

谷歌黑科技秒杀16位!3位精度存下来 KVCache 提速4倍不费劲

最近科技圈被Google DeepMind的TurboQuant论文刷屏,其影响力甚至超过了许多模型发布本身。这篇文章揭示的技术创新,有望彻底解决大模型推理阶段最核心的显存带宽瓶颈。简单来说,他们用了一种新的数学方法,将模型对话过程中至关重要的缓存数据(KVCache)的精度,从行业标准的16-bit,硬生生压缩到了3-bit,且据称是“无损”或“低损耗”的。
模型参数的竞赛正在转向推理效率的优化。如果TurboQuant的技术能够大规模落地,它带来的提速效应将是指数级的,这对于当前因Token调用量暴涨(如阿里云/百度云涨价所反映的)而成本高企的AI服务商来说,是成本结构上的革命性利好。速度的提升,并非来自更强的计算力,而是来自更少的数据搬运量。

缓存难题
大模型聊天时,它的大脑里装了什么?
要理解TurboQuant的厉害之处,我们必须先弄懂大模型推理时那个庞大的“记忆区”——KVCache(Key-Value Cache)。
模型工作原理的类比:大模型生成一个新词(Token),需要回顾之前说的所有内容,这就像人类说话时需要回顾上下文一样。为了避免每次都重新计算历史信息,模型会将历史信息的特征数据(Key和Value向量)存入一个缓存区,这就是KVCache。话说的越多,缓存就越大,显存压力也就越大。
过去的“体积控制”方案:业界为了控制KVCache的体积,主要采用了两种策略,分别针对缓存的“长”和“高”。
- 限制“长”(上下文长度):滑动窗口注意力,简单粗暴地限制了模型能回顾的历史长度,扔掉旧记忆。
- 压缩“高”(状态大小):线性注意力技术,通过数学技巧把所有历史信息压缩成一个固定大小的隐状态,保证了KVCache的高度不会无限膨胀。
滑动窗口和线性注意力解决了“长度与状态”的问题,但它们牺牲了部分信息或精度。然而,真正限制GPU吞吐量(特别是对于H100这类硬件)的,是显存带宽,这正是TurboQuant瞄准的最后一个维度——“宽”(数据精度)。

3-bit的魔法
无损压缩精度,解放GPU搬砖时间
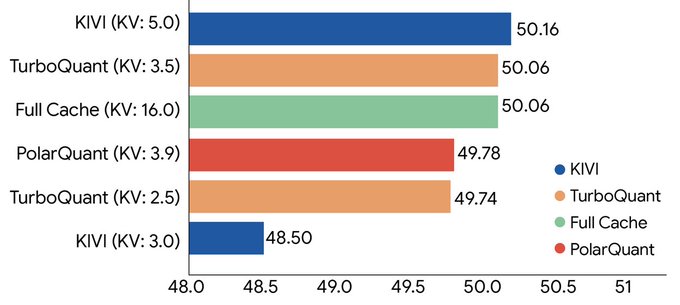
TurboQuant的核心突破在于,它找到了在保持模型输出质量的同时,将KVCache精度从16-bit压缩到3-bit的有效方法,使用了PolarQuant和QJL等新算法。
精度压缩的意义:要知道,当前许多主流模型,包括一些竞品,KVCache仍在以16-bit(FP16/BF16)的精度运行。将精度砍到3-bit,意味着模型需要读取和搬运的数据量直接缩小到了1/4到1/5。
速度提升的真正原因:带宽解放
大家可能误以为KVCache变小了,计算量也变少了,所以提速了。但并非如此,因为现代GPU的Tensor Core(如H100)原生计算精度通常是8-bit起步,更小的精度需要反量化扩充才能计算。
- 提速的奇迹发生在数据搬运环节。GPU计算本身很快,但数据必须从显存(HBM)加载到GPU内部极快的SRAM中。这个过程受限于显存带宽。
- 将数据量减少到原来的1/4,在算力过剩的情况下,省下的就是海量的“搬砖时间”。速度自然成倍飙升!
这项技术对API服务的成本结构是颠覆性的。如果小米MiMo-V2-Pro能以Claude Opus 4.6的1/5价格提供相似的Agent性能,很大程度上就是得益于其在推理效率上的优化。
我们预计,如果TurboQuant技术能与线性注意力或滑动窗口技术结合,模型的推理速度翻倍甚至更高,完全是可预期的目标。

这种技术创新,正从根本上改变云计算厂商的定价逻辑。它不再是依赖于更多GPU卡堆砌的规模效应,而是依赖于更聪明的算法来榨干现有硬件的每一滴潜力。这为云厂商在面对AI Agent导致的Token暴涨时,提供了一个极佳的降本增效工具,也预示着存储(DRAM/HBM)带宽将成为未来算力竞争的头号瓶颈。

行业影响
AI Agent的下一站:推理效率决定商业未来
TurboQuant的成功,给当前正处于Agent爆发期的市场带来了巨大的正面影响。Agent应用场景的成本曲线,我们看到,无论是小米的MiMo Claw部署,还是其他开发者在OpenClaw框架上的测试,都在追求更长的上下文和更复杂的工具调用。这些操作都是Token调用量暴涨的直接原因。

当Token消耗的成本因TurboQuant大幅下降时,Agent应用的商业可行性边界将大幅拓宽,原来因成本太高而无法大规模部署的复杂长程规划任务,将变得有利可图。
存储与计算的协同升级,存储芯片行业的火爆(DRAM、NAND闪存需求激增)与算力价格上涨(阿里云、百度云涨价)是同一问题的两面。
- 算力提升需要快速的数据存取,这意味着对高带宽内存(HBM)的需求是刚性的。TurboQuant的3-bit压缩,虽然降低了KVCache的内存占用,但对于模型本身的权重存储(HBM)和处理依然需要极高的带宽。
- 这只会让HBM等高性能存储的价值更加凸显,头部存储厂商如三星、SK海力士的议价能力将持续增强。
这项技术一旦成熟应用,将带来一个“推理效率爆炸”的时代。它将使得运行大型、复杂Agent(如需要1M上下文的金融或代码Agent)的成本大幅下降,加速AI应用对传统软件和工作流的渗透。未来,谁能最快地将TurboQuant优化集成到其MaaS平台中,谁就能在Token计费模式下获得最大的利润空间。非夕的Enlight系列更侧重于灵巧敏捷的To B场景,而Rizon系列则深耕工业稳健性。这种矩阵互补,确保了其在机器人本体领域能够全面覆盖。王世全强调,通用机器人的终局是感知、控制与决策的深度耦合,而非单一的性能突破。我们的责任是利用AI技术,将那些看似“非主流”的力觉控制,转化为下一代机器人稳定、安全执行任务的基础能力。(微信公众号:Tahou_2025)
关注塔猴公众号,回复“1”加入专属社群
扫码下载塔猴APP,查看更多干货

