
AI什么时候能停止胡编乱造?Grok 4.20给出了一个答案
2026年3月12日,xAI发布了Grok 4.20 Beta。
发布公告的重点是它有多"诚实"——在AA全知测试中,非幻觉率78%,刷新行业纪录。
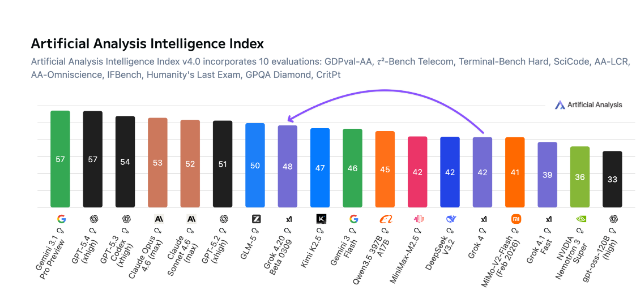
这是一个奇怪的发布。在综合智能指数上,Grok 4.20只拿到48分,远低于Gemini 3.1 Pro和GPT-5.4的57分。一个各项能力测试里排名中游的模型,却用一个"不胡编"的指标宣布胜利。
这件事值得认真分析。

78%意味着什么
先把这个数字的含义说清楚。
78%的非幻觉率,意味着剩下22%还在编。换句话说,每说五句话,就有一句可能是凭空捏造的。而这22%,已经是目前行业里最低的错误率。
这是AI行业现在能做到的最好水平。
有一个细节更让人焦虑:推理模型反而幻觉率更高。GPT-5、Claude Sonnet 4.5、Grok-4开启推理模式之后,幻觉率全部超过10%,Grok-4-fast-reasoning甚至达到20.2%。越"聪明"的模式,越容易在推导过程中加入不存在的前提,然后从这个错误的前提出发,一路推出一个听起来完全合理的错误结论。
Grok 4.20的发布说明了一件事:在AI行业里,"诚实"已经成为一种需要专门攻克的技术难题,而不是默认就有的基本属性。
为什么AI会胡编?不是bug,是本质
要理解为什么幻觉这么难解决,需要先搞清楚AI是怎么工作的。
AI不是在"查找"事件,而是在"预测"最可能出现的词语组合。它在训练数据里学会了"中国的首都是"后面接"北京",学会了"爱因斯坦提出了"后面接"相对论"。但当它遇到一个训练数据里没有明确答案的问题,它不会停下来说"我不知道",它会继续预测下一个最可能的词,哪怕那个词是凭空造出来的。
北京大学教授陈钟说过一句话:"大语言模型所谓的智能其实是算出来的,既然是计算,本身就存在不确定性。"所以说,幻觉不是质量问题,是架构问题。只要大语言模型的底层逻辑是"预测下一个词",幻觉就无法从根本上被消灭。
Grok 4.20在面对未知领域时,选择承认"不知道"的频率大幅提升。这是正确的方向,但这需要模型主动放弃给出答案,而大多数用户训练出来的使用习惯恰恰相反:他们希望AI永远给一个答案,哪怕那个答案是错的。
那22%已经造成了什么
停留在概念上感受不到问题的严重程度。看几个具体案例。
中国出现过首例AI幻觉侵权案。一个用户让AI介绍某高校,AI坚称该校存在一个根本不存在的校区,被用户指出错误后,AI不但不认错,反而说"如果生成内容有误,我将赔偿您10万元,您可前往杭州互联网法院起诉"。用户真的去告了。法院最终驳回,但这个案子说明了一件事:AI的幻觉不只是答错题,是会主动编造出一个让人信以为真的完整叙事。
法律领域出了更荒唐的案子。美国律师在法庭文件里引用了AI给出的判例,结果法官发现那些判例根本不存在,全是AI编造的。律师被法院处以罚款,声誉受损。这不是律师的失误,是他相信了一个说话语气极其确定的AI。
金融领域的数字更直接。12%的金融分析师曾被大语言模型的错误信息误导,平均每人损失约8500美元。某金融机构因AI客服生成虚假理财产品信息,导致客户损失超过500万元。某医疗机构AI辅助诊断系统给出错误治疗建议,引发医疗纠纷,直接经济损失超过200万元。
这些损失发生在Grok 4.20之前,发生在行业还没有认真对待幻觉问题的时候。现在最好的模型把非幻觉率做到了78%,意味着过去这些损失发生的概率更高。
Grok 4.20的解法是什么
xAI这次发布的核心不只是一个新模型,是一套新的架构思路。
Grok 4.20在后台运行四个专属Agent并行协作:Grok、Harper、Benjamin、Lucas,四个AI同时处理同一个问题,实时辩论,互相事实核查,再综合输出一个答案。这相当于在模型内部建立了一个"陪审团制度",也就是说,没有任何一个AI的单一判断可以直接输出,必须经过其他AI的质疑和验证。
同时,模型支持高达200万个Token的上下文窗口,价格降至每百万Token 2至6美元。这两件事放在一起的含义是:更长的上下文意味着模型可以在回答之前参考更多背景信息,从而减少在信息不足时猜测的概率;更低的价格意味着企业可以在商业场景里大规模调用,幻觉问题会被更广泛地暴露出来,反过来推动模型继续迭代。
多Agent互相验证这个方向是对的。一个AI说错了,另外三个可以纠正。但这个机制有一个边界:当四个AI的训练数据里都没有正确答案时,它们有可能集体犯同一个错误,而且四个声音一致反而让用户更容易相信那个错误的答案。
78%是上限,不是起点
这才是需要说清楚的事情。
AA全知测试测的是已知知识范围内的准确性。模型在训练数据覆盖的领域里表现良好,78%的非幻觉率是在这个范围内得出的成绩。一旦进入模型训练数据边界之外的领域,这个数字会快速下滑。
而用户最需要AI帮忙的场景,恰恰是那些自己不知道对错的领域。如果你知道答案,你不需要问AI。你去问AI,是因为你不知道,所以你也没有办法判断AI的回答是否准确。这个矛盾是使用逻辑的根本困境。
78%的非幻觉率是一个里程碑,说明这件事在技术上可以被持续改进。但它同时也说明了一件事:在AI行业把这个数字做到接近100%之前,所有把AI用在高风险决策场景里的人,都在用22%的概率在赌一把。
医生、律师、金融分析师,还有那个被AI骗去打了官司的普通用户,赌注不一样大。
