

豆包每天烧120万亿Token,谁在为Agent狂热买单?


火山引擎发布的数据很直接:豆包大模型日均Token使用量突破120万亿。按国内主流模型约2至4元人民币每百万Token的输入价格估算,这每天烧掉的GPU算力成本高达3亿至5亿元。这不是什么数字游戏,这是真金白银的燃烧。如果说ChatGPT时代我们还在讨论“AI辅助”,那么现在OpenClaw等Agent(智能体)的普及,已经把AI推向了“昂贵执行力”的时代。当AI开始自主规划、调用工具、自我修正时,Token消耗量直接翻了50倍甚至100倍。我们正在进入一个算力紧缺、价格暴涨,且每个人都在为“智能执行”买单的新周期。


从“问答”到“执行”,Token消耗逻辑变了
现在的AI Agent,干活的逻辑跟以前完全不同。以前那是“一问一答”,生成几百个Token完事。现在,Agent需要思考、规划、调工具、报错后再纠错。一个复杂任务跑下来,Token消耗是普通对话的几十倍。这是豆包日调用量能翻倍、中国市场日均调用量突破140万亿的根本原因。
AI视频生成(如Seedance 2.0)和Agent自动化流,本身就是“吃”Token的大户。根据OpenRouter的统计,2026年2月全球模型消耗的Token量,是2025年同期的10倍以上。这种需求量级,正在把GPU集群变成吞噬电力的黑洞。

一年千亿级的算力支出,快赶上网易一整年的净收入了。这仅仅是一家大厂在单个模型平台上的每日消耗。当成千上万家企业将业务流接入Agent,Token的计费方式就开始展现出它的“獠牙”。以前模型是按“调用次数”买,现在模型是按“呼吸频率”计费。只要Agent在跑,后台的电表就在狂转。
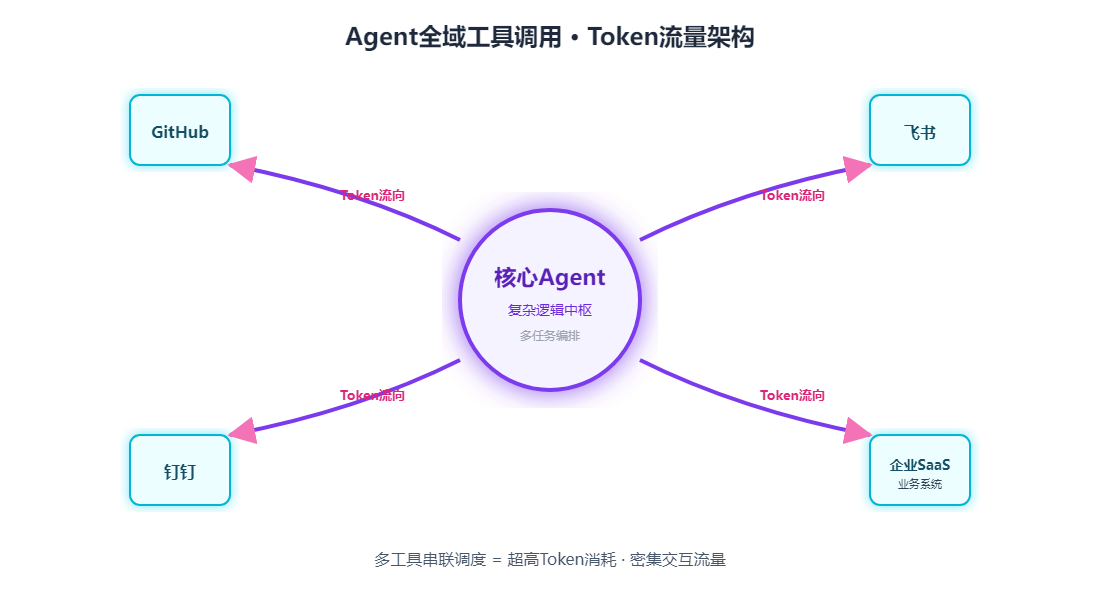

云厂商集体涨价:谁在为“算力通胀”买单?
过去云厂商靠降价抢市场的时代结束了。3月18日,阿里云和百度智能云同时宣布AI算力及存储产品涨价,涨幅最高达34%。这是供需失衡的直接结果。
为什么巨头敢集体涨价?这不仅仅是供应链成本上涨的问题,而是算力作为一种“战略资源”,已经到了供不应求的地步。
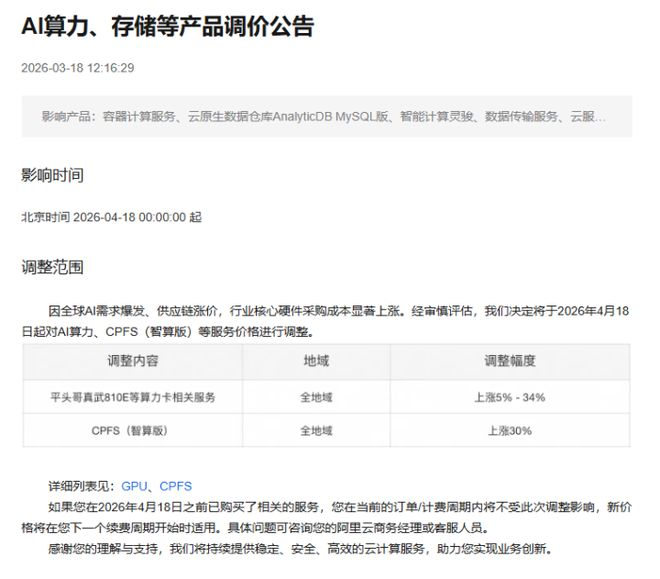
阿里云、百度智能云、腾讯云在同一个月内接连调整计费策略。
海外AWS(15%涨幅)、Google Cloud(网络服务价格翻倍)的动作更早。
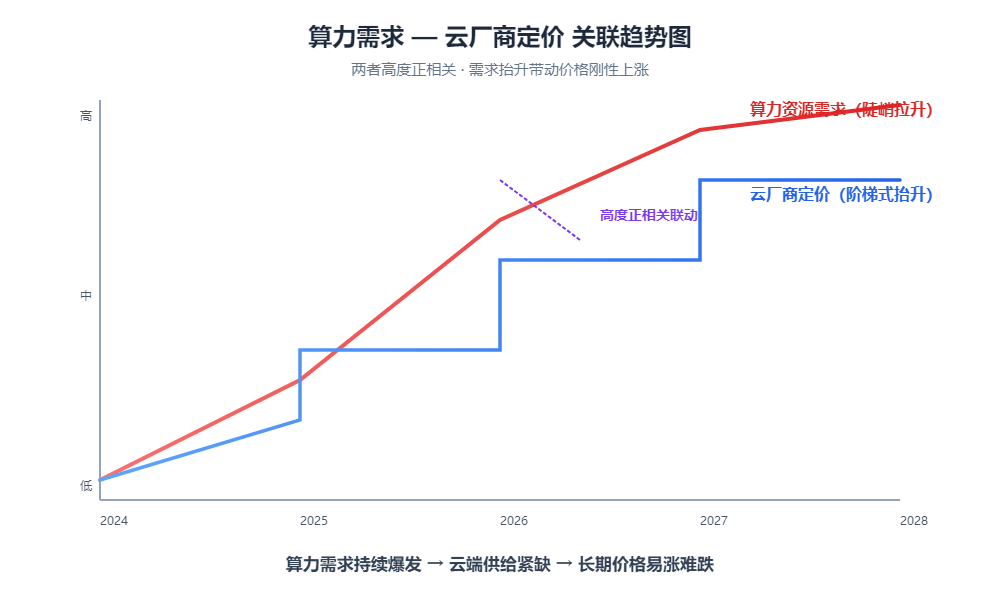
当全行业的供给侧(GPU、能源、数据中心)在短期内无法大幅扩容时,涨价是调节需求的唯一手段。
涨价清单里,除了算力卡,还有文件存储。AI模型在推理时,需要极其庞大的临时缓存。HBM和DRAM的价格波动,正成为算力涨价后的第二道关口。
注:根据Research And Markets数据,AI制药等领域的算力需求拉动了存储市场30%的复合增长,这种需求具备刚性,不易受零售端波动影响。)
这是一种必然的“成本传导”。当你的应用跑在云端,你的成本结构中,算力支出的占比将不可避免地超过人力支出。那些还在幻想算力会像过去一样不断降价的人,忽视了物理基础设施(电力和芯片)的产能瓶颈。

Agent时代的商业闭环:谁在创造真实价值?
当每天烧掉几亿元算力成本时,企业必须搞清楚:到底谁在买单?是为情怀,还是为真实利润?从“一次性买模型”到“按呼吸计费”
企业现在面临的选择:要么接受Token计费模式,要么自建模型,但后者对资金和工程能力要求极高。Agent化的工作流(如合同填写、自动化运营)如果能省下一个人力成本,那么即使Token费用上涨,企业也愿意买单。但如果在低价值、高频次、易产生“幻觉”的场景中过度使用Agent,其算力成本将迅速吞噬所有利润。
Agent能力虽强,但必须区分敏态和稳态。敏态Agent(如ArkClaw):适合作为员工创新的试验场,容错率可以适度放宽。稳态Agent:涉及财务、合同等“容错率极低”的场景,必须配合安全框架(Rules、Skills)进行精细管理,因为每一次的执行失误,都是算力的浪费和潜在的合规赔付。
AI时代的“烧钱”模式不可持续。当Token变成基础货币,任何一个不能带来直接业务收益、不能优化研发流程的Agent,都将被市场的涨价潮清洗出去。未来,能活下来的Agent,一定是那些能通过工程手段(如模型蒸馏、精细化调度)把单位 Token 的“执行回报率”做上去的产品。这场算力狂欢,最终考验的还是企业落地复杂工作流的真实水准。
关注塔猴公众号,扫码下载塔猴APP,查看更多干货

扫码加入官方社群

