
如何让短视频与电商广告的制作成本暴跌 80%?Seedance 1.5 Pro 零成本制作AI视频


导语: Seedance 1.5 Pro 的出现,或许标志着 AI 视频正式进入了“有声电影”时代。它不再是一个单纯的视频生成器,而是一个原生的视听双模态引擎。这一次,我们不聊生成时长,只聊那个被行业忽视已久的命门:原生音画同步
一、 行业痛点:AI 视频的“弗兰肯斯坦”困境
在 Seedance 1.5 Pro 发布之前,AI 视频的生产流程不仅是割裂的,甚至是“反直觉”的。目前的行业标准工作流通常是:用 Midjourney 生成图 -> 用 Runway 生成动效 -> 用 Suno 生成背景乐 -> 用 ElevenLabs 生成配音 -> 最后在剪映里痛苦地对口型。这种“拼凑式”的管线导致了三个无法回避的硬伤:
- 时序错位: 爆炸的火光出现了,声音却慢了 0.5 秒;人物嘴巴闭上了,台词还没说完。这种“音画游离”感直接破坏了内容的真实性。
- 语义断层: 视频模型不懂声音的情绪,音频模型看不懂画面的张力。
- 后期成本黑洞: 为了修补上述问题,创作者需要花费比生成视频多 5 倍的时间在后期对齐上。
行业苦“哑巴视频”久矣。市场需要的不再是更长的视频,而是“生成即成品”的闭环能力。
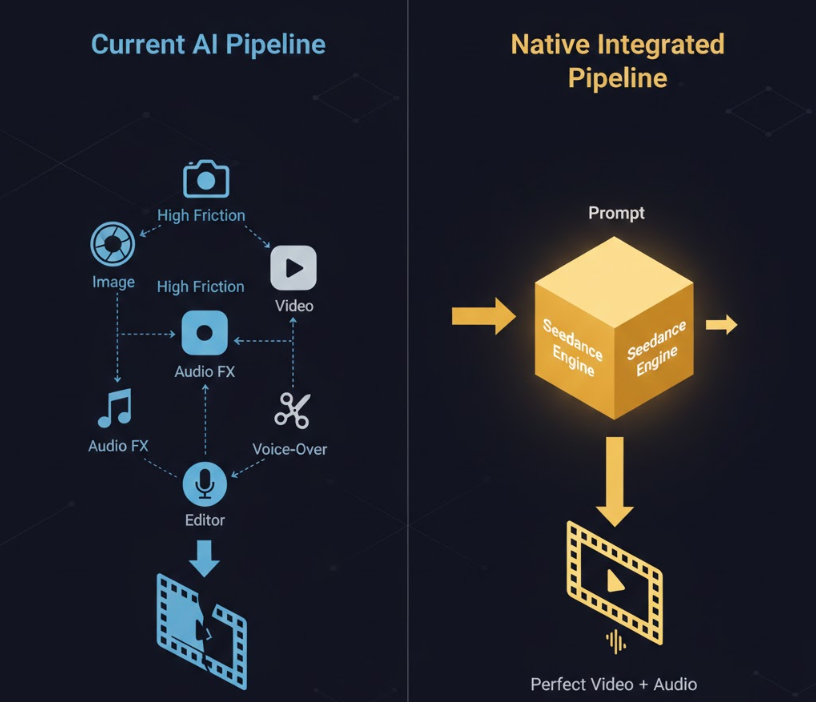
二、 技术解构:什么是“原生音画一体化”?
Seedance 1.5 Pro 的核心突破在于其底层架构的重构。它不是在视频生成后“外挂”一个音频模块,而是将音频和视觉信号视为同一推理过程中的两个并行流。
1. 联合推理:
在模型的潜空间里,"玻璃破碎"的视觉特征与"清脆响声"的音频特征被编码在了一起。当你输入提示词时,模型是同时“想象”画面和声音。这种端到端的设计,使得它在处理口型同步)、环境音效时达到了帧级精度。
2. 深度语义理解:
Seedance 1.5 Pro 对提示词的理解不再局限于“画面描述”。它能听懂“导演指令”。
- 情绪与节奏: 它可以理解“紧张的氛围”,并生成与之匹配的急促镜头和压抑的背景音。
- 运镜控制: 支持推拉摇移(Zoom/Dolly/Truck)。当镜头快速推向角色时,音频的响度也会随之产生空间感的变化(多普勒效应或距离感),这是传统拼接模式无法做到的物理一致性。
3. 物理一致性:
这是该模型最令人惊喜的细节。在复杂的物理运动场景中(如物体掉落、车辆碰撞),视觉的物理反馈与听觉的声学反馈实现了高度统一,极大地消除了 AI 视频常见的“虚假感”。
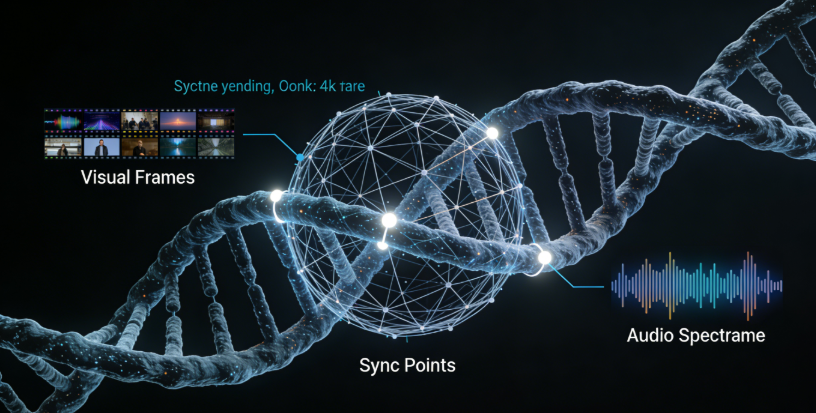
三、 差异化战略:不卷时长,卷“颗粒度”
在 Sora 引发的“时长焦虑”下,大多数模型都在比拼谁能生成 60 秒甚至更长的视频。Seedance 1.5 Pro 却选择了一条反共识的道路:Quality per Second(每秒质量) > Output Duration(输出时长)。
1. 叙事连贯性 :
相比于生成一段冗长但逻辑崩坏的视频,Seedance 更注重短镜头内的角色一致性和环境连续性。这使得它非常适合用于多镜头叙事。创作者可以用它生成一个个高质量的、音画同步的“分镜”,最后串联成片,而不是期待 AI 一次性生成一部电影。
2. 电影级运镜:
它赋予了创作者导演级的权力。手持摄影的晃动感、纪录片的真实感、希区柯克式的变焦……这些视觉语言配合精准的音效,让生成内容不再是“素材”,而是“成片”。
3.数据表现:
下图分别展示了 Seedance 1.5 pro 与前代 Seedance 1.0 pro、其他竞品模型在 T2V 和 I2V 任务中的性能比较结果。在 T2V 生成任务中,Seedance 1.5 Pro 在指令遵循(对齐度)指标上取得了领先表现,在画面美感、运动质量等指标上也展现出较强竞争力。在 I2V 任务中,Seedance 1.5 Pro 同样保持了稳定而突出的整体表现。
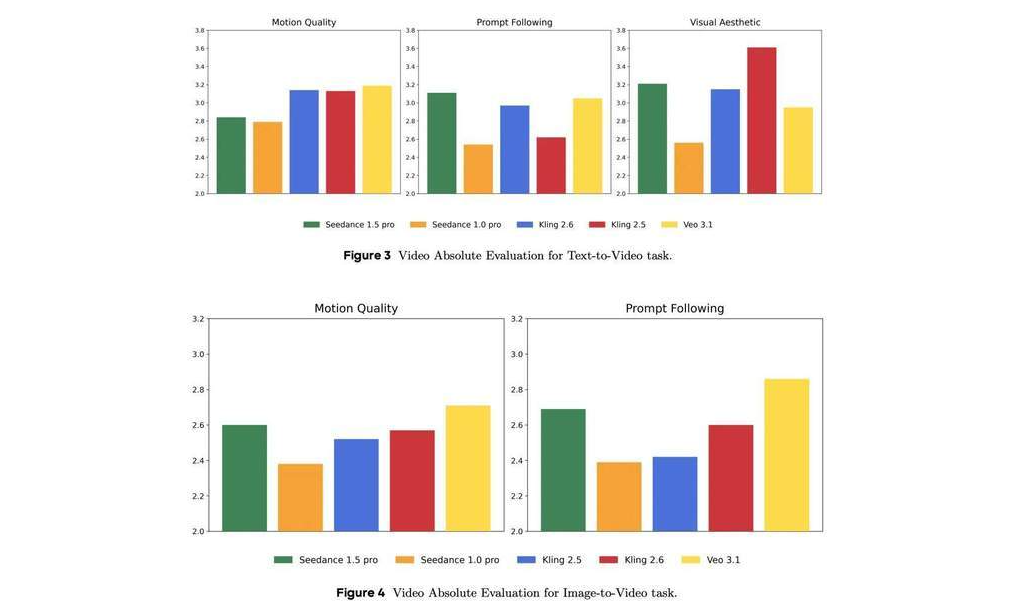
4.Seedance 1.5 pro 评测结果指令遵循、音频表现突出
该测试评估标准,重点考察模型在视觉复杂指令遵循、运动稳定性与生动性、美学质量,以及音频指令遵循、音画同步、音质表现力等维度的表现。
在视频生成方面,相比对比评测的其他模型,Seedance 1.5 pro 对动作、镜头等复杂指令的理解相对精准,可更好匹配提示词设定的叙事与影像风格。评测显示,其动态表现较为饱满,人物表情特写生动,复杂运镜相对流畅且与参考图风格衔接自然统一,整体画面质感更贴近实拍;不过,其运动稳定性仍有提升空间。
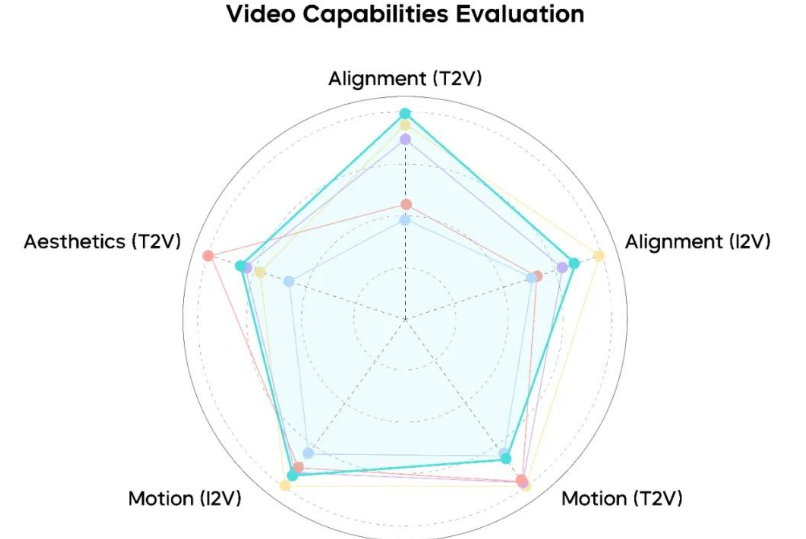
Seedance 1.5 pro 视频生成能力评测
在音频生成方面, Seedance 1.5 pro 处于业内头部水平。模型在音频指令遵循、音画同步、音质与表现力等维度表现稳定且均衡:能相对准确地生成匹配的人声与指定音效,尤其在中文台词场景中具备较高的完整性与发音清晰度,并可响应多种方言指令。
相比同类模型,Seedance 1.5 pro 生成的人声相对更自然、机械感更少,音效真实感与空间混响较为贴近实际,同时音画错位现象显著减少。尽管后续仍需重点提升其在多角色交替对话及歌唱类场景的表现,但综合来看,该模型已能部分应用于中文及方言对白驱动的短剧、舞台演艺及电影类叙事场景。
Seedance 1.5 pro 音频生成能力评测
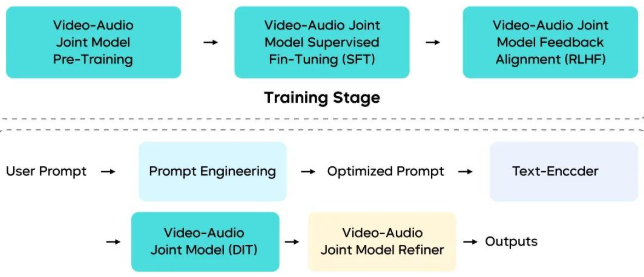
Seedance 1.5 pro 采用音视频联合生成的基座模型设计,通过底层架构、数据链路、后训练与推理环节的重构,提升了模型在多样化复杂任务中的泛化性能。
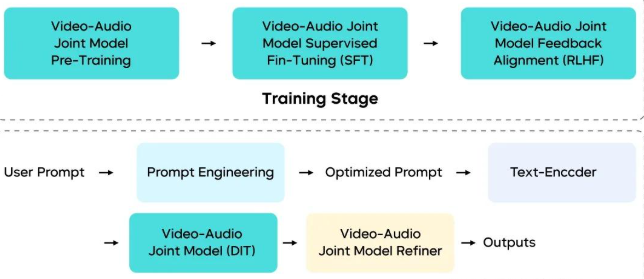
Seedance 1.5 pro 训推框架图
- 多模态联合架构:提出了一种基于 MMDiT 架构的统一音视频联合生成框架,通过深度跨模态信息交互机制,实现了视觉与听觉流在时间同步与语义一致性上的精准协同。
- 多阶段数据 Pipeline:设计了平衡音视频一致性、运动表现力与课程化调度的多阶段数据链路。该方案显著增强了视频描述的丰富度与专业性,并融入音频描述,为高保真音视频生成任务提供了高质量、多样化的数据基础。
- 精细化后训练优化:采用了高质量音视频数据集进行监督微调 (SFT),并引入专为音视频场景定制的 RLHF 算法。具体而言,多维奖励模型有效增强了文生视频 (T2V) 和图生视频 (I2V) 任务的表现,全面提升了运动质量、视觉美感及音频保真度。
- 高效推理加速:进一步优化了多阶段蒸馏框架,大幅降低生成所需的函数评估次数 (NFE)。通过集成量化、并行等推理基础设施优化,在保持模型性能的同时,实现了超过 10 倍的端到端推理加速。
四、 商业化前景:谁在为“同步”买单?
Seedance 1.5 Pro 的特性决定了它不仅是玩具,而是生产力工具。其商业价值主要集中在以下三个高频场景:
1. 短视频内容生产(TikTok/Reels/Shorts):
对于需要大量口播、剧情演绎的短视频创作者,原生口型同步功能是 “降本增效”的神器。它省去了昂贵的配音和繁琐的对轨环节,能将单条视频的制作周期从小时级压缩到分钟级。
2. 品牌与电商广告(Brand Storytelling):
电商广告需要极强的感官刺激。Seedance 能够生成带有强烈节奏感和音效配合的产品展示视频(如汽水开瓶的声音配合气泡画面),这种视听双重刺激能显著提升广告的完播率)和转化率。
3. 影视分镜与微电影(Pre-viz & Micro-films):
对于专业影视团队,它可以作为极其精细的动态分镜工具(Pre-visualization)。导演不仅能看到画面,还能听到音效氛围,大大降低了前期的沟通成本。

五、 结语:AI 视频的“有声电影时刻”
1927年,《爵士歌王》的上映终结了默片时代,重塑了电影工业。Seedance 1.5 Pro 正在 AI 视频领域通过“音画同构”引发同样的变革。它告诉行业:未来的生成式媒体,不应是视觉与听觉的简单叠加,而应是感官的整体重构。当 AI 开始同时“看见”和“听见”世界时,我们距离真正的通用世界模型又近了一步。对于创作者而言,工具的门槛正在消失,唯一的限制,只剩下你的想象力。
