
炸场!Qwen3.5全家桶发布:从中杯到超大杯,每个都是“偏科天才”?

春节刚过,阿里通义千问团队就给全球AI开源社区送上了一份“开工大礼包”。
一口气发布四个新模型:Qwen3.5-122B-A10B、Qwen3.5-35B-A3B、Qwen3.5-27B 以及基座模型。加上此前的旗舰397B,Qwen3.5系列不仅补齐了从3B到17B激活参数的全尺寸拼图,更通过原生多模态与混合注意力架构,在性能与效率之间找到了新的平衡点。
这不仅仅是简单的“中杯、大杯、超大杯”策略,这是一次针对不同应用场景的精准手术刀式打击。本文将深度拆解这波新模型的架构玄机与实战价值。
一、不只是参数游戏
这波Qwen3.5之所以备受关注,核心在于其底层的架构创新。
它们并非简单的Transformer堆叠,而是采用了 Gated DeltaNet 线性注意力 + 全注意力的混合架构。这种设计巧妙地解决了长序列推理的显存瓶颈,同时保留了全注意力的精度优势。
核心技术亮点:
- 原生多模态: 拒绝“拼接怪”。文本、图像、视频在同一模型内原生支持,理解更丝滑。
- 稀疏MoE架构: 激活参数极低(如35B模型仅激活3B),推理速度起飞。
- 超长上下文: 原生支持 262K,通过YaRN技术可无损扩展至 1M Token。
- MTP加速: 支持 Multi-Token Prediction,预测下一个Token时更准更快。
二、 选型指南:每个都是“偏科天才”
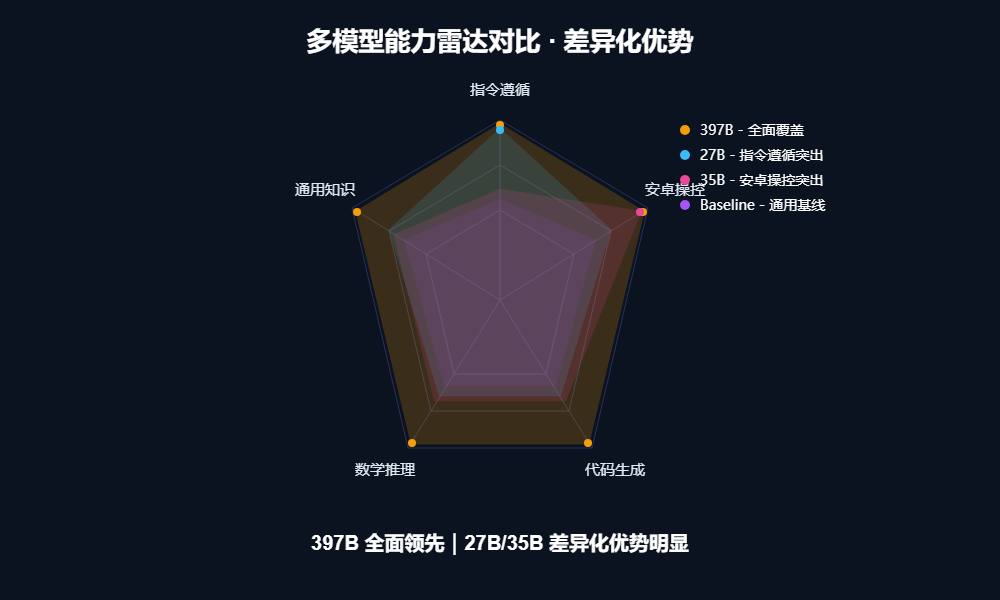
与其说是按尺寸分级,不如说是按“特长”分工。这四个模型在各自的领域都展现出了惊人的统治力。
表1:Qwen3.5 全系列模型核心能力与场景匹配表
| 模型型号 | Qwen3.5-397B (旗舰) | Qwen3.5-122B (全能中杯) | Qwen3.5-27B (指令专家) | Qwen3.5-35B (端侧刺客) |
|---|---|---|---|---|
| 激活参数 | 17B | 10B | 27B (Dense) | 3B |
| 核心特长 | 六边形战士 (知识/推理/搜索) | 性价比之王 (逼近旗舰) | 指令遵循/数学 (IFEval 95.0) | 安卓操控/端侧 (AndroidWorld 71.1) |
| 部署难度 | 极高 (多卡集群) | 中高 (企业级显卡) | 低 (单卡/易部署) | 极低 (消费级/手机) |
| 推荐场景 | 复杂科研、高精推理 | 企业级通用服务 | 本地编程助手、Agent | 移动端智能体、手机助手 |
深度评测:
-
Qwen3.5-27B:唯一的Dense独苗
- 亮点: 它是系列中唯一的稠密模型。虽然参数不大,但在指令遵循(IFEval 95.0)上竟然拿了全系列第一!
- 应用: 非常适合做本地编程助手。Dense架构部署简单,无需针对MoE做特殊优化,且代码能力(LiveCodeBench 80.7)甚至反超了更大的122B模型。
-
Qwen3.5-35B-A3B:端侧的“操作怪”
- 亮点: 仅3B激活参数,却在 AndroidWorld(安卓手机操控)测试中拿下了 71.1 的高分,直接干翻了397B旗舰(66.8)。
- 应用: 这显然是为手机厂商量身定制的。它证明了在特定任务(如操作手机App)上,小而精的模型比大模型更敏捷、更有效。
三、 生态预判:魔改狂潮即将来袭
Qwen系列的强大不仅仅在于模型本身,更在于其可怕的社区生态。
Qwen3.5的全面开源,意味着Hugging Face和Github上马上会出现一大波基于它的“魔改版”:
- 极致量化版: 能在4090甚至MacBook上跑满血的27B模型。
- 垂直领域版: 基于122B微调的医疗、法律模型。
- 角色扮演版: 社区最爱的长文本+多模态,Qwen3.5简直是天选底座。
对于开发者来说,Qwen3.5-27B(Dense)和Qwen3.5-35B(MoE)提供了两种截然不同的技术路线选择:是追求部署的简单性,还是追求推理的极致速度?
四、 结语
Qwen3.5的发布策略给行业上了一课:通用大模型“大一统”的时代结束了,场景定义模型的时代开始了。
旗舰负责秀肌肉,中杯负责扛流量,小杯负责钻终端。特别是35B-A3B这种“端侧特种兵”的出现,标志着大模型正在从云端神坛走向每一个人的口袋。
对于开发者而言,现在是最好的时代。不管你手里有什么卡,总有一款Qwen适合你。
