
豪掷1780亿!英伟达杀入开源战场,最强模型发布,DeepSeek与Qwen面临考验

平地起惊雷,2026年3月12日,英伟达(NVIDIA)正式宣布,将在未来5年内狂砸260亿美元(约合1787.9亿元人民币),全力开发开源 AI大模型,目标直指全球最顶尖。
这笔千亿资金将全面覆盖模型开发、基础设施、研究人才以及生态系统建设,预计首批模型将在2026年底或2027年初全面问世。
这是什么概念?OpenAI当年训练出GPT-4,耗资仅30亿美元。英伟达这次的预算,是其9倍之多。
一个常年稳坐钓鱼台的硬件供应商,为什么突然下场抢起了饭碗?
对 DeepSeek和Qwen又有哪些影响,这场开源大战又将掀起怎样的惊涛骇浪?塔猴梳理了前因后果,带你一探究竟。
01. 英伟达拿出了怎样的“怪物”?
伴随着260亿美元计划的公开,同日,英伟达发布了迄今为止最强的开源模型——Nemotron 3 Super。
先看数据。这是一款拥有1280亿总参数,采用了目前最前沿的MoE(混合专家)架构的模型,在推理时仅需激活120亿参数。
在权威的AII指数基准测试中,Nemotron 3 Super以37分的绝对优势,力压OpenAI的GPT-OSS(33分);在专门评估智能体控制能力的新型基准PinchBench上,直接登顶全球第一。
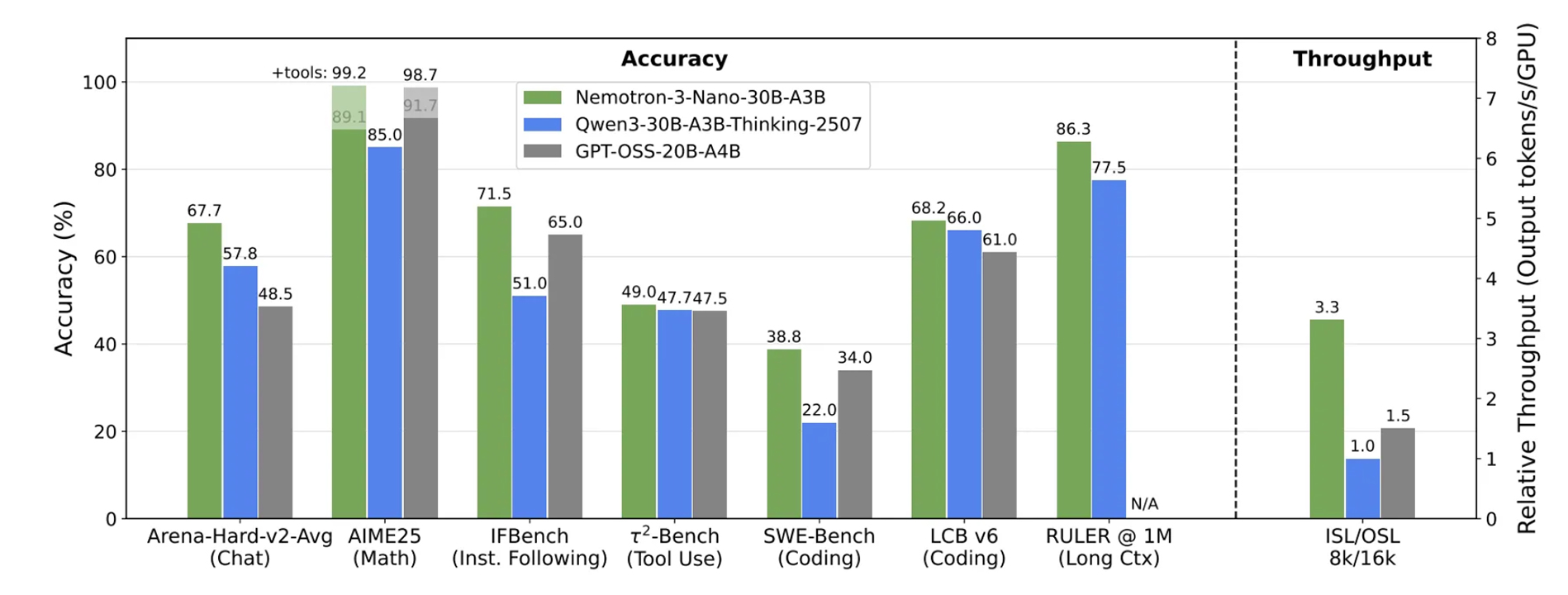
Nemotron 3 Super 基准测试领先
但这只是跑分。
1.上下文爆炸, Nemotron 3 Super原生支持100万token的上下文窗口。你可以一次性把一整条复杂的代码库,或者一部网文小说直接头尾给AI,它能保持极高的连贯性,一口气把活儿干完。
2.思考税, 复杂的AI应用在每一步都需要推理计算,如果步步都调用千亿级大模型,费用太高。为了解决这个问题,英伟达进行了底层架构创新。简单的打个比方,它就像一家拥有1280名顶级专家的医院,当一个写Python代码的病人走进来时,模型不会惊动所有人,而是精准唤醒最懂Python的那12个专家来会诊;如果是写SQL数据库的代码,就换另一批专家。这种“分诊台护士+专科医生”的模式,让它以极低的成本,实现了专业化运作。
3.多token预测,别它能在脑海里提前构思好一整句话并同步吐出,在生成代码和调用工具时,速度最高暴增3倍。
落地速度更是令人胆寒, 今天刚发布,全球顶尖的AI搜索引擎Perplexity已经将其接入,用于多智能体编排服务;西门子、Palantir更是直接将它部署到了网络安全和制造业的自动化工作流中。
02. 黄仁勋的“项庄舞剑”,意在何为
天下熙熙,皆为利来。黄仁勋为什么舍得砸出1780亿人民币做开源?
“项庄舞剑,意在沛公”。
英伟达嘴上说的是推动开源生态发展,但剥开这层温情的面纱,背后是冷酷的商业阳谋——硬件绑定。

注意一个细节,英伟达搞的叫“开放权重”,而不是完全开源。你可以免费下载它的参数权重,可以自己微调,但它是有许可限制的。
更致命,在于软硬一体的优化。Nemotron 3 Super在英伟达最新的Blackwell芯片平台上,以NVFP4精度运行的速度,是上一代Hopper平台FP8精度的足足4倍,而且精度零损失!
这就叫阳谋,我把全球最顶级的模型免费送给你用,但前提是,你想让它跑出性价比,就必须用我的GPU。
好处还不只这点,英伟达自己造最吃资源的模型,就能最先在自家模型上发现GPU的问题和瓶颈。这些用真金白银砸出来的试错数据,将直接指导英伟达下一代AI芯片的研发方向。
最后,这也是地缘政治的防守反击。在过去的一年多里,美国的科技巨头们陷入了焦虑。OpenAI、Anthropic和谷歌越来越走向封闭,导致全球无数开发者和初创企业,开始倒向免费、好用、开源的中国模型。
当Deepseek准备采用国产AI芯片,英伟达绝对不能容忍CUDA生态上的开发者流失到其他硬件平台。因此,它必须亲自下场,提供一个“美国制造”的开源替代方案,夺回开源生态的话语权。
美国的金融分析师已经算过:如果英伟达在维持硬件榜首地位的同时,还能拿下基础模型市场10%的份额,三年内有望每年额外增收500亿美元。
“舍不得孩子套不着狼”,砸下260亿,就换来每年500亿的增收和战略好处,这是黄仁勋眼里稳定不赔的买卖。
03. 对DeepSeek与Qwen的冲击
在这场发布会上,英伟达毫不避讳地将DeepSeek列为主要对手,声称新模型“足以与OpenAI、DeepSeek全面抗衡”。
我们要确认一个客观事实,国产大模型在过去一年之所以震撼全球,很大程度上建立在“性价比”和“彻底的开源”上。而现在,这两点都迎来了史上最强、最有钱的狙击手。
对DeepSeek的影响
回顾DeepSeek的崛起奇迹,DeepSeek-V3和R1模型,仅仅花了数百万美元的训练费,靠着惊艳的算法优化,硬生生逼近了OpenAI o1的世界顶尖水平。这让全世界看到了中国工程师的智慧。

但现在,坐在牌桌对面的,是一个拥有无限自有算力,且手握260亿美元预算的财阀大鳄。英伟达训练模型,不需要像DeepSeek精打细算。这种算力上的绝对富裕,是大力出奇迹的暴力压制,亦如项羽与刘邦。
不过,危机也是转机。英伟达越是将自家模型与N卡深度绑定,就越会迫使DeepSeek加速摆脱对CUDA生态的依赖,全面拥抱华为昇腾等国产硬件生态。事实上,关于DeepSeek适配国产算力集群的动作,早已在紧锣密鼓地进行中。英伟达的逼迫,只会让中国算力的底层替代加速到来。
在未来,可能形成楚汉相争的场面。
对阿里Qwen的影响
如果说DeepSeek主打的是推理和性价比,那么阿里Qwen则是目前全球开源生态做得最繁荣的。Qwen凭借全Apache 2.0的彻底开源许可,衍生模型超过10万个,在多语言支持和Agent能力上具有统治级的表现。
但企业客户是极其现实的。如果英伟达的Nemotron 3 Super能在N卡上跑出4倍的性能,很多原本使用Qwen的海外企业客户、尤其是那些有英伟达GPU的科技巨头,很可能会被分流。毕竟,原生优化的诱惑力太大了。

而Qwen的破局点在于“去英伟达化适配”和“垂直行业下沉”。英伟达的模型再强,也更偏向于通用基础。Qwen需要利用自己在中文语境、政务、金融等垂直领域的深厚积累,打出差异化。
同时,Qwen真正的开源许可,相比英伟达的限制性开放权重更高,依然会让全球的高校科研和初创公司坚定地站在它这一边。
短期来看,英伟达的入场必然会分流一部分全球开发者;但长期来看,这种中美开源的“军备竞赛”,会彻底打消中国AI产业的任何幻想,倒逼我们在算法效率和国产算力适配上,爆发出更大的潜能。
04. 结语
千淘万漉虽辛苦,吹尽狂沙始到金。
当英伟达轻描淡写地甩出260亿美元的预算时,我们不必悲观。在这个高端算力被严防死守、处处卡脖子的时代,中国的DeepSeek和Qwen们,能够凭借有限的资源,与市值几万亿美元的英伟达同桌竞技,甚至逼得芯片霸主不得不豪掷千金亲自下场防守,这本身,就是一种实力的证明。
属于中国大模型的硬仗,今天才刚刚打响。而AI产业的无限未知与惊喜,也会在这种极致的内卷与对抗中,滚滚向前。
(微信公众号:Tahou_2025)扫码下载塔猴APP,查看更多干货

