

DeepSeek-R1 发布一周年:那个让扎克伯格“彻夜难眠”的模型,如今已被 30B 小模型全面超越?


导语: 一年前的今天,DeepSeek-R1 横空出世。仅仅 365 天,整个 AI 格局已经天翻地覆。回望 2025 年初,扎克伯格被迫解散 Meta AI 训练团队,Sam Altman 在国会游说暂停 AI 发展。硅谷坚信美国的“算力护城河”固若金汤。然而,DeepSeek-R1 的出现,像一把手术刀,精准切开了 OpenAI 以“安全”为名构建的商业壁垒。今天,我们站在一周年节点,复盘这场改变 AI 历史进程的战役。
一、 曾经的王者:它是如何让硅谷巨头们“集体焦虑”的?
在 DeepSeek-R1 出来之前,硅谷的大佬们日子过得很舒适。OpenAI 掌握着话语权,价格体系也相对稳固。但 R1 的出现打破了这一切。
- Meta 的战略收缩: 扎克伯格不得不解散旗舰团队,紧急组建“作战室”应对挑战。
- Llama 的困境: 曾经的开源领袖 Llama,在 R1 的强势表现下显得有些力不从心。
- 游说的背后: Altman 和 Dario 跑到国会要求暂停 AI 发展,其实反映了他们对技术护城河被跨越的深层担忧。
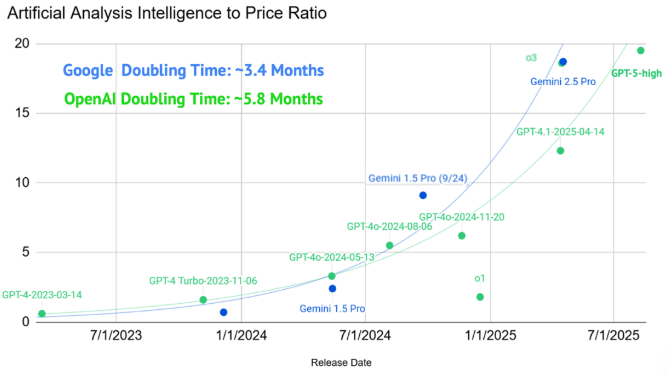
图 1:AI 模型能力的指数级跃升与成本的断崖式下跌
二、 拒绝黑盒:OpenAI 不想公开的“思考过程”,被它摆到了台面上
以前,OpenAI 总是以“安全”为由,隐藏 AI 的思维链。用户付费购买了结果,却无法知晓过程。R1 打破了这一潜规则:它把推理过程全公开了!
这让 OpenAI 陷入了被动,因为用户开始意识到:既然我为思考付费,我就应该看到完整的思考过程。这是用户的权利,却需要通过激烈的市场竞争来夺回。
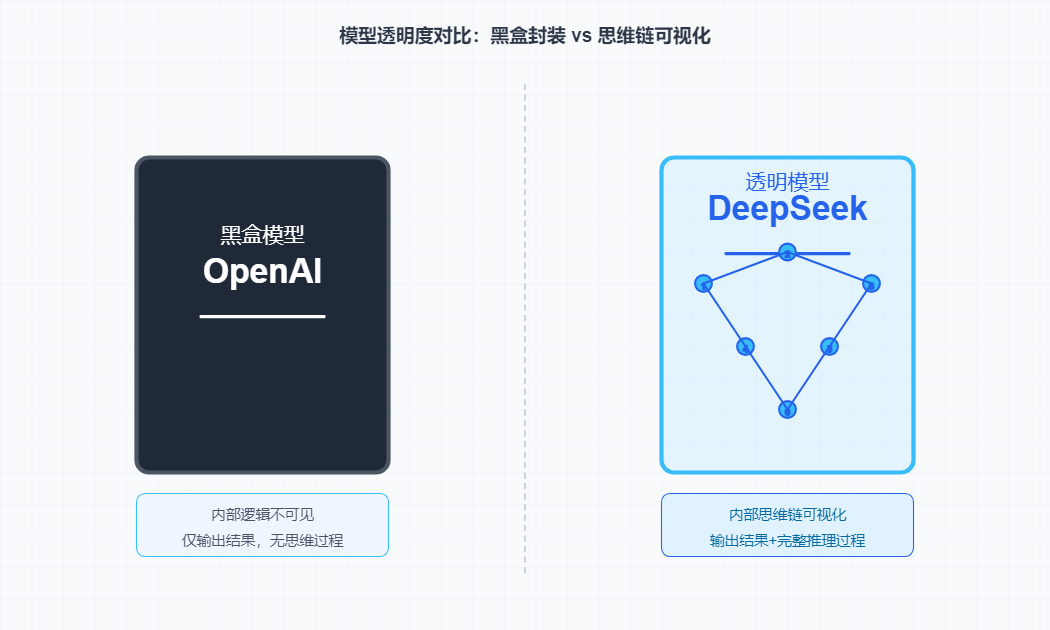
图 2:DeepSeek-R1 发布后,主流模型推理成本下降曲线
三、 价格重塑:一招击穿了 Llama 的防线,逼得对手不得不降价
R1 最具杀伤力的一点是“极致性价比”。它大幅降低了推理模型的成本,将 AI 从昂贵的“奢侈品”变成了普惠的“日用品”。
这直接导致了商业模式的重塑:
- 单纯卖模型难了: 靠模型本身的溢价生存变得困难,企业必须转向服务和落地场景。
- 生态繁荣: 低成本引发了开发者生态的爆发,各种基于 R1 的应用层出不穷,反过来巩固了 DeepSeek 的地位。
四、 现实打脸:那些喊着“技术封锁”的大佬,现在还坐得住吗?
Amodei(Anthropic CEO)曾发长文论证美国需要垄断 AI 技术。现在看来,这种论调在技术实力面前显得苍白无力。R1 证明了:技术创新不分国界,开源才是推动进步的核心力量。
- Llama 的现状: 虽然 Llama 3.3 70B 依然是优秀的“百科全书”,但市场已经用实际行动选择了更具竞争力的 R1。
- 技术民主: R1 的成功,是对“技术霸权”思维的一次有力回击。
五、 进化的奇迹:现在的“轻量级”模型,已经比去年的“重量级”还强
最让人感慨的是,才过了一年,技术的迭代速度已经超乎想象。
当前模型能力对比表
| 模型名称 | 参数量 | 综合能力 (对比 R1) | 评价 |
|---|---|---|---|
| DeepSeek-R1 | 671B (超大) | 100% | 开创时代的标杆,定义了透明化标准。 |
| GLM-4.7 Flash | 30B (轻量) | > 100% | 以小博大! 在推理、数学、编码上全面超越 R1。 |
| Kimi K2 Thinking | 未知 | 显著超越 | 全方位领先,展现了技术的代际优势。 |
| Qwen3 | 4B (极小) | ~80% | 虽然小,但已具备与曾经的王者一较高下的潜力。 |
简单说: 现在的 30B 模型(轻量级),其智能水平已经超过了一年前的 671B 模型(重量级)。这就是摩尔定律在 AI 时代的加速版。
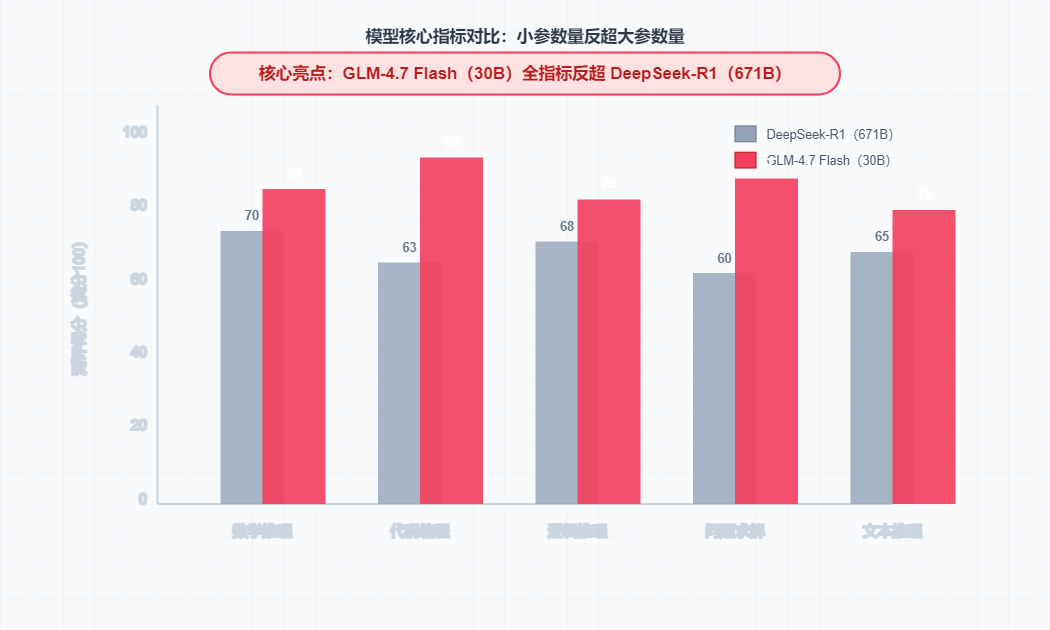
图 3:模型参数量与性能的“剪刀差”:更小的模型,更强的智力
六、 总结
DeepSeek-R1 的一周年,不仅是产品的胜利,更是竞争的胜利。它告诉我们:试图用“监管”和“封锁”来阻挡技术洪流是徒劳的。 一年时间,从“不可能”到“稀松平常”,30B 模型超越曾经的王者,这就是技术进化的力量。在这个飞速发展的 AI 时代,没有永远的赢家,只有永远在路上的创新者。
