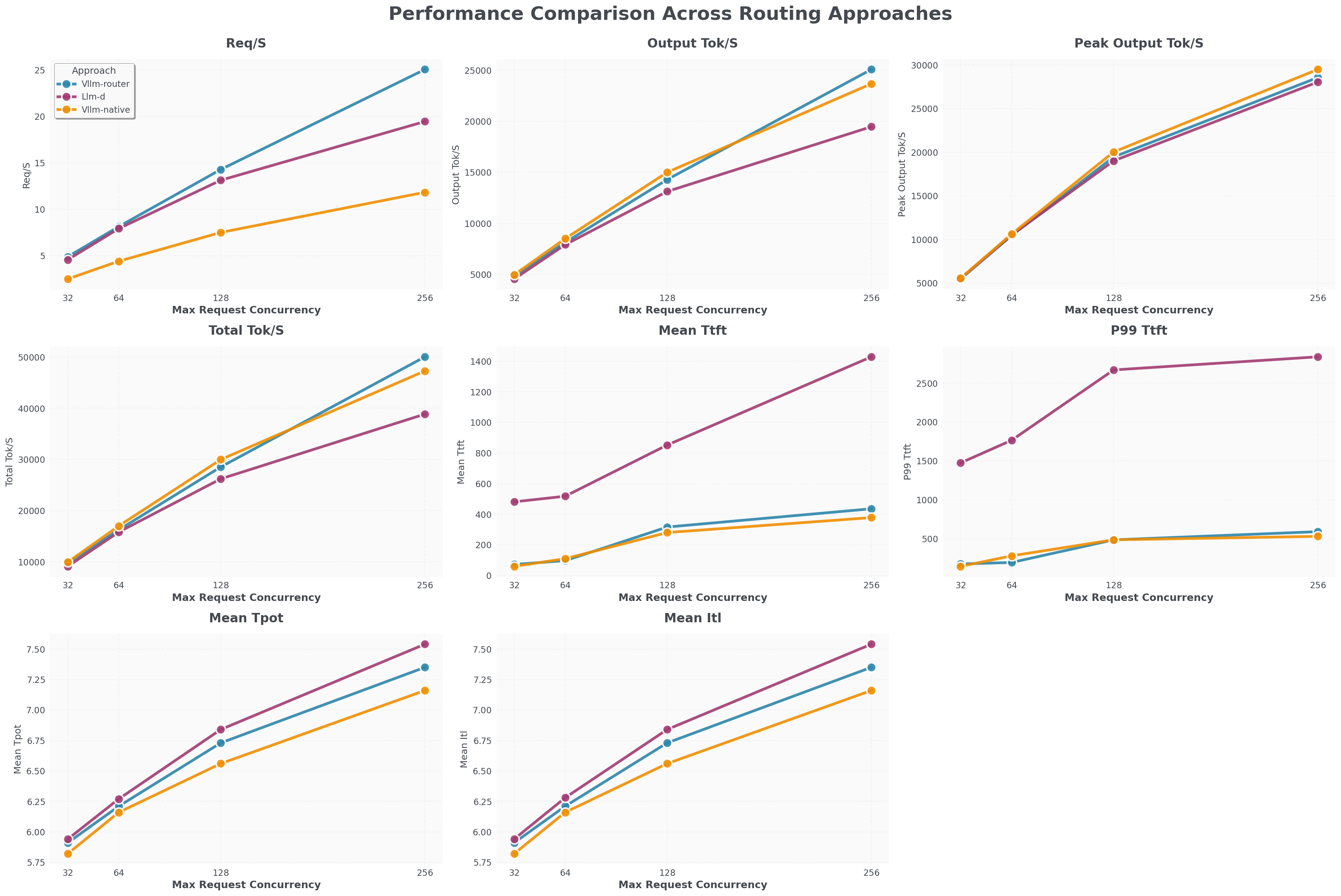
性能基准测试
 DeepSeek V3 基准测试
DeepSeek V3 基准测试
Llama 3.1 8B(8 Prefill pods + 8 Decode pods):
- vLLM Router 吞吐量比 llm-d 高 25%,比 K8s 原生负载均衡器高 100%
- TTFT 比 llm-d 快 1200ms
DeepSeek V3(TP8 配置):
- 吞吐量比 K8s 原生负载均衡器高 100%
- TTFT 比 llm-d 和 K8s 原生快 2000ms
2. Speculators v0.3.0:推测解码训练支持
发布日期:2025年12月13日
贡献团队:Red Hat AI 模型优化团队
什么是推测解码?
推测解码允许 LLM 在单次前向传播中生成多个 token。它利用一个小型"草稿"模型与完整的"验证"模型配合工作:
 Eagle3 架构
Eagle3 架构
工作原理:
- 草稿模型快速自回归预测多个 token
- 验证模型并行处理这些 token
- 验证器决定是否接受每个 token
- 被拒绝的 token 及后续序列将被丢弃
优势:
- 最终响应与仅使用验证模型完全一致,无性能降级
- 验证模型可并行生成多个 token
- 草稿模型开销极小
端到端训练支持
Speculators v0.3.0 提供 Eagle3 草稿模型的完整训练支持:
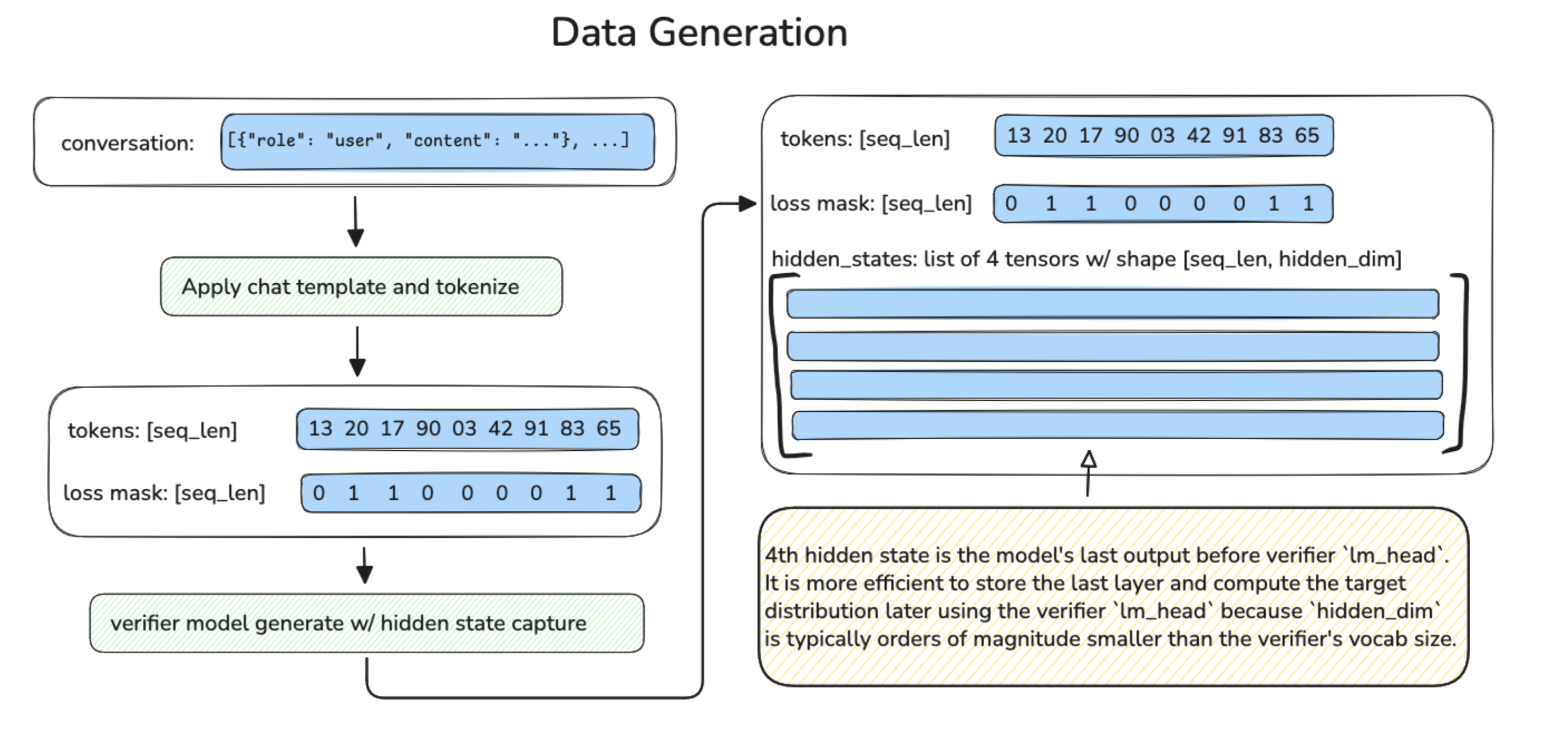 数据生成流程
数据生成流程
训练流程包括:
- 使用 vLLM 的离线数据生成
- 单层和多层草稿模型训练
- MoE 和非 MoE 验证器支持
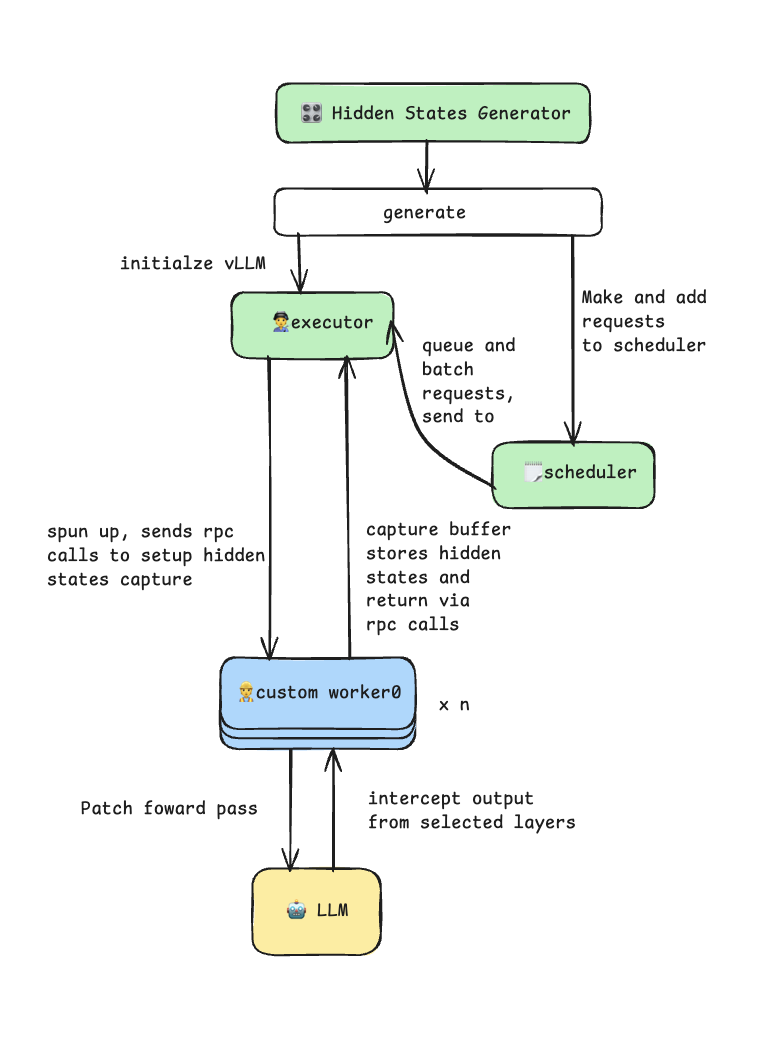 隐状态生成器
隐状态生成器
一键部署
训练完成后,只需简单命令即可在 vLLM 中运行:
支持的模型:
- Llama (3.1, 3.2, 3.3): 8B 到 70B 参数
- Qwen3: 8B, 14B, 32B 参数
- Qwen3 MoE: 235B-A22B 参数
- GPT-OSS: 20B, 120B 参数
- 多模态:Llama 4 视觉-语言模型
3. HaluGate:实时幻觉检测管道
发布日期:2025年12月14日
问题背景
幻觉已成为 LLM 生产部署的最大障碍。跨行业场景中(法律、医疗、金融、客服),模型会生成看似权威但经不起推敲的虚假内容。
 幻觉问题示例
幻觉问题示例
典型场景:
- 工具返回正确数据:
{"built": "1887-1889", "height": "330 meters"} - LLM 响应却是:"埃菲尔铁塔建于1950年,高500米"
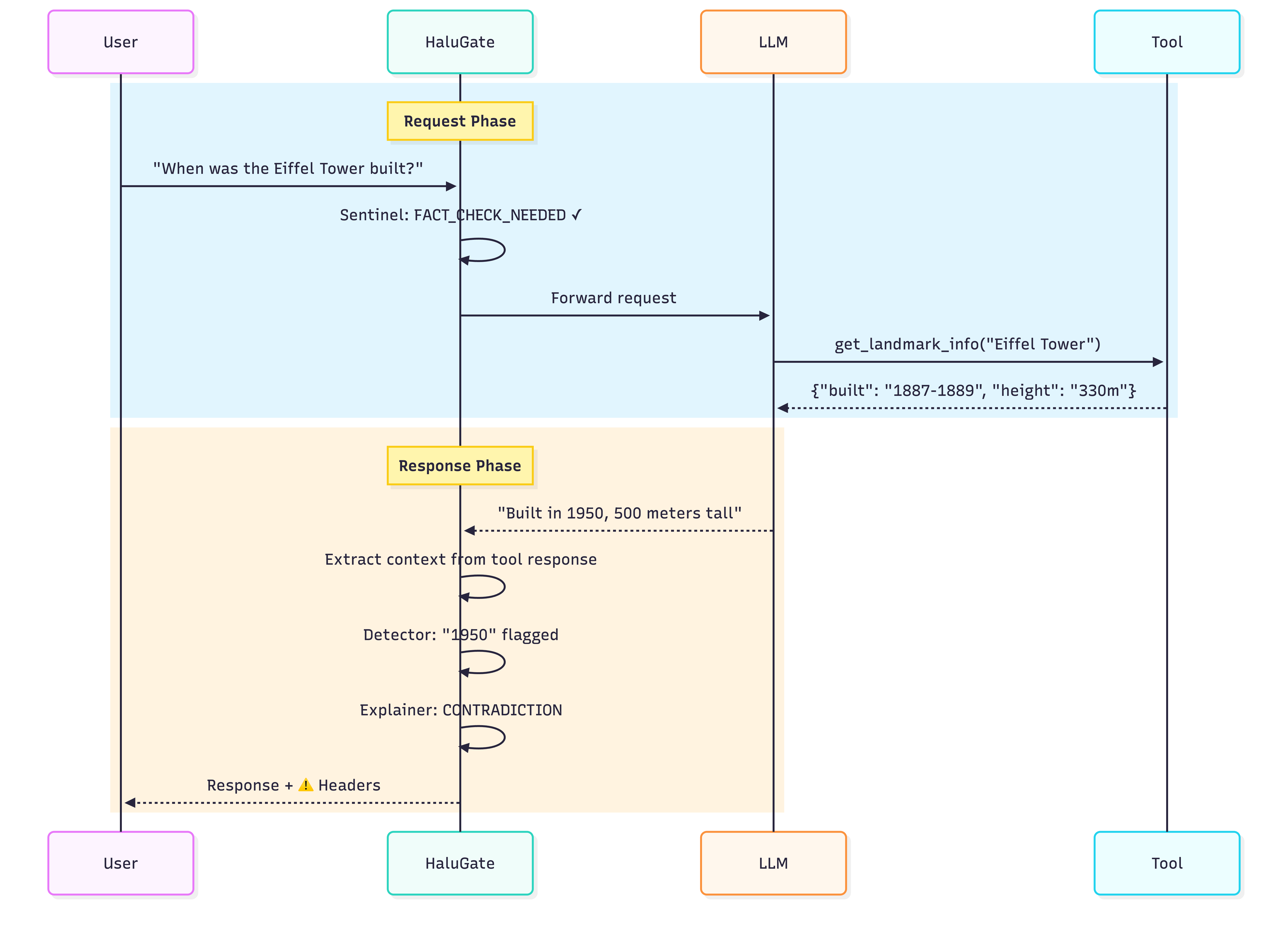
HaluGate 两阶段检测管道
 HaluGate 架构
HaluGate 架构
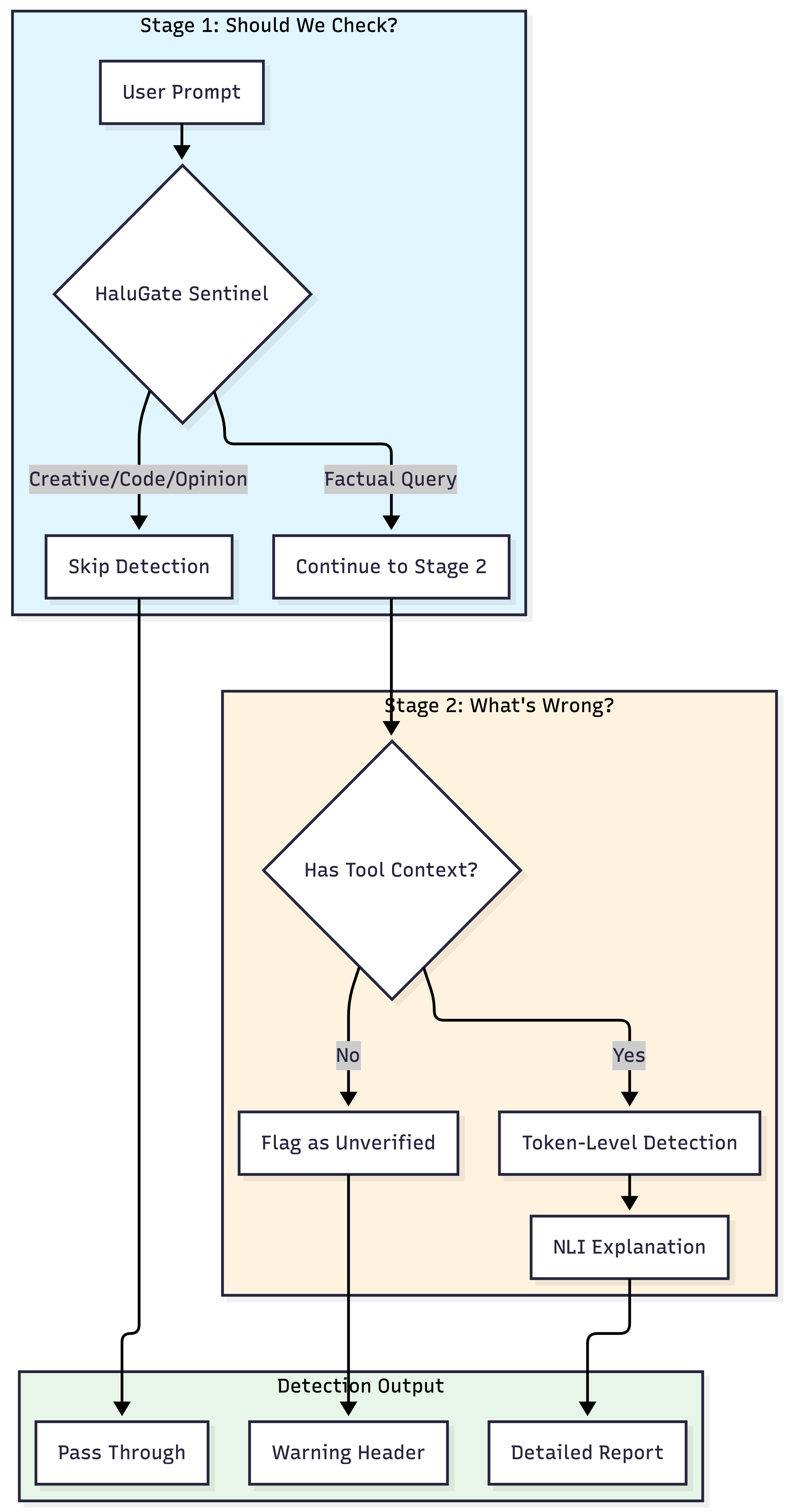
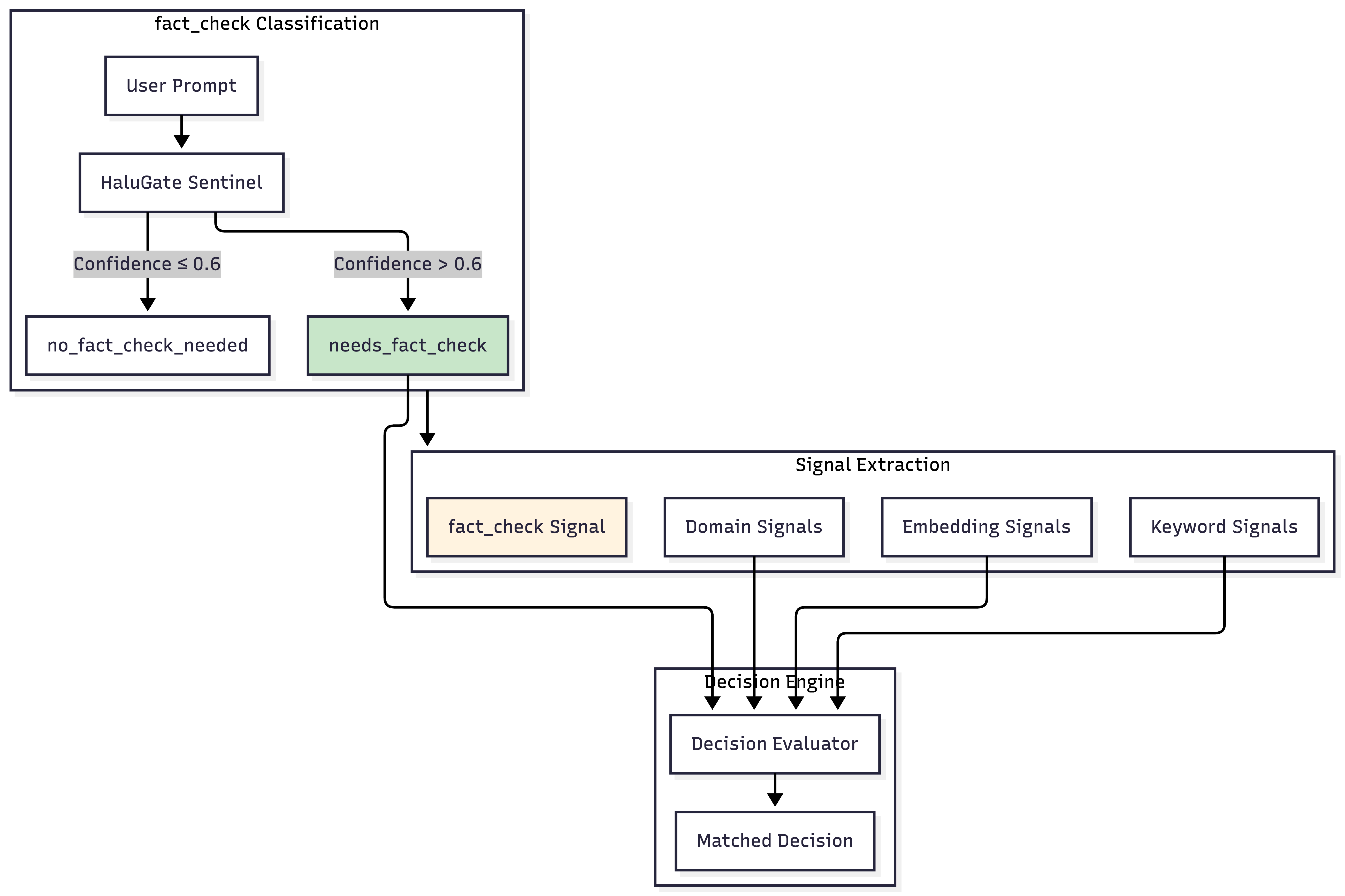
阶段一:HaluGate Sentinel(提示分类)
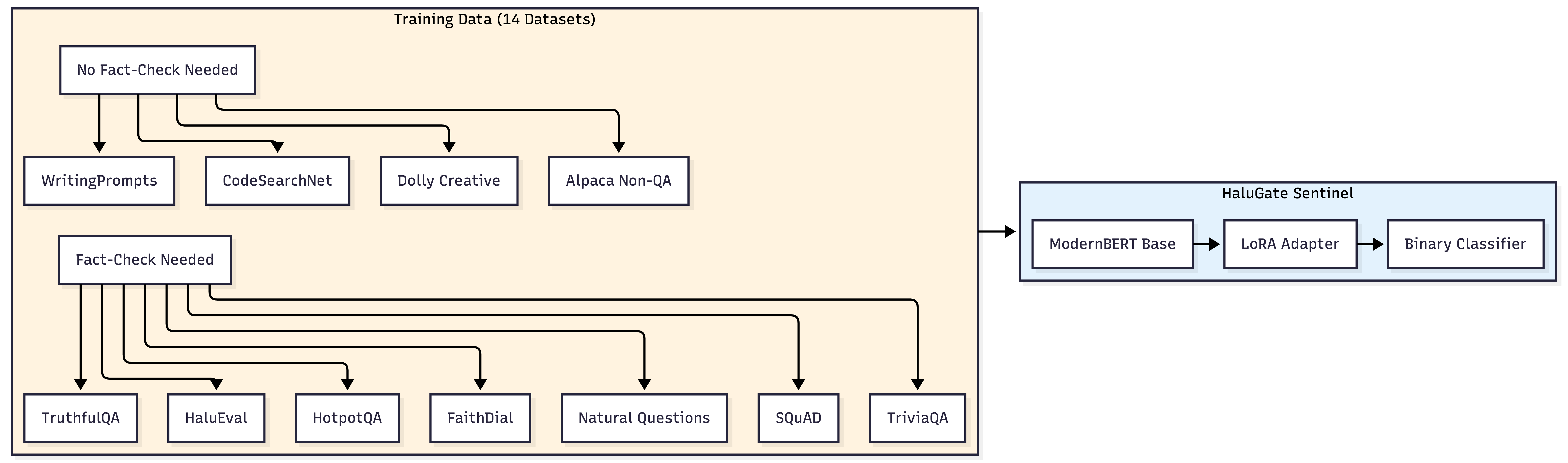
不是每个查询都需要幻觉检测。HaluGate Sentinel 是基于 ModernBERT 的分类器,判断提示是否需要事实验证:
 Sentinel 工作流程
Sentinel 工作流程
- 需要验证:QA、真实性测试、幻觉基准、信息查询对话
- 无需验证:创意写作、代码、观点/指令类
准确率达 **96.4%**,推理延迟仅 ~12ms。
阶段二:Token 级别检测 + NLI 解释
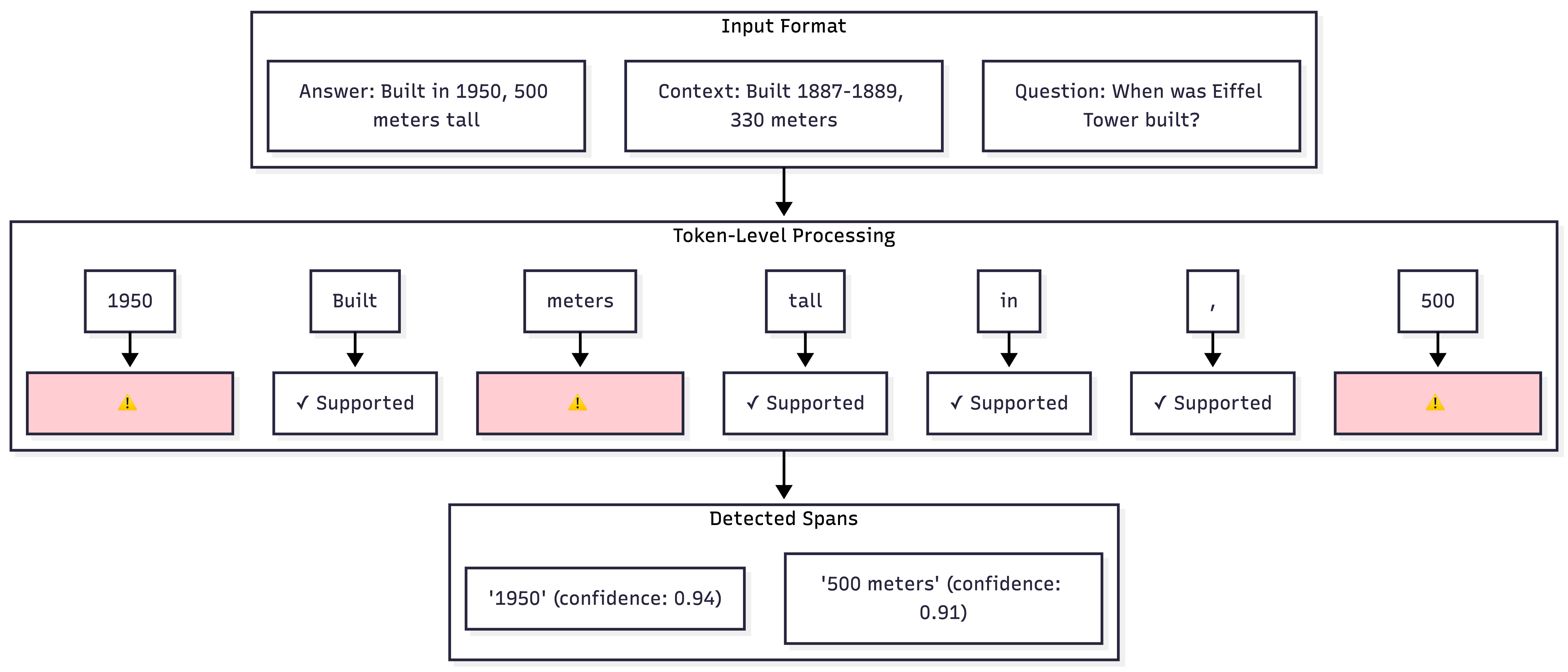 Token级检测
Token级检测
与句子级分类器不同,token 级检测能精确识别哪些 token 不受上下文支持:
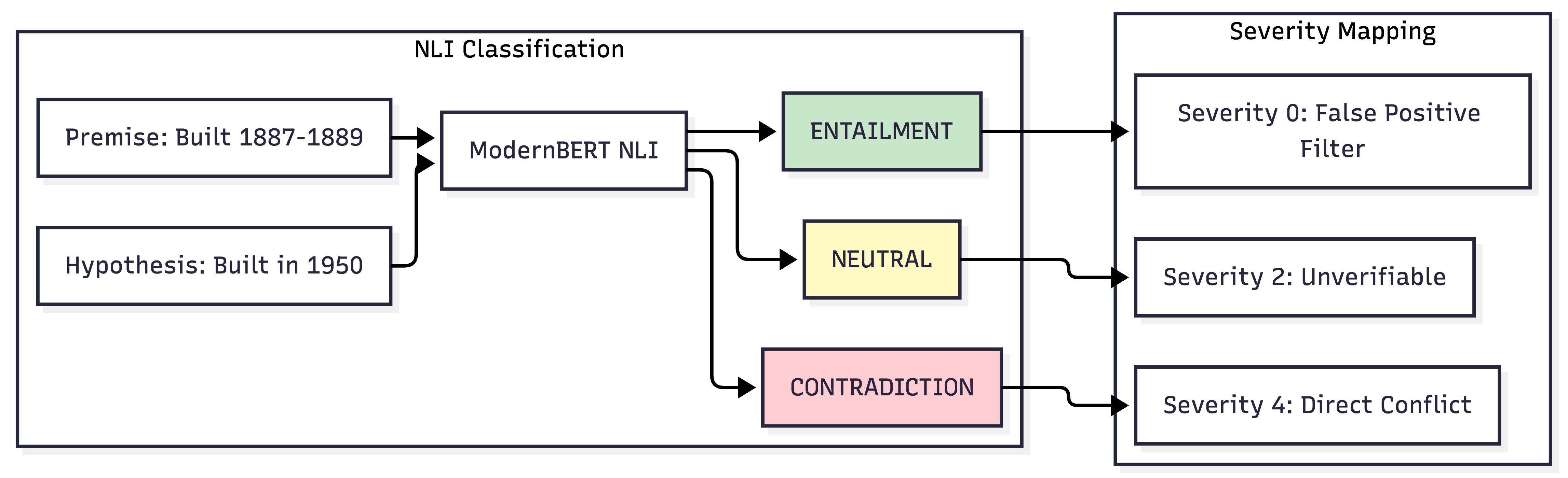 NLI 解释层
NLI 解释层
为什么采用集成方法? Token 级检测单独仅达 59% F1;两阶段方法将平庸的检测器转化为可操作系统:LettuceDetect 提供召回率,NLI 提供精度和可解释性。
性能表现
 延迟对比
延迟对比
方法 | 延迟 | 成本 |
|---|---|---|
LLM-as-Judge (GPT-4) | 500-3000ms | $0.03/请求 |
HaluGate | 50-125ms | 固定 GPU 成本 |
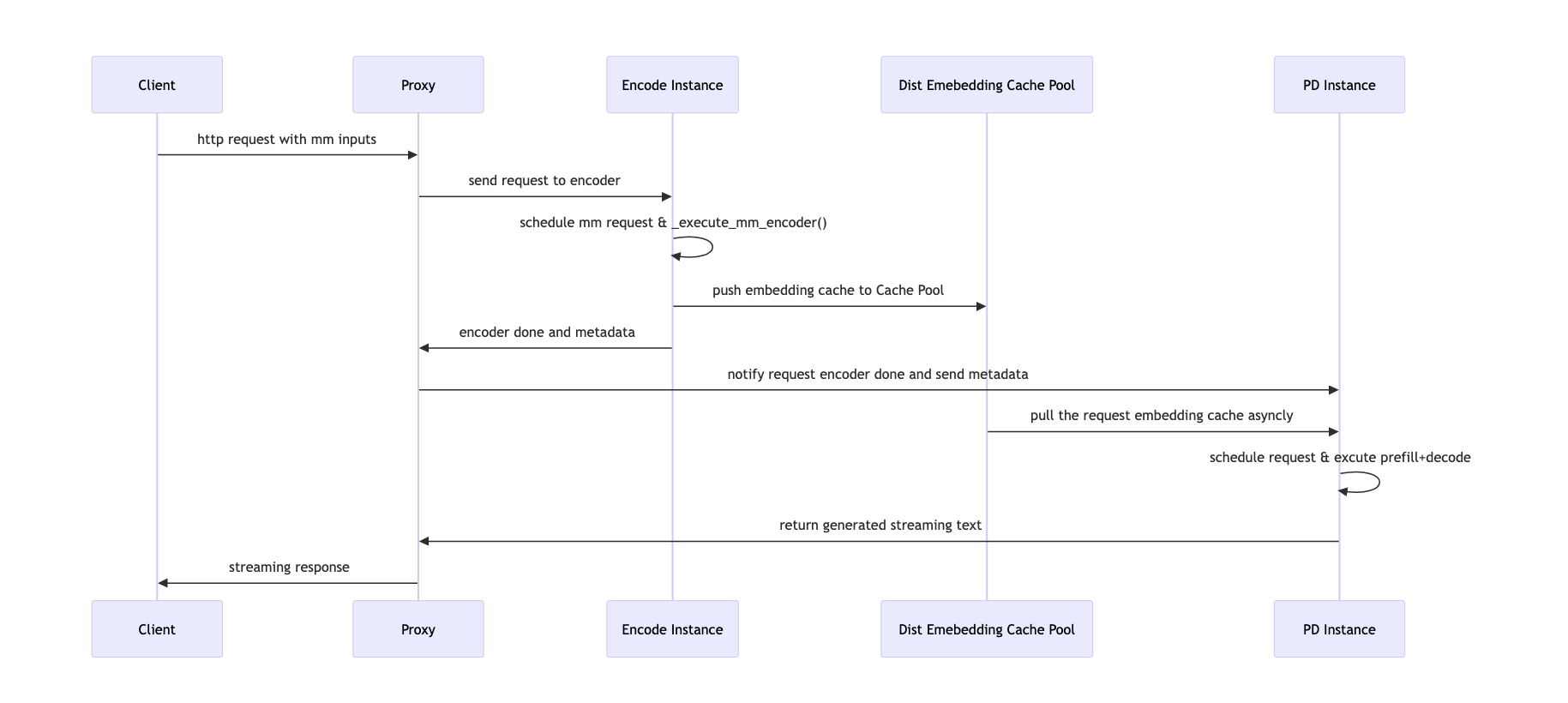
4. 编码器解耦(EPD):多模态模型服务优化
发布日期:2025年12月15日
贡献团队:vLLM 多模态工作流组
问题动机
现代大型多模态模型(LMM)引入了独特的服务瓶颈:在任何文本生成开始之前,所有图像必须由视觉编码器(如 ViT)处理。
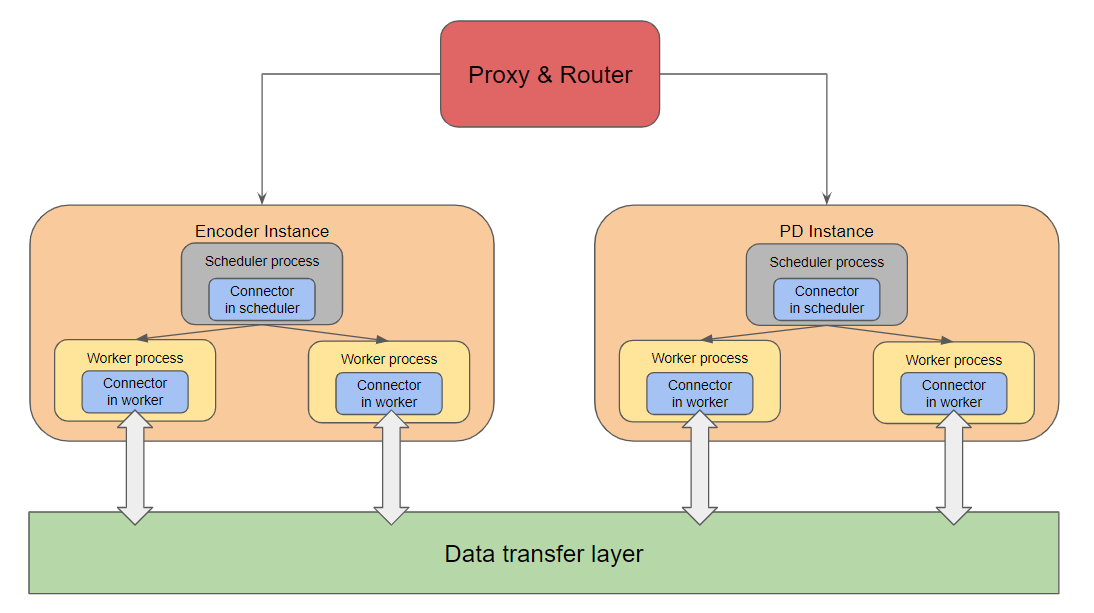 EPD 架构图
EPD 架构图
传统方案的问题:
- 编码器在 GPU 上运行时,Decode 阶段必须等待
- 图像密集型请求会阻塞纯文本请求
- 编码器利用率不均导致资源浪费
解耦方案的三大优势
 工作流程图
工作流程图
1. 流水线执行与消除干扰
- 请求 N 的编码可在请求 N-1 预填充/解码时运行
- 纯文本请求完全绕过编码器
- 系统变为流水线并行,提升吞吐量
2. 独立细粒度扩展
- 根据多模态图像量扩展编码器 GPU
- 根据请求率和输出长度扩展 Prefill/Decode GPU
3. 编码器输出缓存与复用
- 常用图像(logo、图表、产品图)的嵌入只计算一次
- 缓存命中的请求编码成本为零,直接降低 TTFT
性能测试结果
测试环境:4×A100 80G,模型:Qwen3-VL-4B-Instruct
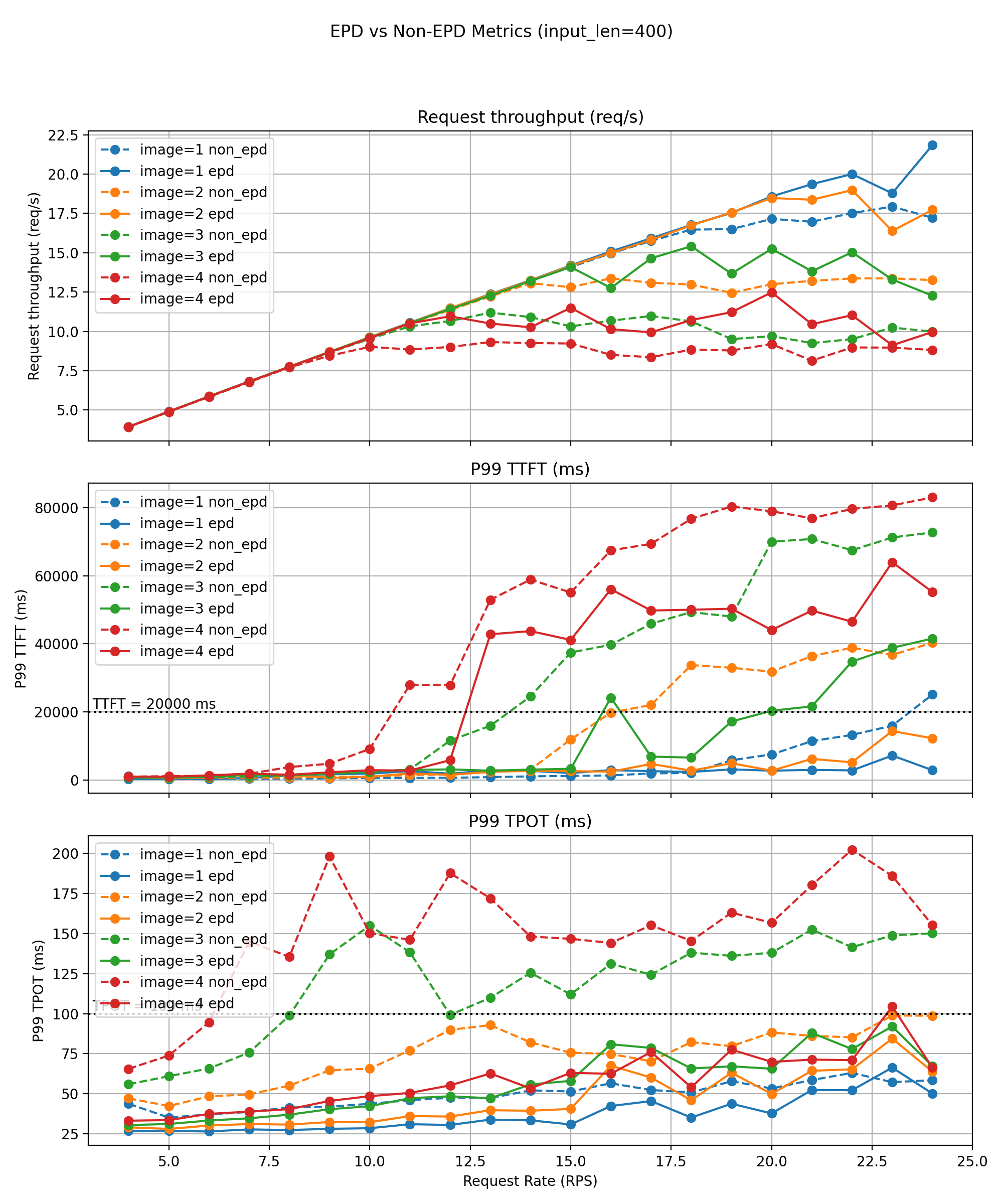 短文本工作负载
短文本工作负载
短文本工作负载(~400 tokens):
- 单图:goodput 小幅提升(23 → 24 QPS)
- 四图:goodput 翻倍(6 → 12 QPS)
- P99 TTFT/TPOT 通常降低 20-50%
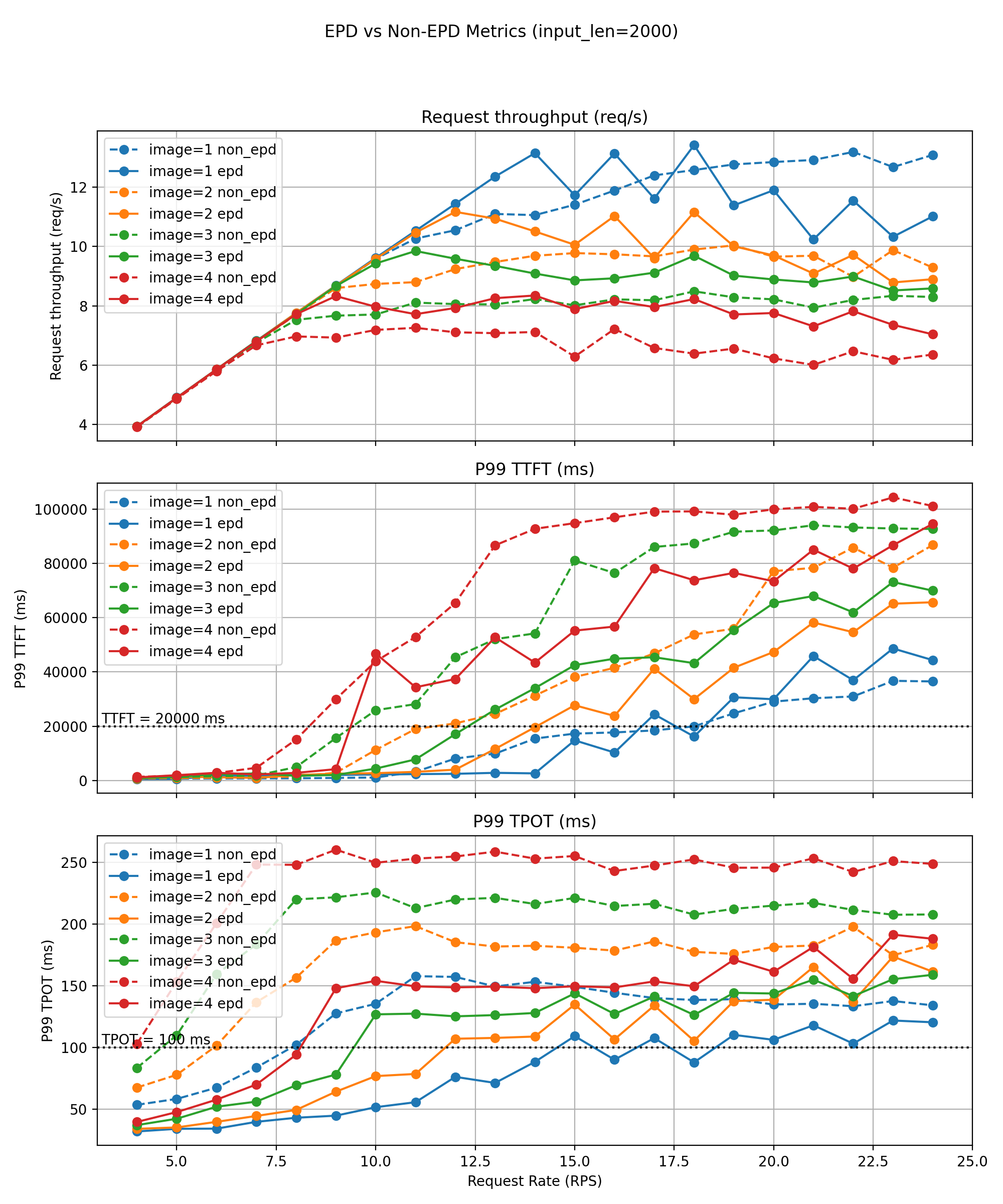 长文本工作负载
长文本工作负载
长文本工作负载(~2000 tokens):
- EPD 保持 18/11/9/8 QPS vs 基线 8/4/4/4 QPS — 2-2.5倍 goodput
- 有效解码吞吐增加 10-30%
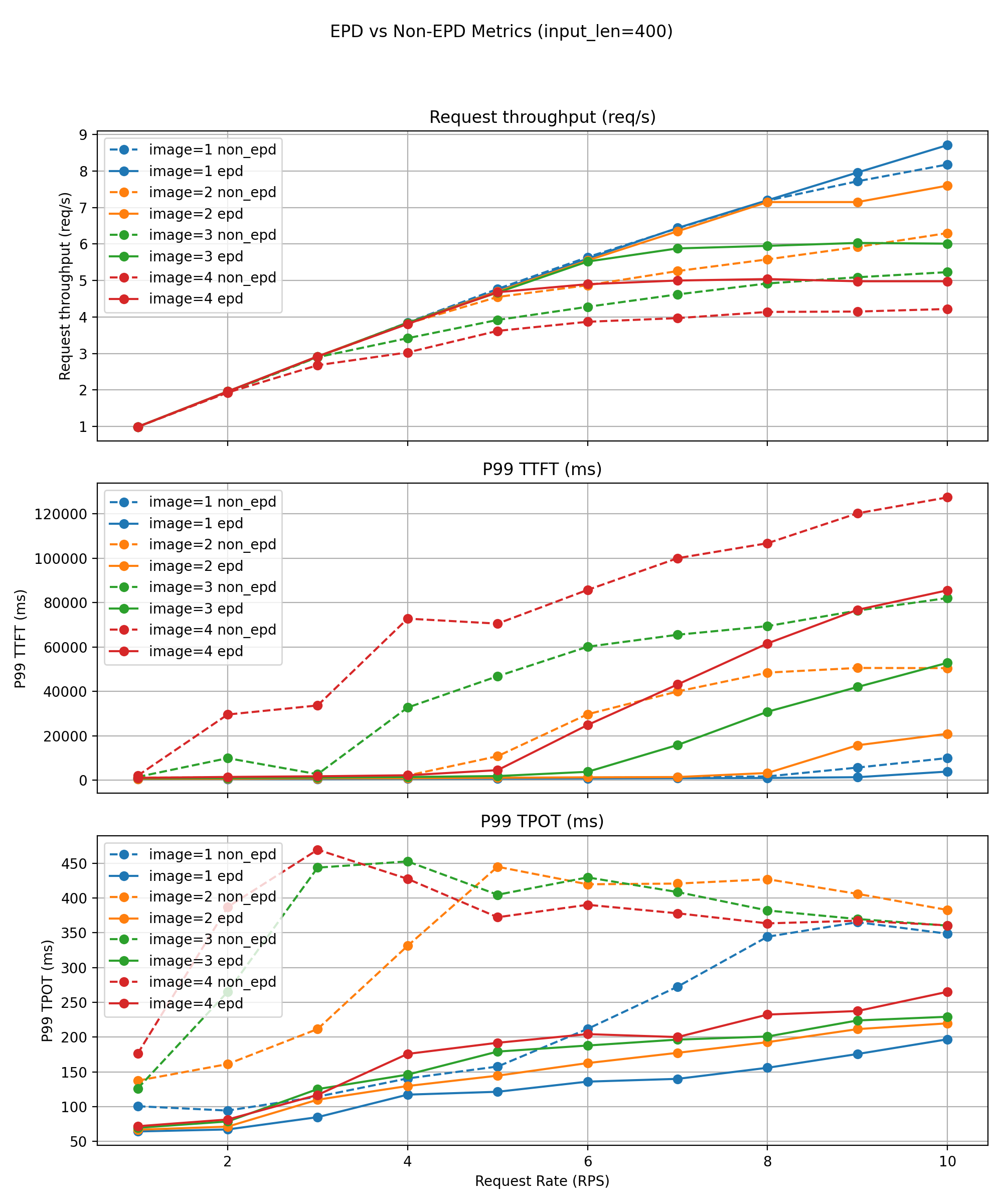 NPU 测试结果
NPU 测试结果
硬件可移植性: 在华为昇腾 NPU(4×Ascend 910B 32G)上也展现了相同的架构级收益。
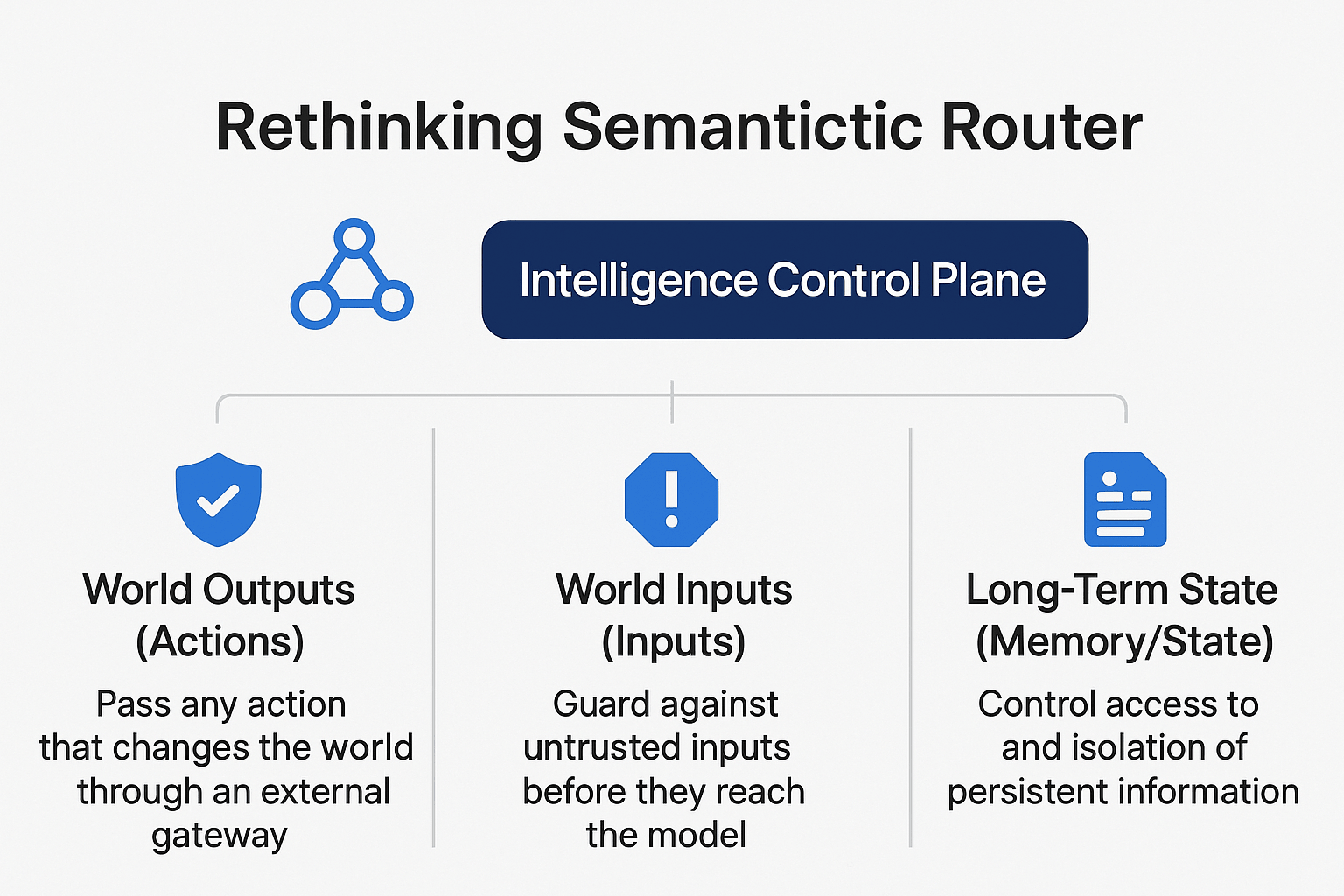
5. AMD × vLLM 语义路由器:混合模型智能协作
发布日期:2025年12月16日
贡献团队:AMD 与 vLLM 语义路由器团队
从单模型到混合模型的转变
 混合模型架构
混合模型架构
在混合模型(Mixture-of-Models)世界中,企业 AI 栈通常包括:
- 路由 SLM:分类、路由和策略执行
- 多个 LLM 和领域专用模型(代码、金融、医疗、法律)
- 工具、RAG 管道、向量搜索和业务系统
VSR 核心能力
 VSR 核心功能
VSR 核心功能
1. 基于信号的 Multi-LoRA 路由
路由策略 | 描述 |
|---|---|
关键词路由 | 快速确定性的模式匹配 |
领域分类 | 意图感知的适配器选择 |
嵌入语义相似度 | 基于语义理解的细粒度路由 |
事实检查路由 | 高风险查询路由到专门验证管道 |
2. 跨实例智能
- Response API:集中存储实现有状态多轮对话
- 语义缓存:通过跨实例向量匹配显著减少 token 使用
3. 企业级护栏
 企业护栏
企业护栏
- PII 检测:防止敏感信息泄露
- 越狱防护:阻止恶意提示注入
- 幻觉检测:验证关键领域的响应可靠性
- 超级对齐:确保 AI 系统在向 AGI 能力扩展时保持与人类价值观对齐
AMD GPU 部署路径
 部署路径
部署路径
两种部署方式:
- 基于 vLLM 的推理:在 AMD GPU 上运行完整推理
- 轻量级 ONNX 路由:仅路由逻辑,最小化资源占用
6. 大规模服务:DeepSeek @ 2.2k tok/s/H200
发布日期:2025年12月17日
V1 引擎完成迁移
在 v0.11.0 中,vLLM V0 引擎的最后代码被移除,标志着向改进的 V1 引擎架构的完全迁移。这一成就离不开 vLLM 社区 1,969 位贡献者的努力。
性能突破
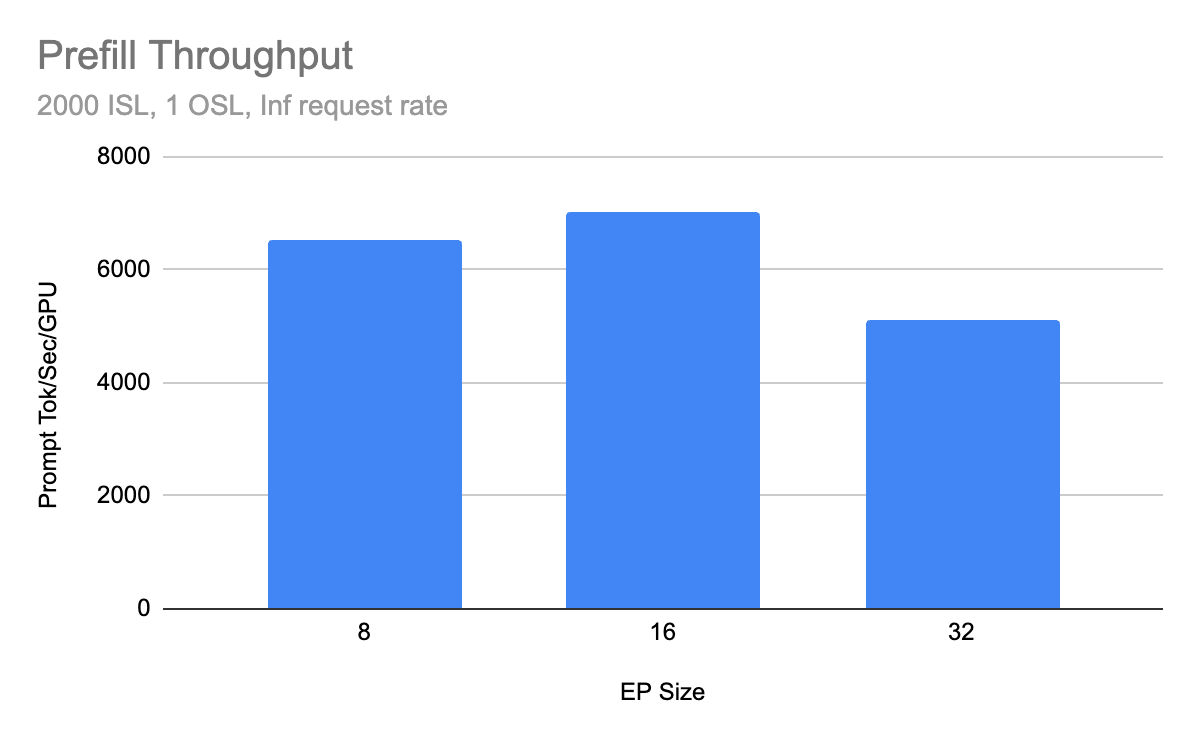 Prefill 吞吐
Prefill 吞吐
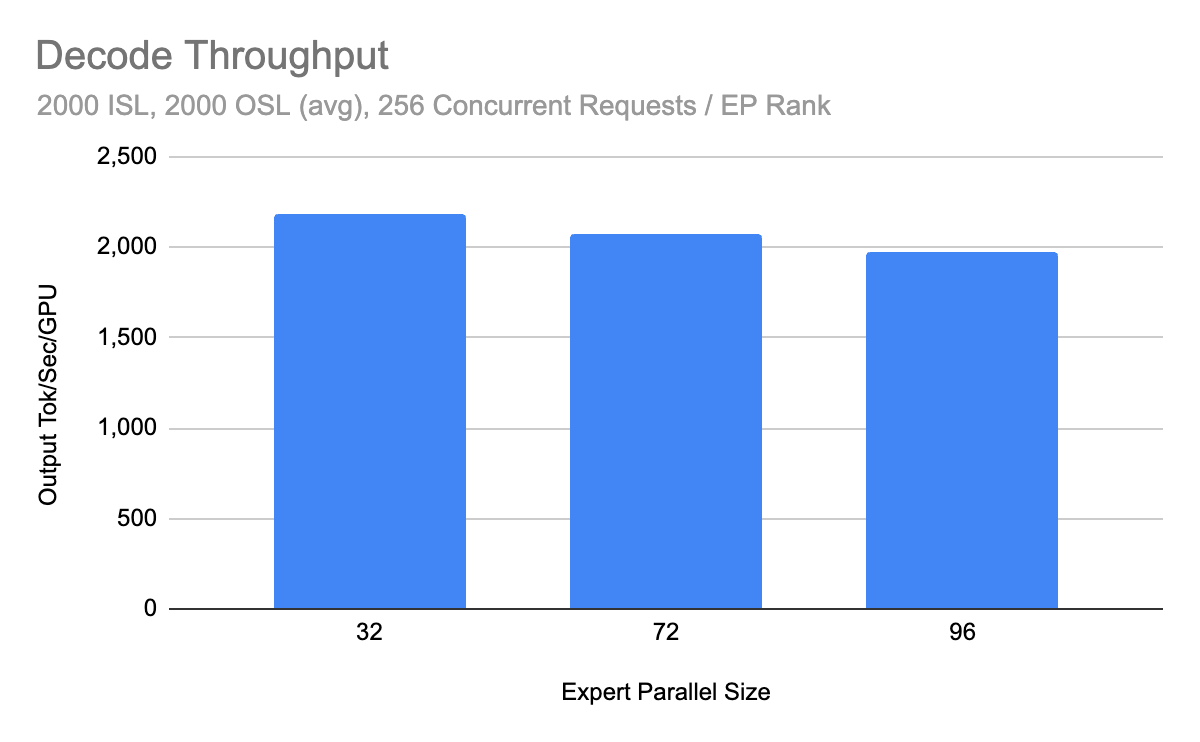 Decode 吞吐
Decode 吞吐
社区基准测试(Coreweave H200 集群,Infiniband + ConnectX-7 NICs)显示:
- 生产级多节点部署达到 2.2k tokens/s 每 GPU
- 相比早期 1.5k tokens/s 有显著提升
核心组件
Wide-EP(专家并行)
 Wide-EP Token 路由
Wide-EP Token 路由
DeepSeek-V3 部署的两大考虑:
- 稀疏专家激活:DeepSeek-R1 每次前向传播仅激活 37B/671B 参数
- KV 缓存管理:张量并行对 MLA 注意力架构并非最优
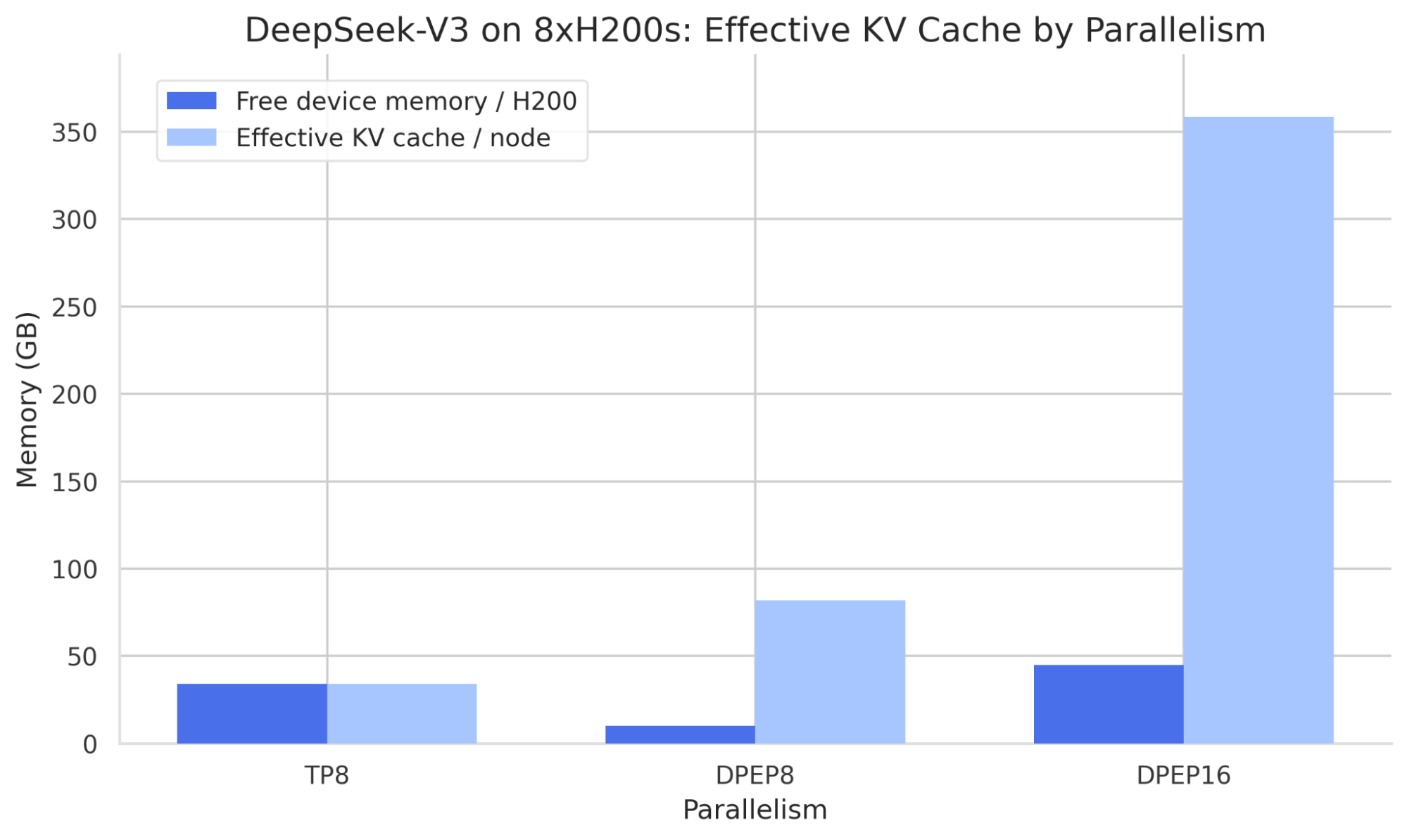 KV 缓存对比
KV 缓存对比
Wide-EP 结合 EP 与数据并行(DP),最大化 MLA 架构的 KV 缓存效率。
双批次重叠(DBO)
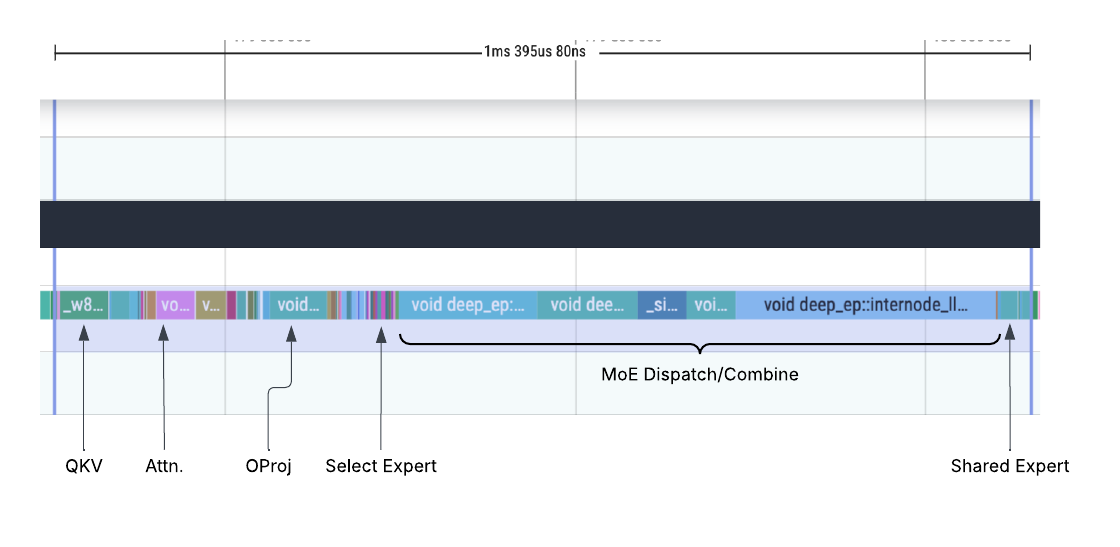 DBO 优化前
DBO 优化前
优化前: MoE 调度/组合部分的通信开销占用大量时间
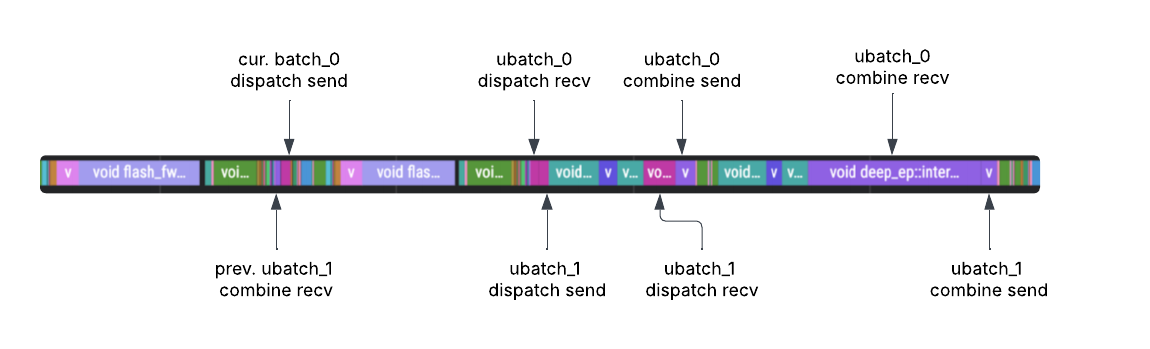 DBO 优化后
DBO 优化后
优化后: 微批次工作线程交替执行,重叠计算与通信,提升 GPU 利用率
专家并行负载均衡(EPLB)
 EPLB 动画
EPLB 动画
MoE 专家层在训练时针对平衡负载优化,但推理时实际工作负载可能导致不均衡。EPLB 动态调整逻辑到物理专家的映射。
分离式服务(Disaggregated Serving)
 分离式服务
分离式服务
由于专家分布在各 rank 上,单个计算密集型 prefill 请求可能延迟整个 EP 组的前向传播。分离式服务放大了解耦的收益。
部署方案
方案 | 特点 |
|---|---|
| Kubernetes 原生分布式推理服务栈 |
| 高吞吐低延迟生产部署,支持 KV 感知路由 |
| 模块化部署,无缝集成 Ray 生态 |
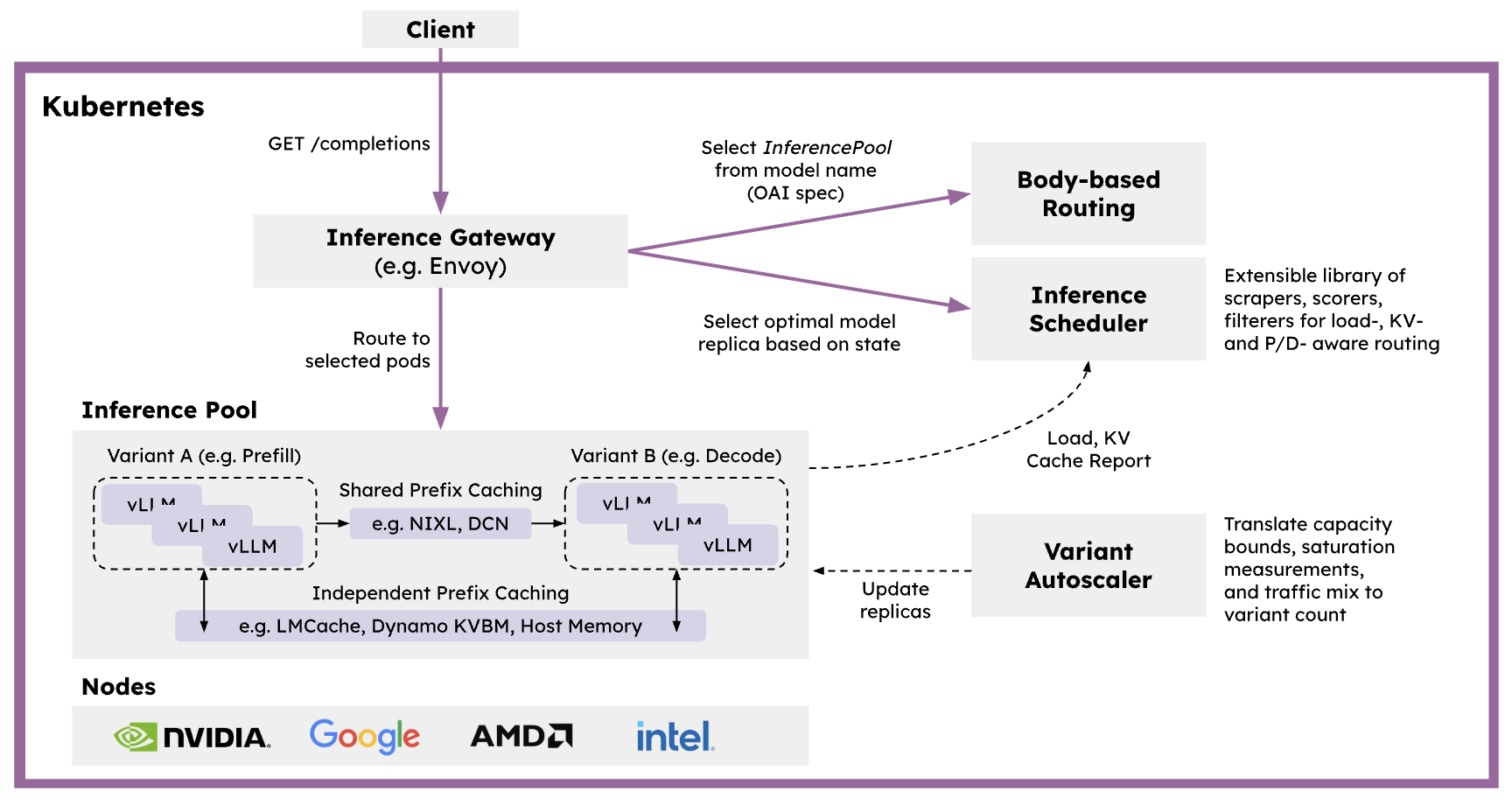 llm-d
llm-d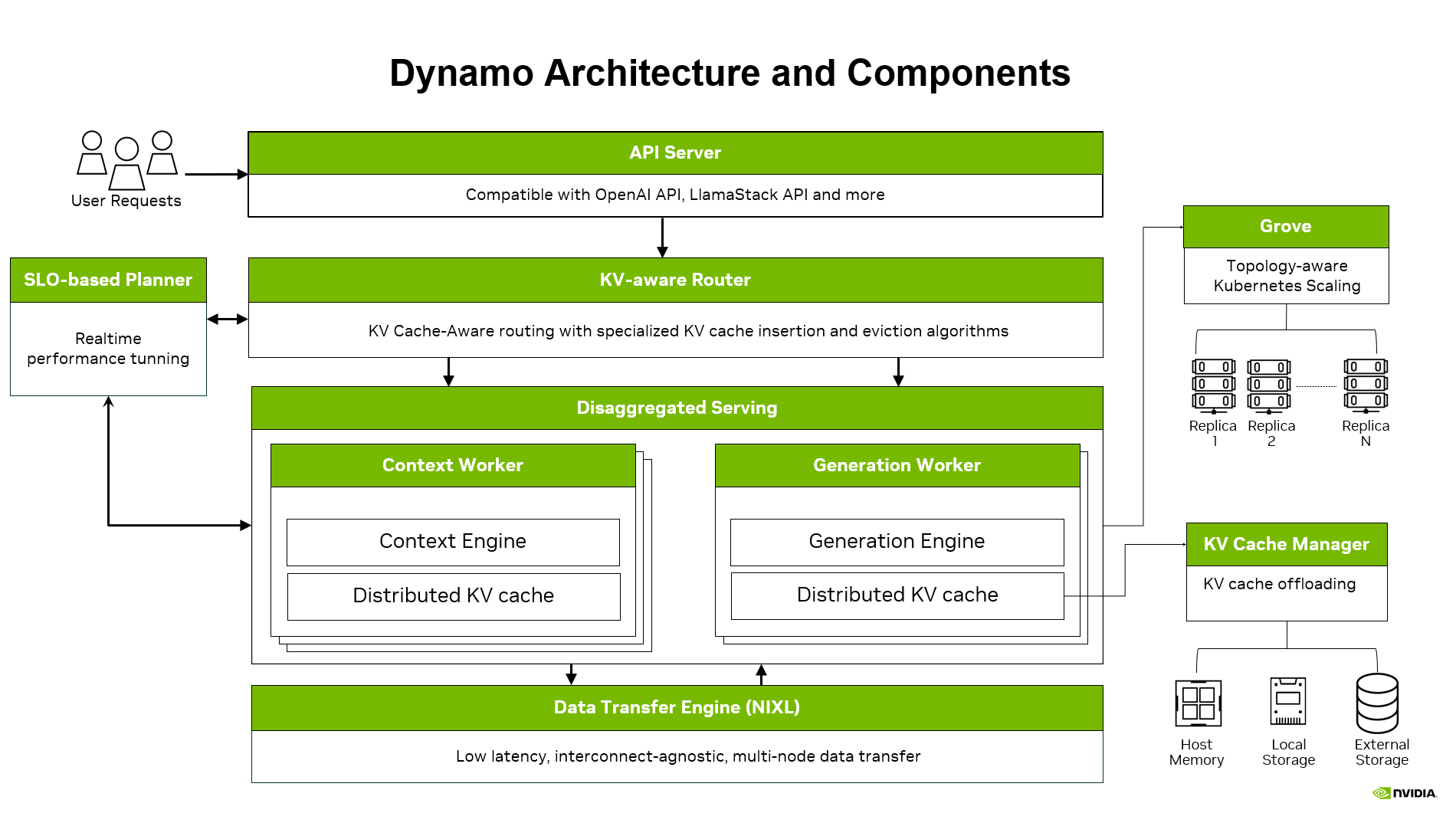 Dynamo
Dynamo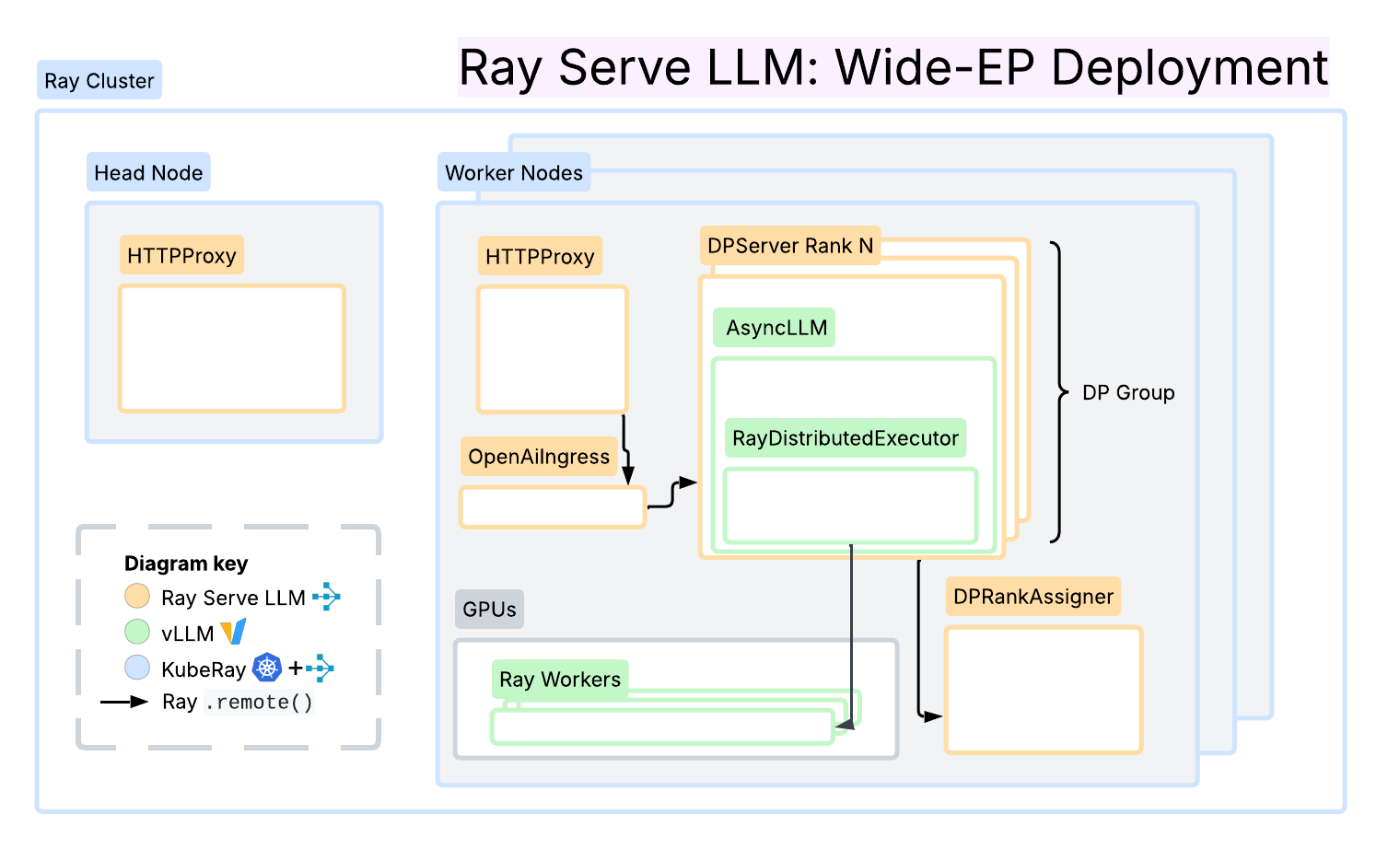 Ray Serve LLM
Ray Serve LLM总结
vLLM 在2025年12月的更新展现了其在大规模 LLM 推理领域的持续创新:
- vLLM Router 解决了生产环境中的智能负载均衡问题
- Speculators v0.3.0 让推测解码从研究走向生产
- HaluGate 提供了实时、低延迟的幻觉检测能力
- EPD 通过编码器解耦优化多模态模型服务
- AMD × VSR 构建了混合模型时代的智能控制面
- 大规模服务优化 实现了 2.2k tok/s/H200 的突破性性能
这些技术进展共同推动 vLLM 成为企业级 AI 基础设施的核心组件,为构建可扩展、可信赖、高性能的 AI 应用提供了坚实基础。
