
英伟达的护城河,被字节和清华用AI“挖”开了?

AI圈再次被一篇来自字节跳动Seed团队与清华AIR的论文炸场。这一次,主角不是什么通用的聊天机器人,而是一个名为 CUADAgent的“专家模型”。它干了一件所有深度学习工程师梦寐以求、却又视如畏途的事:自动化编写高性能CUDA内核。
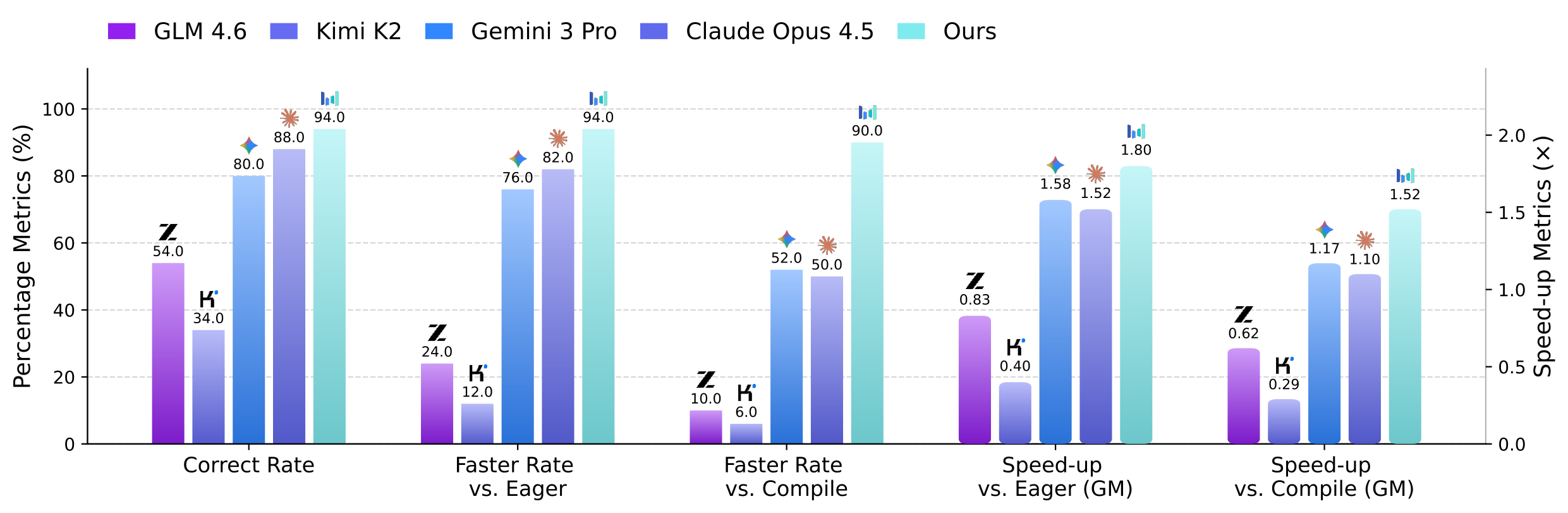
实测数据显示,它写出的代码比PyTorch官方编译器快了 2倍在复杂任务上更是碾压了Claude Opus 4.5和Gemini 3 Pro。这不仅仅是一个工具的胜利,更是对英伟达CUDA生态壁垒的一次“降维爆破”。
这篇论文的出现,标志着AI算力优化的权力结构正在发生根本性的位移。本文将深度拆解CUDA Agent背后的技术逻辑,并探讨它将如何重塑AI算力的未来。

一、 别再死磕代码了,AI比你更懂显卡
在深度学习的鄙视链顶端,站着一群被称为“CUDA Ninja(忍者)”的工程师。
过去,写CUDA代码是程序员的“黑魔法”。你不仅要精通C++,还要对GPU的微架构了如指掌:线程束(Warp怎么调度?共享内存怎么防冲突?访存合并(Coalesced Access怎么做?每一个细节都关乎性能的成败。
正是这极高的技术门槛,构成了英伟达最深的护城河——即便你有再强的显卡(如AMD或国产芯片),如果没有懂CUDA的人,算力也只是躺在机房里的废铁。
但CUDA Agent的出现,打破了这个神话。
不只跑得通,还要跑得飞快
以前的GPT-4也能写CUDA代码,但它像个只会抄作业的学生,只要能跑通就算赢。而CUDA Agent通过强化学习(RL),直接以“GPU运行速度”作为唯一的KPI。它不再是一个只会处理文本的语言模型,而是一个对着性能分析器死磕的资深架构师。
这种质变在基准测试中体现得淋漓尽致。在KernelBench测试集上,CUDA Agent的表现堪称恐怖:
在处理简单任务(Level-1)时,它生成的代码运行速度是PyTorch官方编译器(torch.compile)的 2.11倍。相比之下,Claude Opus 4.5和Gemini 3 Pro等通用大模型只能勉强做到1.2倍到1.3倍的提升。
而在真正考验功底的复杂任务(Level-3)上,CUDA Agent的加速达成率高达 92%,这意味着它在绝大多数情况下都能超越人类专家写出的基准代码。而作为对比,通用大模型的胜率只有50%左右,基本是“看运气”。

深度思考:
这一突破的本质,是AI第一次拥有了“硬件直觉”。在此之前,AI理解的是人类的语言逻辑;而现在,它开始理解数据的物理流动逻辑。它知道什么时候该把数据放进高速缓存,什么时候该让线程等待。这种“硬件直觉”曾经是人类专家需要数年经验积累才能获得的特权,现在却变成了模型的出厂设置。这不仅是效率的提升,更是“算力平权”*的开始。
二、 它是怎么练成“绝世武功”的?
为什么通用的GPT-4做不到,而CUDA Agent能做到?核心在于它构建了一套“基于真实反馈的实战演练系统”。
它是“刷题”高手
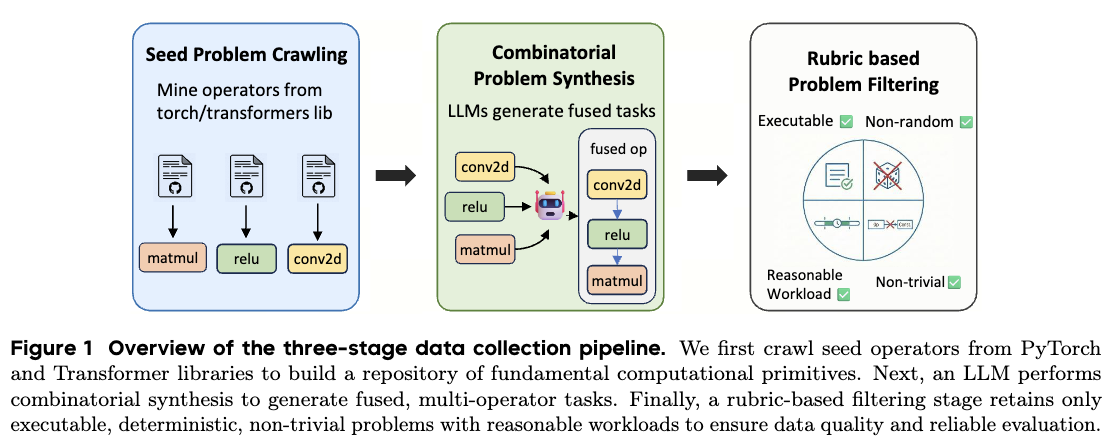
研究团队深知,通用的代码数据里充满了低质量的CUDA实现。于是,他们没有直接用现成的代码库,而是合成了一个名为 CUDA-Agent-Ops-6K 的高质量数据集。
这就像给AI准备了一套“CUDA奥数题库”。每一道题都经过了严格筛选,既有从PyTorch源码中挖掘的经典算子,也有通过LLM组合生成的复杂融合任务。通过剔除那些容易投机取巧的简单题目,研究团队逼迫模型必须去啃硬骨头。
对着答案改卷子
传统的RLHF(人类反馈强化学习)是让人来打分,这在代码优化领域既慢又贵,而且人类也很难一眼看出代码快不快。CUDA Agent创新性地采用了“编译器反馈”。
它的训练过程是一个闭环:
- 写代码: Agent生成CUDA内核。
- 跑分: 在真实的GPU沙盒环境中编译运行。
- 反馈: 获取运行时间、显存占用等真实指标。
- 修正: 如果慢了,就惩罚;如果快了,就奖励。
这个循环在沙盒里疯狂迭代,每一次失败都是为了下一次更快。这种“实战演练”,让模型迅速掌握了那些只可意会不可言传的优化技巧。
深度思考:
在我看来,这种“Environment-as-a-Signal(环境即信号)”的训练范式,比单纯堆砌数据要高级得多。它让模型直接与物理世界的规则(硬件性能)对话,而不是在人类的语言游戏中打转。
这或许指明了AI从“文科生”向“理科生”进化的正确方向——未来的AI模型,将不再仅仅通过阅读书籍来学习,而是通过在虚拟环境中不断试错、与物理规则互动来进化。这才是通往AGI(通用人工智能)的必经之路。
三、 英伟达该哭还是该笑?
CUDA Agent的开源,对英伟达来说,心情可能极其复杂。
好消息:用显卡的门槛低了
对于英伟达而言,CUDA生态既是护城河,也是扩张的瓶颈。以前,只有几万人的精英圈子能写高性能CUDA代码,这限制了GPU在更多长尾场景中的应用。
现在,几百万普通开发者只要会用Python提需求,就能通过CUDA Agent生成顶级的CUDA内核。这意味着GPU的算力将被更充分地榨干,应用场景将进一步爆发。从这个角度看,这将进一步巩固英伟达硬件的统治地位。
坏消息:护城河变浅了
然而,硬币的另一面是,护城河的本质变了。
CUDA生态之所以牢不可破,是因为几十年积累的软件栈和优化经验。如果AI能自动写CUDA,那它理论上也能自动写适配AMD ROCm的代码,或者适配华为CANN的代码。
当优化不再依赖人类专家的稀缺经验,而是变成了模型的通用能力时,硬件生态的迁移成本将大幅降低。这或许是所有硬件厂商都必须面对的未来:软件定义的硬件时代结束了,AI定义的硬件时代开始了。以后决定胜负的,不再是谁的软件库更全、生态粘性更强,而是谁的硬件架构更纯粹、对AI生成的代码更友好。英伟达曾经引以为傲的“软件生态壁垒”,在AI生成的洪流面前,可能会变得不再那么不可逾越。
四、 结语
CUDA Agent的出现,标志着AI算力优化的“自动化元年”。我们不再需要等待英伟达发布新的库,也不需要乞求Triton编译器的施舍。每一个开发者,都能拥有一支随时待命的“CUDA专家团队”。这不仅是效率的提升,更是算力使用权的下放。当底层的复杂性被AI屏蔽,上层的创造力才能真正爆发。 而对于整个芯片产业来说,这可能是一场重新洗牌的开始。
