
英伟达慌了?谷歌TPU杀疯了,全球算力要变天?

2026年3月,全球算力市场正在经历一场静悄悄的地震。
当所有人的目光还停留在英伟达的股价上时,Meta、OpenAI、Anthropic等巨头已经开始“用脚投票”。数十亿美元的订单流向了谷歌TPU,OpenAI甚至在最新的GPT-5.3主力模型中用了别家的芯片。
这场变局的背后,是显卡(GPU)越来越带不动了。“非GPU时代”的大幕正在拉开,而被称为“高阶TPU”的新一代芯片,正在重写游戏规则。本文将深度拆解这场算力革命背后的故事。
一、 谷歌摊牌了:我的TPU比显卡香多了
过去,TPU是谷歌自己偷偷用的宝贝;现在,它是刺向英伟达心脏的一把尖刀。
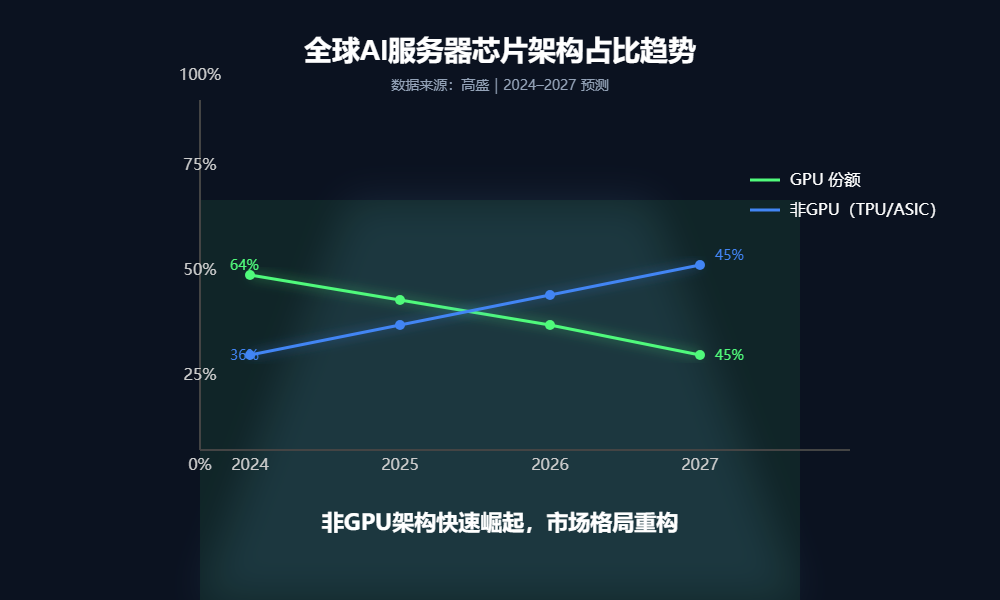
2026年初,有消息爆料:谷歌计划在2027年部署 600-700万颗 TPU,而且大部分要卖给别人用。这意味着,谷歌要拉着大家一起对抗英伟达了。
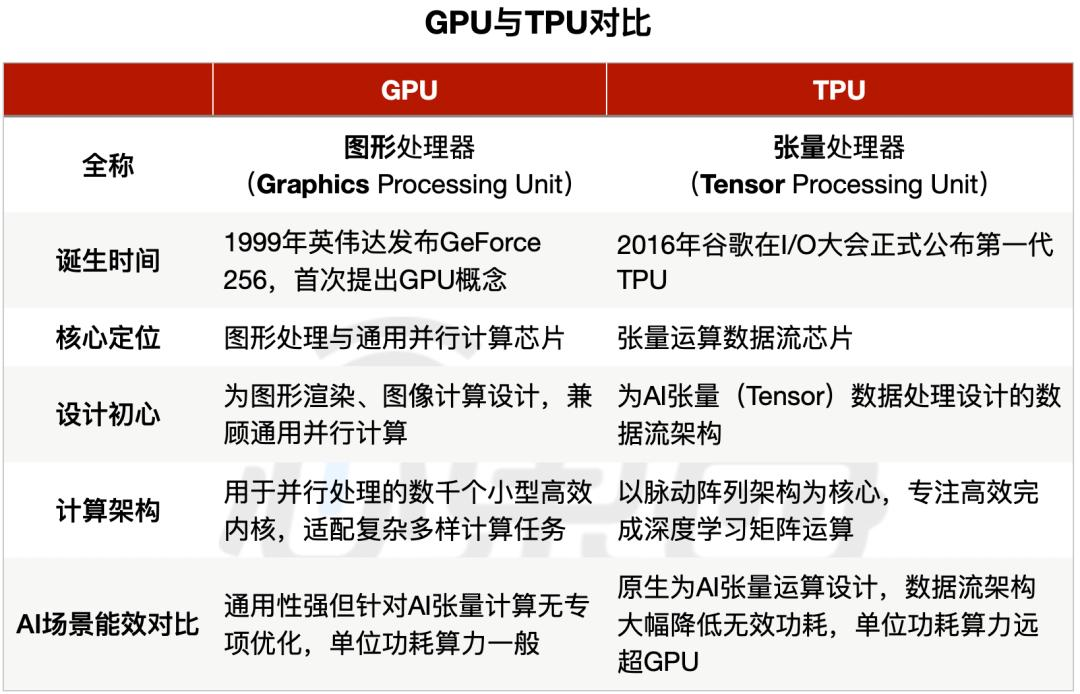
谷歌TPU v7 vs. 英伟达B200 到底谁强?
| 核心指标 | 谷歌 TPU v7 | 英伟达 B200 | 谁赢了? |
|---|---|---|---|
| 算力 | 很强 | 很强 | 平手 |
| 组网能力 | 9000多颗连在一起 | 规模受限 | TPU胜出 |
| 省电程度 | 功耗只有B200的一半 | 电老虎 | TPU完胜 |
| 使用成本 | 便宜一半以上 | 贵到肉疼 | TPU真香 |
| 生态 | 越来越开放 | 封闭 | 开放 vs. 垄断 |
“谷歌TPU的开放,是英伟达最不愿意看到的剧本。 过去大家买英伟达是因为没得选。现在,Anthropic用210亿美元的订单告诉市场:TPU不仅能用,而且更便宜、更省电。对于那些深受‘英伟达税’之苦的大模型厂商来说,TPU不是备胎,而是救命稻草。”
二、 显卡为啥不行了?因为它太“笨”
为什么OpenAI会对英伟达“不满”?因为显卡生来就不是为大模型设计的。
显卡的核心逻辑是“搬运工模式”。数据要在显存和计算单元之间来回搬运,这就像在一个没有传送带的工厂里,工人大部分时间都在等原料。这导致了耗电多、反应慢。
而以Groq为代表的“高阶TPU”,则是“流水线模式”。它让数据像流水线一样在芯片内部单向流动,不用来回搬。
1. 反应超快:告别“转圈圈”
Groq芯片的反应速度比TPU还要快 20%-50%。对于写代码这种需要实时反馈的场景,简直是神技。
2. 省钱省电
在干同样活的情况下,Groq的成本降低了 30%。这对于每天烧几百万电费的OpenAI来说,诱惑力太大了。
独家点评:
“英伟达花200亿美金买下Groq,不仅是消灭对手,更是在‘买未来’。 黄仁勋比谁都清楚,显卡的红利快吃完了。未来的芯片必须是更聪明的架构。Groq的技术路线,恰恰代表了未来的方向。这笔交易证明了:即使是巨龙,也害怕被新物种取代。”
图源:芯东西
三、 终极武器:比脸盆还大的芯片
如果说Groq是改了设计图,那么 Cerebras就是造了个怪物。
它不切芯片,它直接把整张晶圆做成一颗芯片。
- 优势: 内部通信快得离谱,几乎没有延迟。
- 实测: 速度比英伟达B200快 21倍,功耗还低 1/3。
OpenAI在GPT-5.3-Codex中引入Cerebras,标志着这种激进的技术终于被认可了。
未来的芯片长啥样?
| 技术流派 | 代表公司 | 牛在哪? | 解决啥问题? |
|---|---|---|---|
| 软件定义硬件 | Groq | 调度灵活、反应快 | 不用等红绿灯 |
| 晶圆级芯片 | Cerebras | 超大个头、超多核心 | 彻底消除通信堵塞 |
| 3D堆叠 | 清微智能 | 像盖楼一样堆芯片 | 缩短数据传输距离 |
独家点评:
“晶圆级芯片是半导体领域的‘暴力美学’。 以前我们觉得它良率低、散热难,是PPT产品。但现在,它在OpenAI的主力模型上跑通了。这说明:在极致的AI需求面前,没有什么工程难题是钱解决不了的。 未来的算力中心,可能不再是一排排服务器,而是一片片巨大的晶圆。”

四、 结语:别只盯着英伟达了
2026年的这场算力震荡,告诉我们一个道理:没有永远的老大。
英伟达依然强大,但它不再是唯一的选择。TPU、Groq、Cerebras,这些曾经的“非主流”正在成为巨头们的新宠。
对于中国芯片企业来说,这是一个危险的信号,也是一个巨大的机会。如果继续在显卡的路线上跟跑,永远只能吃残羹冷炙。唯有像Groq那样,在架构底层寻找突破口,才有可能在下一轮洗牌中拿到入场券。
别再迷信显卡了,算力的下一个十年,属于那些敢于推倒重来的勇者。
