
顶尖 AI 视觉能力不及 3 岁儿童,UniPat AI 发布 BabyVision 评测集揭示多模态模型“硬伤”

多模态大模型
具身智能
UniPat AI 联合红杉中国 xbench 团队及多家高校研究员,发布了全新的多模态理解评测集 BabyVision。评测结果显示,在脱离语言辅助的“纯视觉”任务中,包括 Gemini 3-Pro、GPT-5.2 在内的全球顶尖模型表现普遍不及 3 岁儿童。
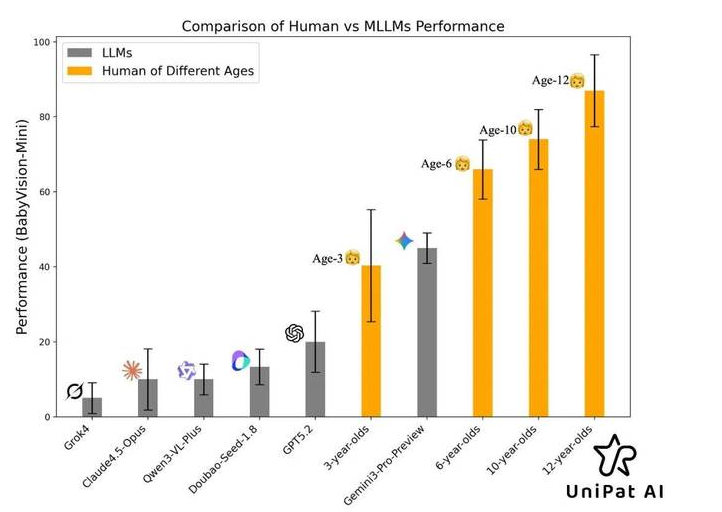
数据显示,在 BabyVision-Full 的 388 道纯视觉题目中,人类基准准确率达 94.1%,而目前最强的闭源模型 Gemini 3-Pro-Preview 仅为 49.7%,GPT-5.2 为 34.8%,最强开源模型 Qwen3-VL 则仅为 22.2%。研究指出,当前大模型过度依赖语言推理走“捷径”,一旦面对无法用文字描述的视觉追踪、空间感知及精细辨别任务,能力便大幅退化。UniPat AI 认为,补齐这一视觉地基是具身智能走向真实世界应用的关键。
原文链接
以上内容不代表本平台立场,仅供读者参考
