
杀到全球第二!Vidu Q3 实测:16 秒声画同出,中国 AI 视频终于能“讲故事”了


导语:中国 AI 视频模型,又双叒上大分了。在 Artificial Analysis 最新发布的榜单中,Vidu Q3 杀出重围,排名中国第一、全球第二,不仅甩开了 Sora 2 和 Runway Gen-4.5,更直接硬刚马斯克的 xAI Grok。这一次,Vidu Q3 带来的不是简单的画质提升,而是对规则的颠覆:全球首个 16 秒音视频直出模型。它不再是只会生成 4 秒动图的“哑巴”,而是能说话、能运镜、能讲故事的“导演”。今天,我们第一时间上手实测,看看它到底有多强。
一、 榜单黑马:Vidu Q3 硬刚 Grok,中国 AI 视频的高光时刻
在 AI 视频这个修罗场,大家一直在卷画质、卷一致性,但时长始终卡在 10 秒以内。
Vidu Q3 的出现,直接把天花板拉高到了 16 秒。
排名: 全球第二(仅次于 Grok),超越 Sora 2、Gen-4.5、Veo 3.1。
意义:16 秒不仅仅是时间的延长,它是叙事单元的质变。4 秒只能做一个动作,16 秒足够讲一个起承转合的故事。更重要的是,它是声画一体的。
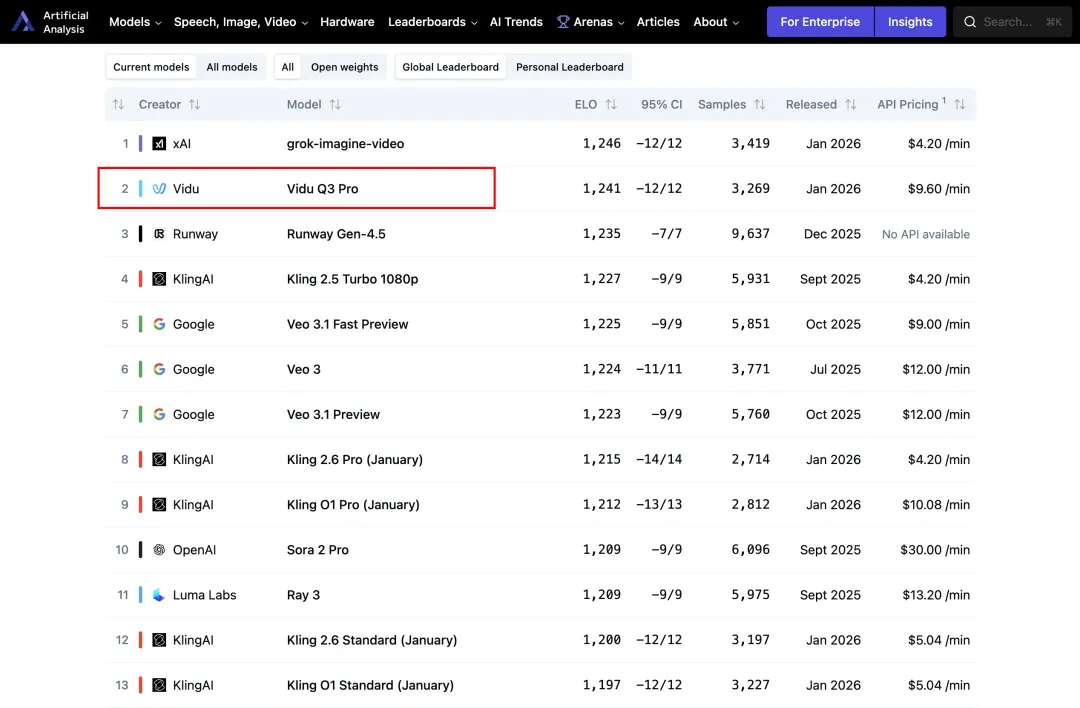
图源:AI大模型工场
二、 核心突破:告别“哑剧”,16 秒长镜头如何重构叙事?(附实测 Prompt)
长久以来,AI 视频最大的痛点是“哑巴”和“碎片化”。你需要先生成视频,再找配音软件配音,最后剪辑对轨。
Vidu Q3 解决了这个问题:输入一段话,直接吐出带声音、带剧情的 16 秒成片。
实测案例 1:灾难片质感
Prompt: 一个40岁的中年男子穿着燕尾服,坐在船舱里弹钢琴,船员逃窜,外面狂风呼啸,巨轮倾斜...随着船体四分五裂,只留下他和钢琴在一块破损的地板上漂浮,四处海浪滔天。
画面: 船舱倾斜 60 度,海水倒灌,极具视觉冲击力。
声音:钢琴声的优雅与海浪的咆哮声完美融合,且符合物理规律(船体撕裂声卡点准确)。
结论:这不是素材,这是成片。
视频来源:AI大模型工场
实测案例 2:情感对话
Prompt:一对中年夫妇的电影感对话场景...女性看着男性说:“I told you the life I wanted… but you always ignore me.”
表现: 这是一个长达 16 秒的细腻表演。AI 理解了台词背后的潜台词——沉默、眼神回避、无奈的叹息。
突破:AI 视频的天花板从“物理模拟”提升到了“情感演绎”。

图源:AI大模型工场
三、 导演级运镜:分镜自由切换,AI 终于懂了“蒙太奇”
传统 AI 视频最让人头疼的是镜头不受控。Vidu Q3 让你拿回了“导演权”。
实测案例:日漫风打斗(7 个分镜)
Prompt: 分镜一:全景... 分镜二:特写... 分镜七:咒术师咳血低笑...
效果:Vidu Q3 完美执行了全景、中景、特写、俯拍的切换。更绝的是,镜头的切换与声音的节奏(打斗声、铃铛声)严丝合缝。
意义:AI 开始理解“视听语言”。它不再是生成一堆乱序的帧,而是在脑海里先剪辑好了再画出来。






图源:AI大模型工场
四、 细节狂魔:治好“鬼画符”,多语言口型完美对齐
细节决定成败。Vidu Q3 在两个老大难问题上取得了突破:文字渲染和多语言口型。
- 文字渲染:
- Prompt:让霓虹灯管风格的英文字母 FUTURE 逐一亮起。
- 结果:拼写准确,光影自然,不再是乱码。
- 多语言能力:
Prompt: 深沉男声用日语说:“电影温暖世界...”。
结果:口型精准匹配日语的音节节奏,甚至连说话时的神态都带有日本文化的含蓄感。

 图源:AI大模型工场
图源:AI大模型工场
五、 商业化前夜:从“技术炫技”到“生产力工具”,谁在买单?
Vidu Q3 的发布,标志着 AI 视频进入了下半场:从“有”到“优”。
商业应用场景预测:
1. 短剧/漫剧:16 秒足以生成一个完整的反转情节。制作周期从天级缩短至分钟级。
2. 广告营销: 快速生成高质量的 Product Demo(如香水广告、汽车大片),成本断崖式下降。
3. 前期预览:导演可以用它快速生成带声音的动态分镜,极大降低沟通成本。
图源:AI大模型工场
六、 总结
Vidu Q3 是一次“低调的突袭”。它没有像 Sora 那样疯狂造势,而是用实打实的产品力——16 秒时长、声画同出、多镜头叙事——回应了市场的期待。对于创作者来说,工具的门槛正在消失,想象力成为了唯一的限制。对于行业来说,中国团队在 AI 视频领域的崛起,证明了我们在原生多模态(Native Multimodality)技术上已经站在了世界前列。
