
硅谷巨头烧钱把电网都干崩了,中国团队却反向出击,一刀砍碎Scaling Law!

全球AI算力战场硝烟弥漫,甚至可以说是有些疯狂。OpenAI正在为传说中的万亿参数模型寻找高达10GW的超级电网,那架势仿佛要抽干一座城市的电力。马斯克也不甘示弱,在孟菲斯竖起了拥有55.5万张GPU的Colossus集群,甚至把目光投向了太空,试图在近地轨道建立新的算力堡垒。
硅谷的信条依然是简单粗暴的:,直到AGI(通用人工智能)涌现。
然而,就在这场看似无止境的“军备竞赛”中,来自中国的 YuanLab.ai 团队却反向出击,发布了 Yuan 3.0 Flash。这款模型没有盲目追求参数的指数级爆炸,而是通过一种近乎外科手术般的算法革新,精准切除了大模型推理过程中的“废话肿瘤”。
实测数据显示,它将无效的推理Token砍掉了 75%,却在性能上逼近甚至超越了那些参数量大它几倍的巨兽。这不仅仅是一个模型的发布,这是对被奉为圭臬的“Scaling Law(缩放定律)”的一次叛逆式修正。本文将深度拆解这场技术突围背后的逻辑,以及它对AI下半场的深远影响。
一、 越想越错?AI也会“过度思考”
在过去的一年里,整个行业都在疯狂追逐“长思维链”。大家默认的逻辑是:AI想得越久,推理步骤越多,最终给出的答案就越准确。这似乎成了AI进化的唯一路径。
但事实真的如此吗?Anthropic的一项最新研究给这股热潮泼了一盆冷水:模型越大,算力越多,并不一定越聪明。更可能发生的情况是:浪费更大、思维链更乱、幻觉更猛。
这就像一个只有7分水平的学生,非要在考卷上写满1000字的解题过程。他写得越多,逻辑漏洞就越多,最后不仅浪费了时间,还把自己绕进去了。这就是所谓的“过度反思”。很多推理模型一旦摸到正确答案,不仅不停止,反而开始反复确认、来回推翻、在没有新证据的情况下继续“再想想”。
Yuan 3.0 Flash正是瞄准了这个痛点。
它是一个 40B 参数的MoE(混合专家)模型,但实际激活参数只有 3.7B。这就像是一支精锐的特种部队,而不是臃肿的常规军团。
与传统的推理模型(如GPT-5.1)相比,Yuan 3.0 Flash的推理逻辑发生了根本性的变化。传统模型追求“越长越好”,倾向于反复自我验证;而Yuan 3.0 Flash追求“适可而止”,懂得精准刹车。这种差异直接导致了Token消耗的巨大悬殊——前者极高,包含大量无效反思;后者通过去除废话,消耗降低了 75%。
这意味着算力成本从指数级增长回归到了线性可控,适用场景也从学术研究和开放探索,真正走向了企业落地和高频调用。
深度观察:“这不仅仅是省钱的问题,这是‘智能定义’的重构。以前我们认为,能写出长篇大论才叫智能。现在Yuan 3.0告诉我们,知道什么时候闭嘴,才是更高级的智慧。 在企业级应用中,老板不需要AI在那儿自我纠结三分钟,老板只需要一个准确的答案。YuanLab.ai这种‘反向操作’,恰恰切中了商业落地的命门——效率与准确性的平衡。”

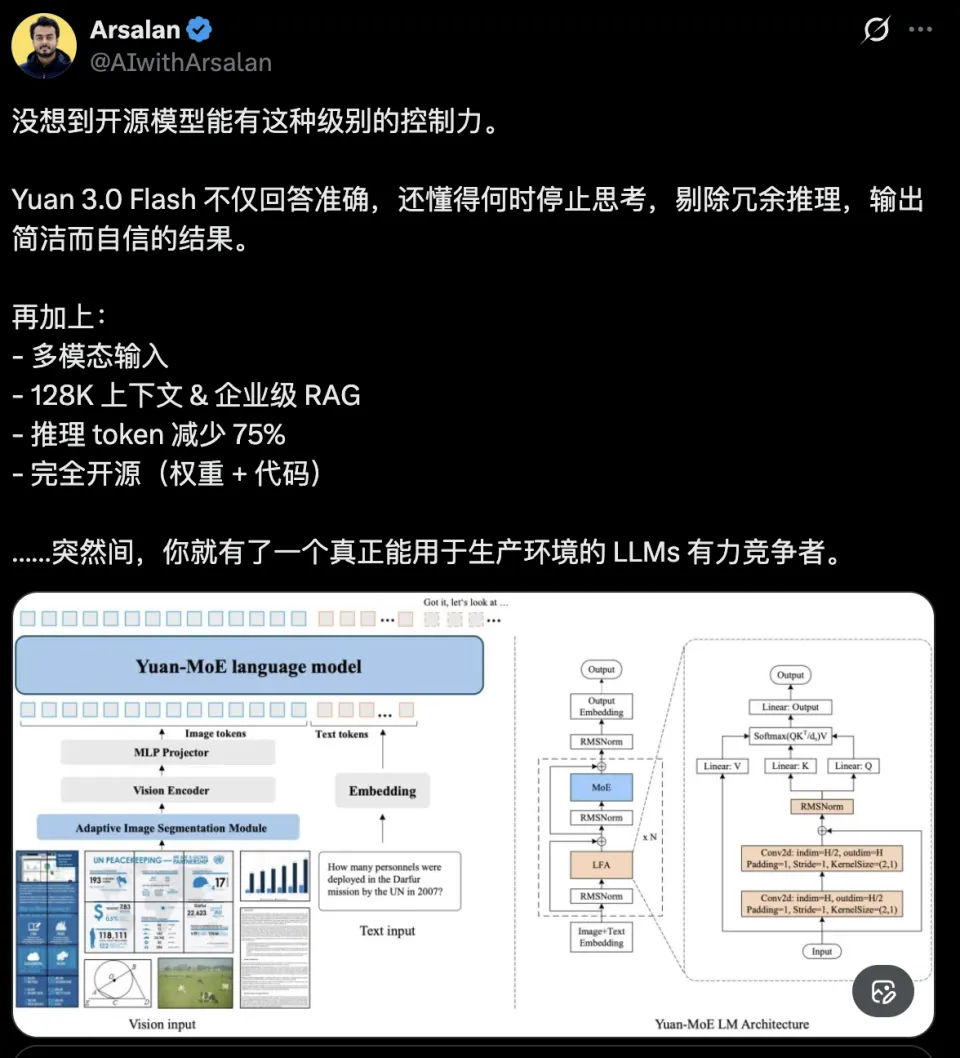
二、 怎么做到的?给AI装个“刹车片”
Yuan 3.0 Flash之所以能做到“少想多对”,核心在于两项堪称黑科技的算法创新:RIRM 和 RAPO。
RIRM:别在那儿瞎琢磨了
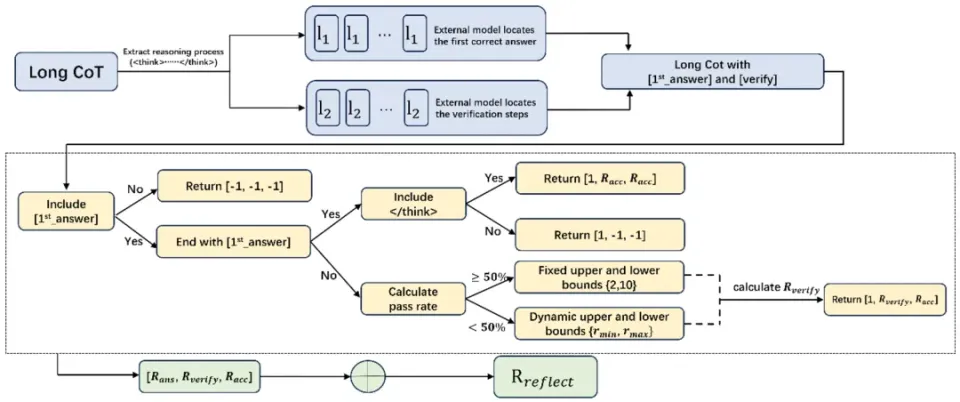
RIRM的全称是“反思抑制奖励机制”。简单来说,就是在训练的时候,给AI立了个新规矩。如果AI在得出正确答案后还在那儿废话连篇、反复推翻自己,就给它扣分(负奖励);如果它能干脆利落地给出答案并停止,就给它加分。
在MATH-500基准测试中,传统模型的“后答案反思”占比高达 71.6%,这意味着绝大部分计算资源都被浪费在了无意义的自我纠结上。而引入RIRM后,这一比例骤降至 28.4%,总Token减少了 47%,更神奇的是,准确率反而从83.2%提升到了 89.47%。
这就好比老师告诉学生:做完题检查一遍是可以的,但别在那儿把对的改成错的,或者在那儿纠结笔迹好不好看。这种机制让模型学会了辨别“足够好”的边界。
RAPO:让训练更稳更准
RAPO的全称是“反思感知自适应策略优化”。
MoE模型训练最怕的就是“梯度爆炸”和“专家负载不均”。RAPO就像是一个智能调度器,它解决了两个棘手问题:
- 自适应采样: 自动过滤掉那些没什么信息量的重复样本,让训练效率提升了 52.9%。
- 高熵更新: 只关注那些最难、最不确定的Token,把好钢用在刀刃上。
深度点评:“这其实是在教AI‘元认知’。AI不仅要学会解题,还要学会‘审视自己的思考过程’。它需要判断:我现在得到的这个答案够好了吗?还需要继续想吗?这种能力的涌现,比单纯的知识记忆要难得多,但也重要得多。RAPO与RIRM是协同设计的,前者决定模型‘如何学习’,后者明确模型‘学到什么程度该停’。这种系统性的改进,比单纯的模型微调要高明得多。”
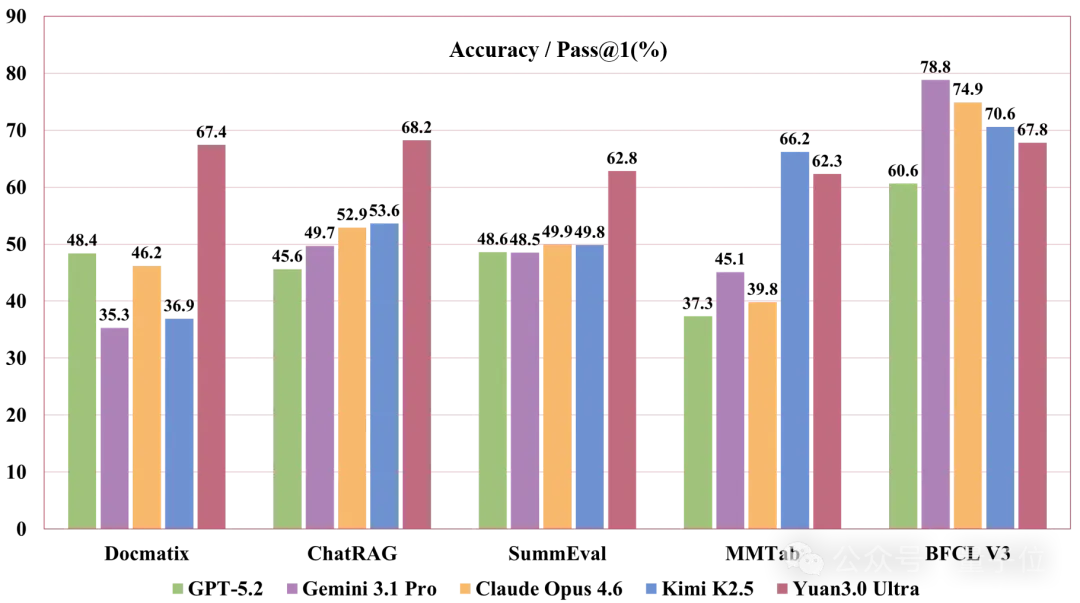
三、 企业乐坏了:终于用得起AI了
技术再牛,落不了地也是白搭。Yuan 3.0 Flash真正的杀伤力在于企业级场景。
想象一下,你需要分析一份几百页的财报,里面全是复杂的表格和图表。
如果用GPT-5这样的超大模型,可能要跑个几分钟,消耗几万Token,成本高达几美元。而且,由于思维链过长,还没准会产生幻觉,把关键数据搞错。
而Yuan 3.0 Flash的表现令人惊喜:
- 它支持 128K 的超长上下文,在“大海捞针”测试中实现了 100% 的准确召回。
- 在RAG(检索增强生成)任务上,准确率高达 64.47%,远超GPT-5.1的46.10%。这意味着它找资料不迷路,更准。
- 在多模态检索和表格理解上,分别达到了 65.10% 和 58.30%,即使是复杂的图表也能看懂,是数据分析的神器。
- 最重要的是,它的推理延迟极低,能实现秒级响应。
更关键的是,因为砍掉了75%的无效Token,推理成本直接打骨折。这对于那些对成本敏感的中小企业来说,简直是救命稻草。
深度观察:
“AI下半场,拼的不是‘大’,而是‘准’和‘省’。 企业不需要一个能写诗、能画画、能陪聊的全能天才,企业需要的是一个能准点打卡、干活麻利、不费电的优秀员工。Yuan 3.0 Flash就是这样一个经过‘职业化改造’的AI员工。它证明了:专用的小模型+极致的工程优化,完全可以在特定垂直领域击败通用的超大模型。这不仅为企业提供了一种更经济的选择,更是对‘长思维链’竞赛的一种理性回归。”
四、 结语:中国团队的“逆流而上”
YuanLab.ai的这次突围,给全球AI行业上了一课。
当硅谷还在迷信“大力出奇迹”,试图用能源和算力堆砌出未来时,中国团队用更精巧的算法、更务实的态度,走出了一条“少即是多(Less is More”的新路。
这不仅仅是技术路线的胜利,更是东方哲学在AI领域的投射:真正的智慧,不在于喋喋不休,而在于适时沉默。
2026年的春天,或许我们不需要更多的参数巨兽,我们需要的是更多像Yuan 3.0 Flash这样,懂得克制、懂得高效的“智慧灯塔”。大厂们需要学会的,是参与一场“适可而止”的革命。
