
别再迷信 ChatGPT 了!只用一个 AI 的公司,注定被“多模型”对手打败

大模型
模型部署
性能优化
文章摘要
曾经的霸主ChatGPT输给了GoogleGemini,DeepSeek在多模态任务上表现不佳。

导语: 一份震撼的 AI 大测评。结果让人大跌眼镜:曾经的霸主 ChatGPT 竟然输给了 Google Gemini,而备受期待的“黑马”DeepSeek 在多模态任务上直接挂零。
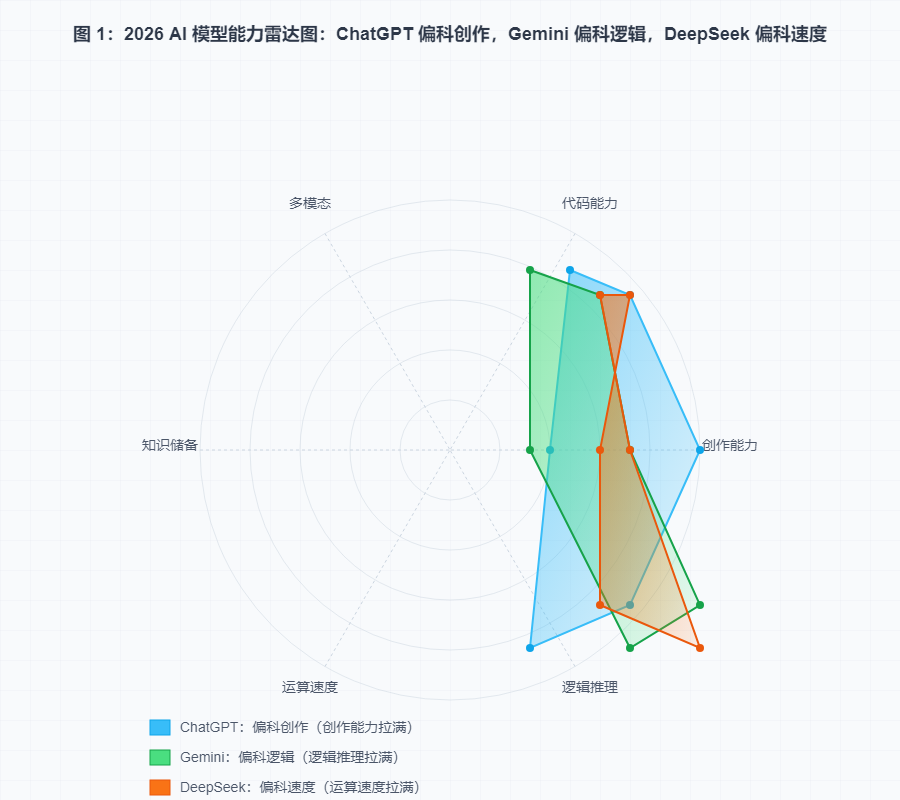
一、 测评大翻车:曾经的神 ChatGPT,怎么连个“手指”都数不清?
AI 届的“偏科”现状。
- 画图翻车: 即使是 ChatGPT (Sora 2) 和 Grok,在生成“蒙娜丽莎抗议”图时,依然会画出三只手或四只手。
- 常识黑洞: 在生成“月球登月”视频时,Gemini (Veo) 居然让旗子在没有大气的月球上飘动。
- 事实错误: 问“全球宰杀了多少只鸡”,只有 Grok 答对了(690亿),其他全部估算错误。
测评总分排名:
- Gemini (46分): 六边形战士,事实核查最强。
- ChatGPT (39分): 解决生存问题最靠谱,但细节拉胯。
- Grok (35分): 懂硬件、有个性,但偏科严重。
- DeepSeek (17分): 速度之王,但也是“瘸腿之王”(无多模态)。
(数据来源:CSDN 2026 AI 大测评)
二、 别把鸡蛋放在一个篮子里:为什么你需要一支“AI 混编战队”?
如果你的公司只用 ChatGPT,你会面临两个死局:
- 贵: 用 GPT-4 处理简单的“提取发票信息”任务,就像用牛刀杀鸡,成本极高。
- 慢: 在需要秒级响应的客服场景,GPT-4 的推理延迟能把用户急死。
解法: 组建一支“混编战队”。
- 指挥官(Router): 一个轻量级模型,负责判断任务难度。
- 特种兵(GPT-4/Gemini): 处理 10% 的高难度逻辑推理。
- 步兵连(DeepSeek/Llama): 处理 90% 的简单文本处理和翻译。
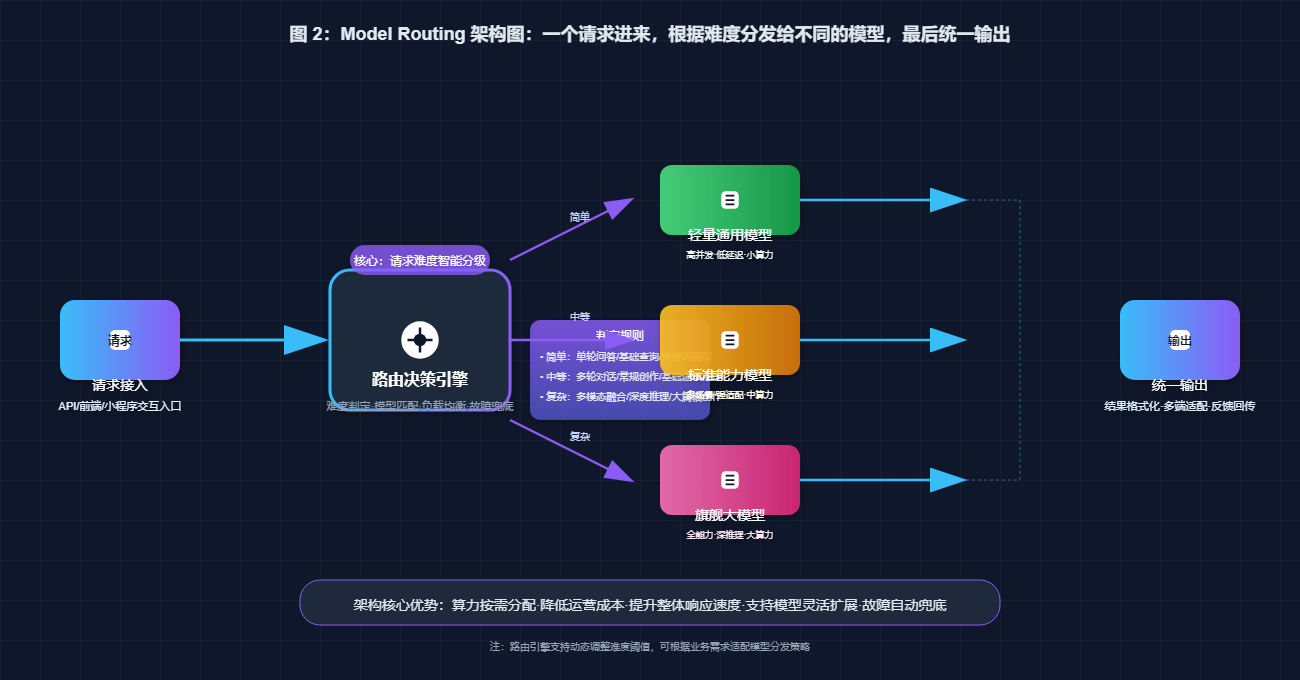
三、 Model Routing 是什么鬼?简单说就是“看人下菜碟”
Model Routing(模型路由) 是 2026 年企业 AI 的核心基础设施。它的逻辑就像医院的分诊台。
- 场景演示: 用户问了一个问题。
- 路由器判断:
- 如果是“帮我写首诗” -> 路由给 ChatGPT(擅长创意)。
- 如果是“查询 iPhone 17 参数” -> 路由给 Grok(擅长实时搜索)。
- 如果是“总结这篇 5000 字文章” -> 路由给 DeepSeek(擅长长文本且便宜)。
技术价值: 这不是简单的切换,而是毫秒级的动态调度。它保证了你永远在用性价比最高的模型解决当前问题。
四、算账时刻:DeepSeek + GPT-4,怎么让你省下 80% 的钱?
让我们来算一笔账。假设一家企业每天要处理 100 万次 API 调用。
成本对比模型:
| 方案 | 策略 | 预估月成本 | 响应速度 | 准确率 |
|---|---|---|---|---|
| All-in GPT-4 | 所有任务都用最贵的模型 | $30,000 | 慢 (平均 3s) | 95% |
| Model Routing | 80% 流量给 DeepSeek 20% 流量给 GPT-4 |
$5,000 | 快 (平均 0.8s) | 94.8% |
(数据来源:Martian.ai 模型路由成本分析报告)
通过引入 Model Routing,企业仅牺牲了 0.2% 的准确率,却换来了 83% 的成本下降 和 3 倍的速度提升**。这就是 DeepSeek 存在的意义——它不是来打败 GPT-4 的,它是来帮 GPT-4 挡子弹的。
五、 未来的 AI 不是“超人”,而是“包工头”
未来的 AI 应用,不会只有一个大脑,而是一个“专家委员会”。
- 前端: 一个极速响应的“接待员”(如 DeepSeek-V3),负责理解意图。
- 中台: 一群专业的“工匠”(如 Midjourney 画图、Codex 写代码、Gemini 查实事)。
- 后台: 一个拥有最终决定权的“法官”(如 GPT-5),负责审核结果,兜底复杂逻辑。
商业启示: 谁能最先构建出这套“模型编排系统”,谁就是 AI 时代的微软。
六、 总结
别再问“哪个 AI 最好”这种傻问题了。成年人的世界不做选择,聪明的企业全都要。只有学会像搭积木一样组合使用 ChatGPT 的脑子、DeepSeek 的速度和 Gemini 的严谨,你才能在这个算力通胀的时代,真正实现降本增效。
以上内容不代表本平台立场,仅供读者参考
