
DeepSeek为了省显卡太拼了!竟搞出这种“脏优化”,性能直接翻倍?


DeepSeek联合北大、清华发布了一篇名为 DualPath 的重磅论文。这篇论文没有讲模型参数,也没有讲新的注意力机制,而是解决了一个极其底层却又极其致命的工程问题:在Agent场景下,GPU大部分时间不是在算,而是在“等数据”。这与其说是一次技术创新,不如说是一次“带着镣铐跳舞”的极限优化。为了榨干硬件的最后一点性能,DeepSeek不得不采用了一种反架构直觉的“脏优化”策略。本文将深度拆解DualPath背后的技术无奈与工程智慧。
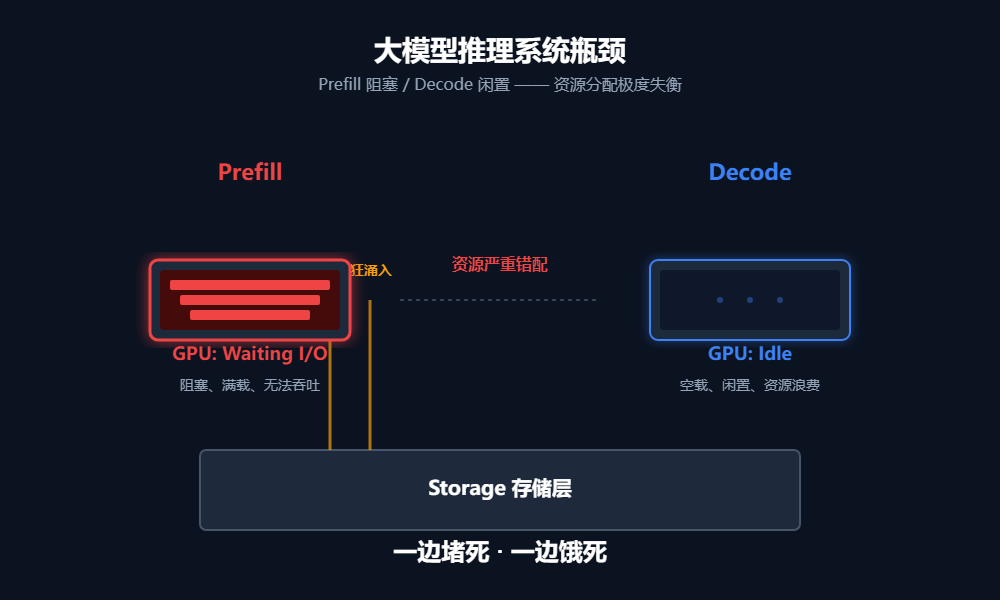
一、 瓶颈之痛:显卡在摸鱼,网卡在冒烟
在Agent(智能体)火爆的今天,大模型推理面临一个尴尬的现状:上下文越来越长,新生成的Token却很少。
这意味着每一轮推理,95%以上的数据都是“旧账”(KV-Cache)。GPU其实没多少计算任务,但它必须等着把这些旧数据从存储里搬出来才能开工。
在主流的 PD分离架构中:
- Prefill引擎: 负责理解输入,压力山大。它的存储网卡(带宽仅400G)被KV-Cache加载请求彻底挤爆。
- Decode引擎: 负责生成输出,相对清闲。它的存储网卡在Prefill阶段基本处于“摸鱼”状态。
这就像是一个厨房里,切菜工(Prefill)忙得不可开交,而炒菜工(Decode)却在旁边闲逛。
二、 借道超车
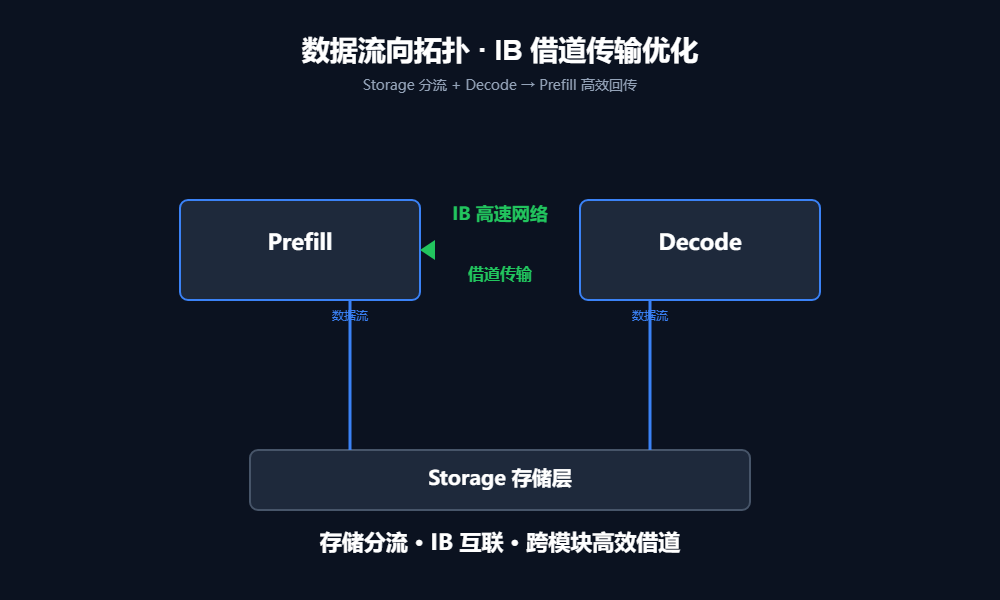
DualPath的核心思路非常“野路子”:既然Prefill侧堵死了,那就借Decode侧的路走!
数据先加载到Decode侧的显存,再通过GPU间的高速计算网络(InfiniBand,带宽高达3.2T)传输回Prefill侧。
这听起来很不符合架构直觉,就像是“为了喝口水,先把水倒进邻居家的缸里,再接根管子引过来”。但这确实是无奈之举,因为GPU间的路(IB网络)比存储到GPU的路(以太网)要宽得多。
DualPath 架构优化前后对比
| 核心指标 | 传统 PD 分离架构 | DualPath 架构 | 优化逻辑 |
|---|---|---|---|
| KV加载路径 | 仅通过Prefill存储网卡 | 双路并行(Prefill + Decode网卡) | 资源利用率翻倍 |
| GPU间网络* | 仅用于计算通信 | 复用 于数据搬运 | 榨干闲置带宽 |
| 离线吞吐 | 基准 (1.0x) | 1.87x | 显著提升 |
| 在线吞吐 | 基准 (1.0x) | 1.96x | 翻倍级增长 |
这就好比家里要炖汤,汤锅(Prefill)已经满了,而炒勺(Decode)还空着。DeepSeek的思路是:不管三七二十一,先把食材倒进炒勺里煮,然后再倒回汤锅。* 虽然听起来有点“脏”,但确实管用。
三、 流量微操:在高速公路上走钢丝
借道方案带来了一个巨大的风险抢路。
GPU间的IB网络本是用来跑模型推理的集合通信(AllReduce等)的,这些通信对延迟极度敏感。如果搬运KV-Cache把这条路堵了,推理性能反而会下降。
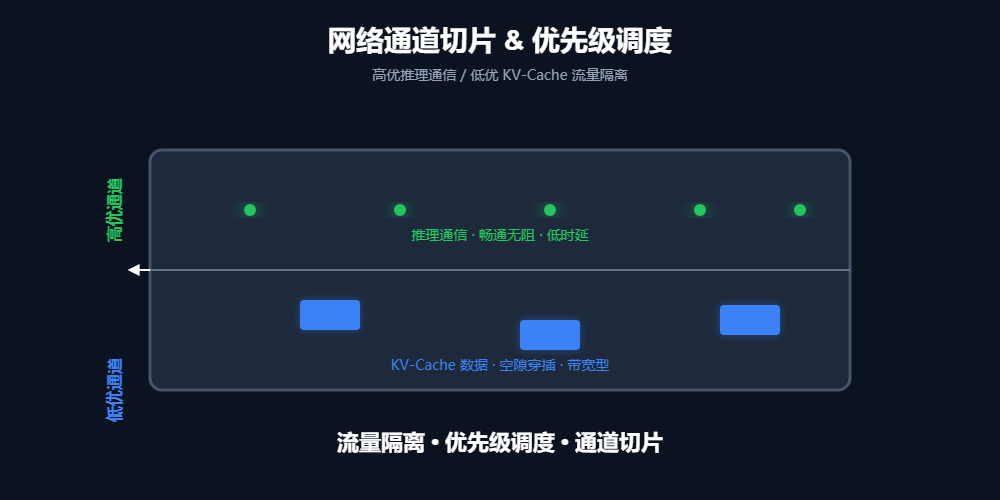
DualPath的解决方案堪称教科书级的QoS(服务质量)管理:
- 流量隔离: 利用InfiniBand的虚拟通道技术。
- 特权通道: 推理通信走高优先级通道,独占 99% 的带宽保障,谁都不能抢。
- 捡漏通道: KV-Cache搬运走低优先级通道,只在通信的间隙,捡空闲带宽用。
四、 结语:给工程师的一声叹息
看完这篇论文,心里其实挺不是滋味。
DualPath带来的性能提升是实打实的(吞吐量近乎翻倍),但这背后的技术路径却透着一股“贫穷的智慧”。
如果算力足够充裕,如果存储带宽不再是瓶颈,我们本不需要这种复杂的、反直觉的“脏优化”。DeepSeek的工程师们是在用极致的软件工程能力,去填补硬件资源的短板。
多给他们点显卡吧。* 这种优化虽然精妙,但我们更期待看到他们在模型架构上的天马行空,而不是在带宽的夹缝中闪转腾挪。
