

谷歌的Gemma-4-31B适合哪些人?值得你放弃Qwen3.5-27B吗?深度调研战略报告


Gemma4 31B的发布,在开源模型社区引发了巨大的关注。面对这款由谷歌DeepMind于2026年4月2日 推出的重磅模型,很多技术团队和本地部署玩家都在问同一个问题:Gemma4的出现,到底是在开辟一条新的本地部署路线,还是只是给高端玩家多了一个可选项?我们到底需不需要把现有的Qwen3.5 27B工作流整体迁移过去?

提前说初步判断:Gemma4并不是一个所有人都该无脑迁移的新标准,它更像是一个有鲜明优势、但适用场景和硬件门槛同样鲜明的技术分支。 对于绝大多数已经在私有化环境中跑通本地部署、特别是依赖长上下文与中文Agent任务的用户来说,它目前未必构成对Qwen3.5 27B的直接替代。
本文将跳出一的“跑分对比”,从模型底层定位、现实部署门槛、真实推理体验、以及与Qwen3.5的核心工程差异等五个战略维度展开深度剖析,帮你理清这笔“迁移账”到底该怎么算。
第一:Gemma4到底是什么,不是什么
在对比参数之前,我们需要先校准对Gemma4的定位认知。很多评估文章一上来就罗列参数,却忽视了谷歌推出这款模型的战略初衷。
它是一条主打“高智能密度与原生工具”的路线
Gemma4并不是一个“大而全的通吃型”模型。官方将其明确其定位为面向“高级推理与agent工作流”的底座。在架构设计上,它最大的卖点之一是提供了原生函数调用能力和结构化JSON输出支持。此外,它不仅支持文本和图像输入,还提供了可配置的“Thinking”推理模式。这意味着谷歌希望它能在复杂的API调用链条中充当“可靠的大脑”,而不是仅仅用来做闲聊。
它是谷歌对“开源商用友好”的进一步承诺
与此前部分模型采用的特定开源协议不同,Gemma4明确采用了Apache 2.0许可。这极大地降低了企业进行私有化部署和商业再分发的合规摩擦。同时,其训练数据覆盖了Web文本、代码、数学、图像等领域,数据知识截止到2025年1月,并且官方声明进行了严格的CSAM(儿童性虐待材料)与敏感信息过滤。这种详尽的安全合规叙事,非常对大企业内部审计团队的胃口。

它在家族阵列中是“求质”而非“求快”的代表
Gemma4采用“多尺寸家庭”策略。其中26B A4B是MoE(混合专家)架构,推理时仅激活约3.8B参数以换取极致的生成速度。而我们讨论的主角,31B密集版(Dense),则是为了追求极致质量与作为微调底座而生的。
说白了,Gemma4 31B不是为了在低端显卡上跑出极限速度而设计的,它是谷歌用来在30B级别硬刚“最强开源模型”王座的重装步兵。
第二:31B版本到底适合哪些人
脱离硬件谈部署,都是纸上谈兵。明确了Gemma4 31B的重装定位,我们就能清晰地划分出真实决策人群的分层。
适合:有算力冗余的本地高配玩家与企业研究者
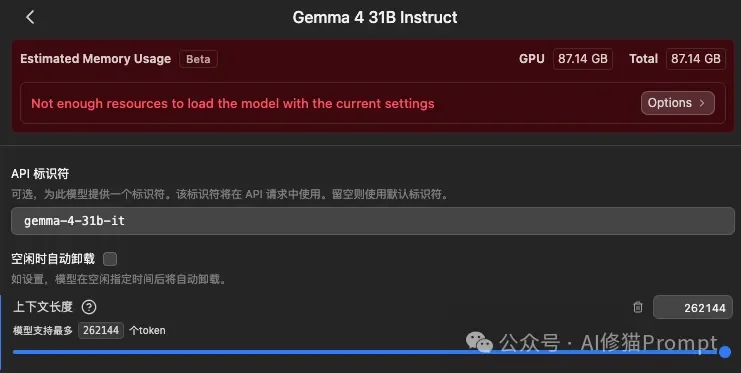
- 硬件底气:官方给出的加载显存基线显示,BF16精度需要约58.3GB显存,8-bit需要约30.4GB。如果你手握80GB级别的专业卡(如A100/H100),或者具备多卡并行环境,Gemma4 31B是一个非常优秀的通用底座。
- 需求契合:如果你追求单模型的综合对话体验、多语言写作能力,且愿意折腾最新的推理框架(如vLLM的特定镜像版本),它能给你带来极高的回报。
适合:深度依赖英文工作流与开源生态对齐的团队
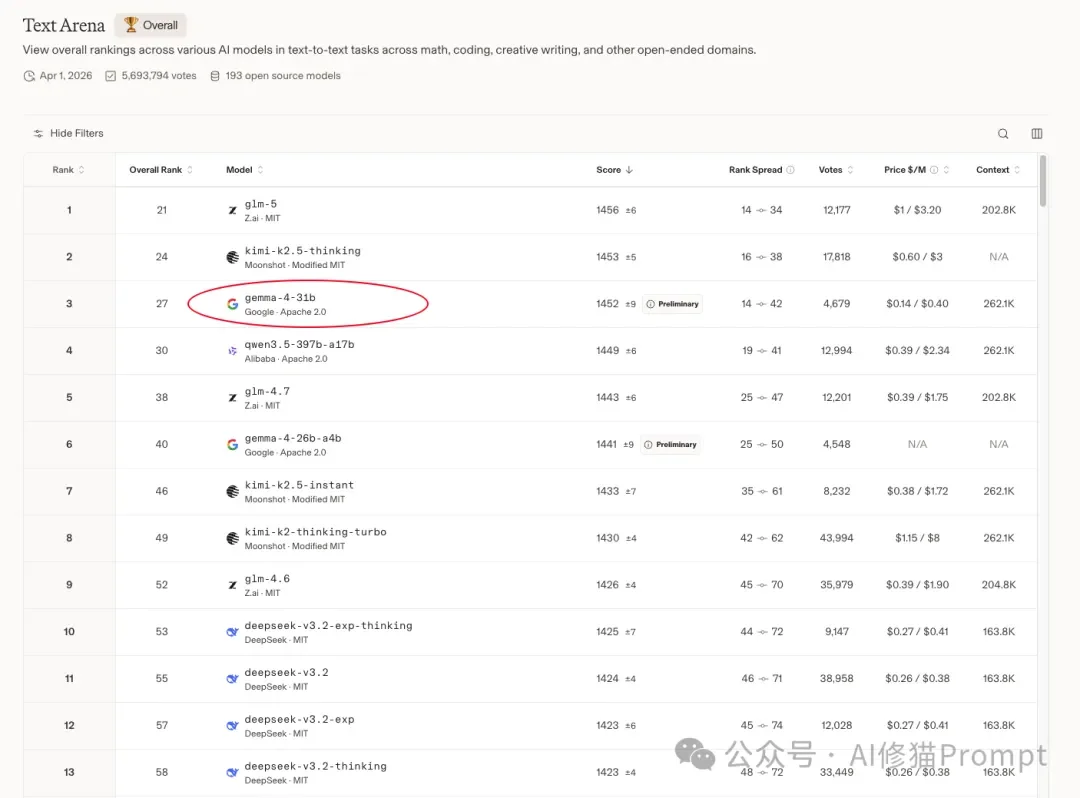
- 在第三方开放式人类偏好榜单(如Arena AI的Text Arena开源筛选)上,Gemma4 31B排名高达第3位,这表明它在开放式对战和综合偏好上表现极佳。如果你的业务以多语言(尤其是英语)为主,且看重模型生成的“人类偏好感”,它值得你投入工程资源去适配。
不适合:预算敏感、硬件一般的普通开发者
- 显存陷阱:虽然官方指出4-bit量化版本只需约17.4GB显存,看似能塞进单张24GB显卡(如RTX 3090/4090)或者Mac mini/Studio入门版。但在实际长上下文和高并发场景中,KV Cache(键值缓存)会迅速撑爆剩余显存。
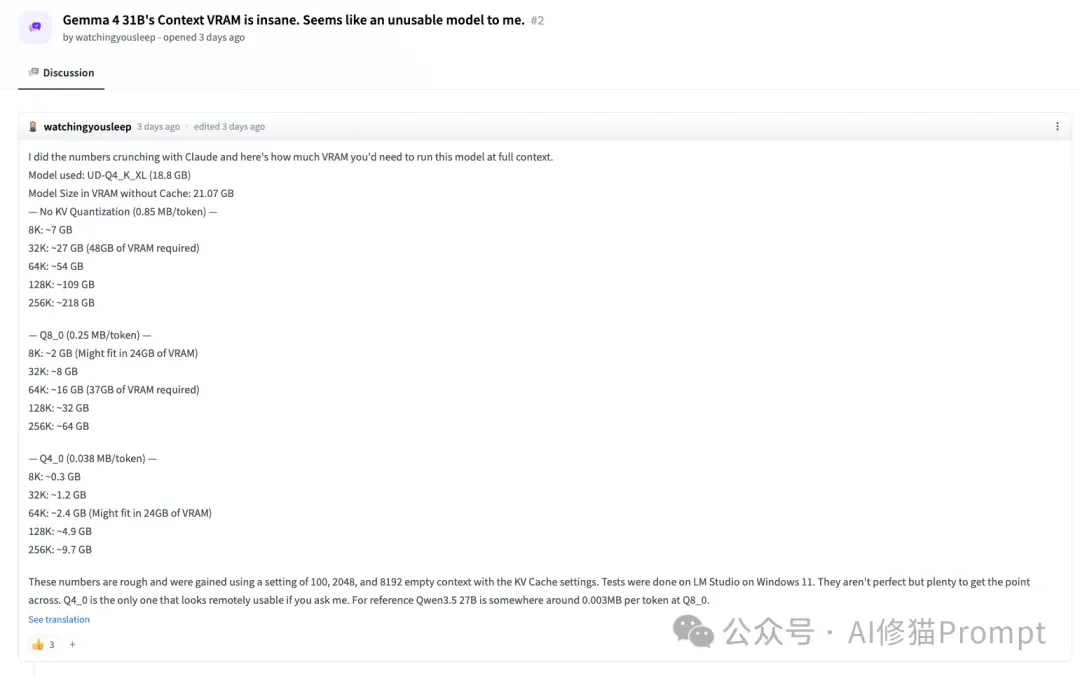
- 社区反馈:社区已经出现大量关于“即使小上下文也吃紧”、“40GB显存也难装下某些31B Q8”的抱怨。如果你没有时间去调试滑动窗口(SWA)预分配参数或尝试激进的KV压缩,强行上车31B只会带来极差的体验。模型加载是能加载,但只能开10k上下文,在Openclaw里跑一轮对话都费劲,那还有什么意义呢?
需谨慎评估:已经在Qwen3.5 27B上形成稳定工作流的人
- 如果你的系统已经基于Qwen3.5稳定运行,且核心诉求是高吞吐和长文处理,请暂时观望。切换底座意味着重新调整提示词、重新验证工具调用的JSON Schema严格性,以及面对Gemma4早期工具链的工程摩擦。
第三:Gemma4 vs Qwen3.5,到底该怎么比
对比这两个模型,不能只看榜单大乱斗,必须拆解到真正影响业务流的核心维度。
榜单和媒体不会告诉你的信息:人类偏好vs传统刷题
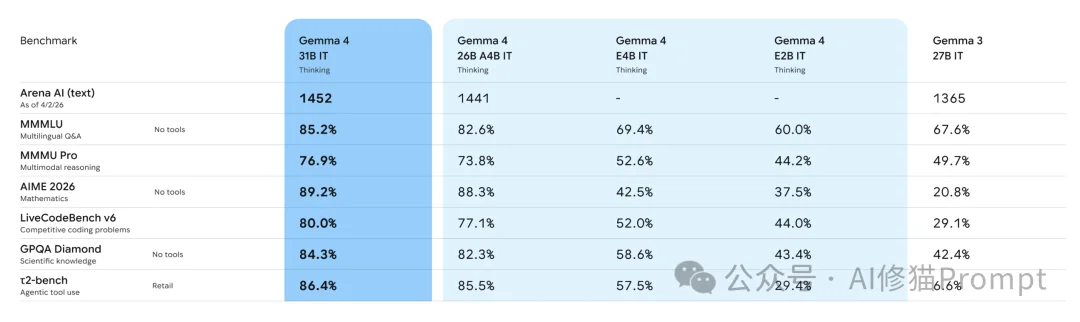
- 人类偏好:Gemma4 31B在Text Arena(Open Source)榜单中以1452左右的Elo分数位列第3,而Qwen3.5 27B仅位列第27(分数约1404)。这说明在日常对话、指令遵循的“体感”上,Gemma4更讨人类喜欢。
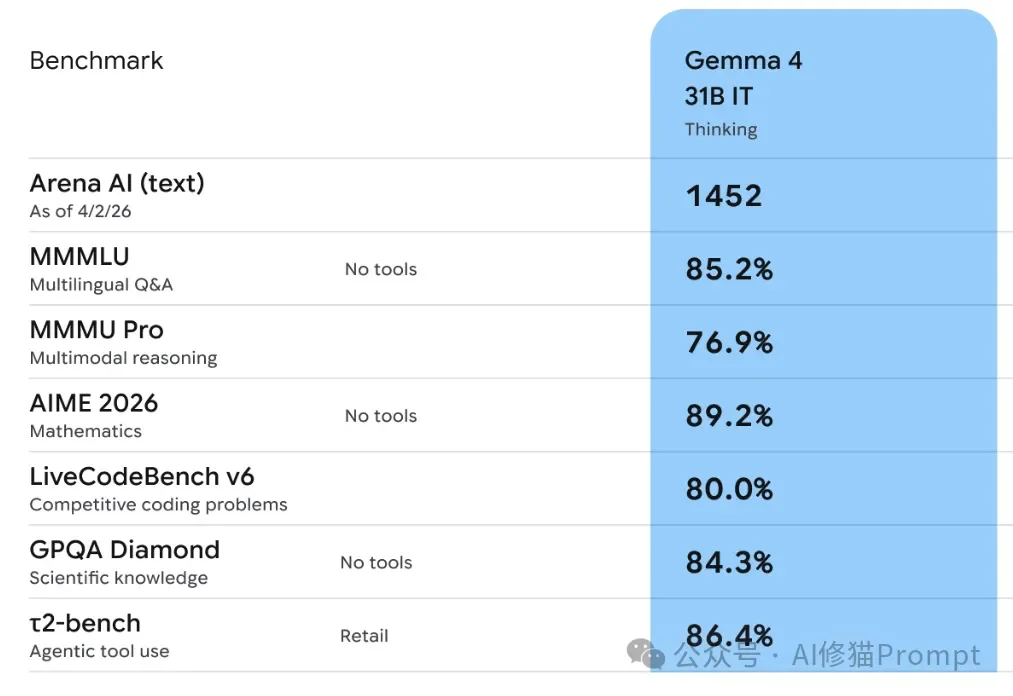
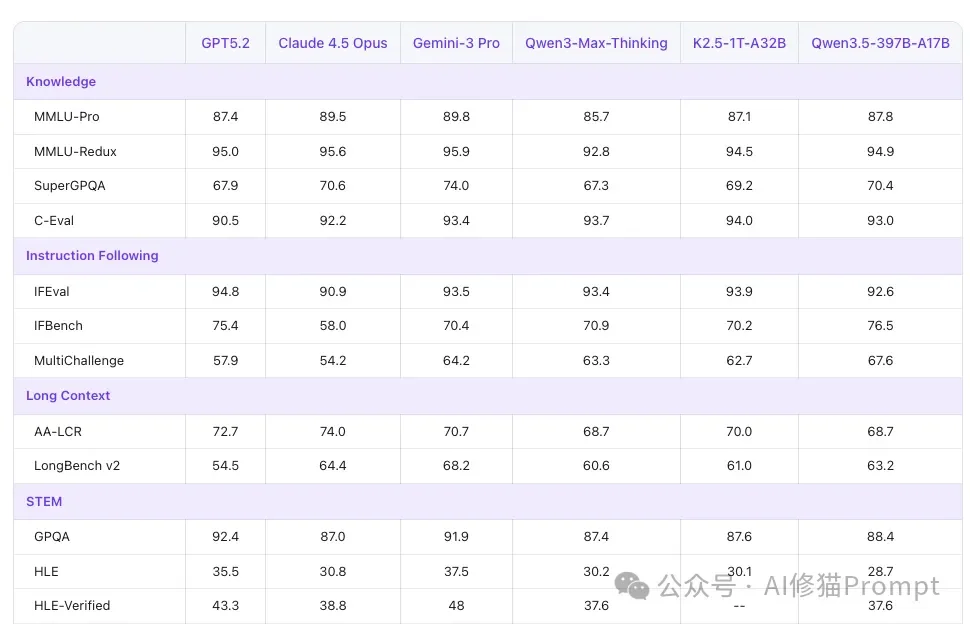
- 传统基准:但在闭卷和代码题上,格局完全不同。公开表格显示,Qwen3.5 27B在MMLU-Pro(86.1 vs 85.2)、GPQA Diamond(85.5 vs 84.3)、LiveCodeBench v6(80.7 vs 80.0)等硬核基准上,其实小幅领先或战平Gemma4 31B。
架构与长上下文:设计理念的分歧
- Gemma4的混合注意力:在60层解码器中,采用50层滑动窗口注意力(1024窗口)与10层全局注意力交织。虽然标称支持256K上下文,但其全局层的特征维度(head_dim)高达512,导致在满载长上下文时,KV Cache压力巨大。
- Qwen3.5的极致降本:采用了“Gated DeltaNet(线性注意力)+ Gated Attention(全注意力)”的混合结构。在64层中,只有16层需要传统的KV cache。官方标称262,144原生上下文并可扩展至百万级。在同样的256K压力下,Qwen的显存占用远小于Gemma。

推理效率:MTP的降维打击
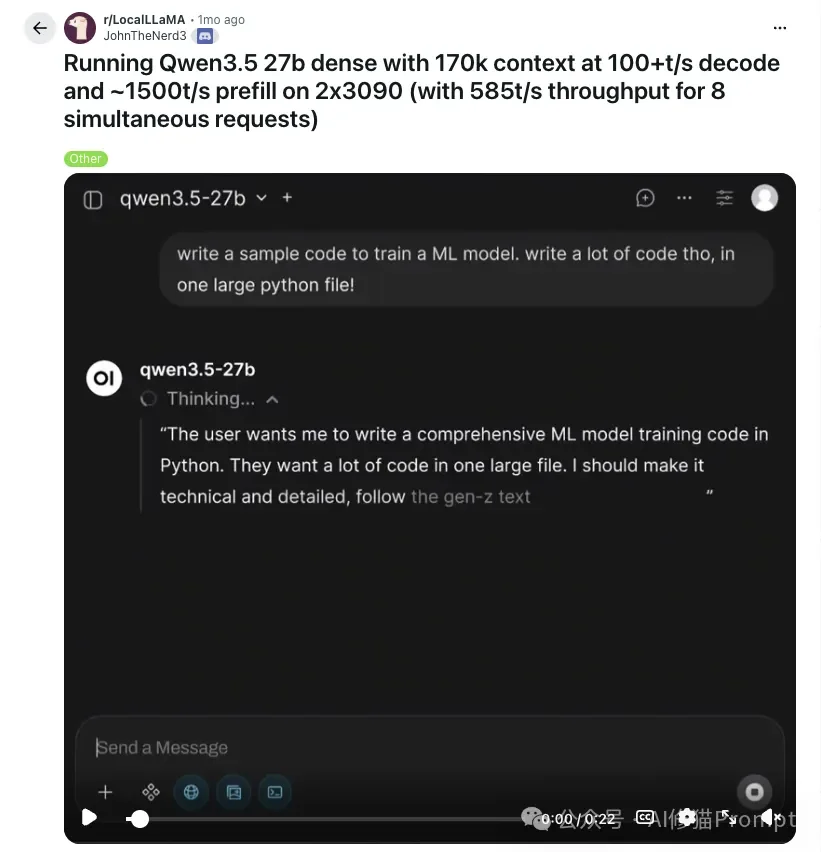
- Qwen3.5 27B明确支持了MTP(Multi-Token Prediction,多步预测)训练,结合推测解码,能在高带宽GPU上将“每步产出单token”转化为“高接受率的多token”。社区实测在vLLM上配合MTP,能跑出170k上下文decode阶段100+ tok/s的恐怖成绩。
- 而Gemma4 31B目前尚未公开确认支持MTP,吞吐上限更多依赖传统的权重量化和内核优化。
语言重心:中文专项与多语种泛化
- Qwen3.5团队长期深耕中文生态,给出了C-Eval 90.5等权威中文指标。
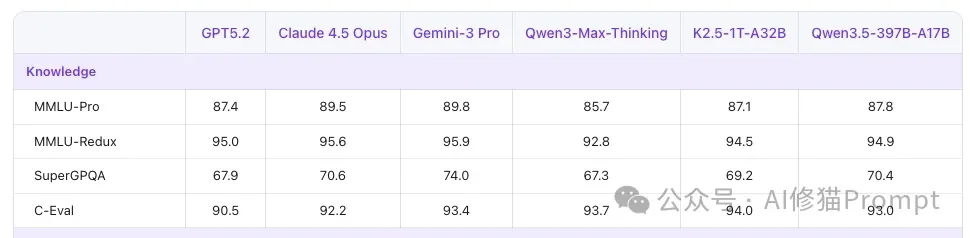
- Gemma4强调140+ 语言覆盖,但缺乏直接的中文专项对齐基准数据。在中文强需求的严肃场景中,Qwen的风险显然更低。
第四:Gemma4不如Qwen3.5的地方
作为一份战略报告,我们必须直视Gemma4 31B在现阶段的明显短板。为什么很多企业最后可能不会放弃Qwen?原因集中在以下三点:
短板一:超长上下文下的“显存黑洞”与工程波动
Gemma4 31B的256K上下文在工程落地时显得有些“脆弱”。因为其10层全局注意力的维度过大,按工程估算,在262K上下文下,其KV cache可能达到20.8 GiB的量级(保守假设)。社区真实反馈也印证了这一点:滑动窗口机制带来的SWA cache固定预分配,让很多尝试本地部署的用户遭遇显存溢出。相比之下,Qwen3.5仅需约16 GiB的KV预算,并发上限更高。
短板二:缺乏官方的“吞吐加速杠杆”
对于企业级多租户API服务或海量文档批处理,单token的推理成本是核心命门。Qwen3.5凭借极其轻量的1/4层KV需求以及官方级别的MTP(推测解码)支持,在吞吐量竞赛上占据了物理架构的先天优势。Gemma4想要达到同等吞吐,需要付出极其高昂的算力成本。
短板三:首发期的生态“阵痛”
虽然大厂模型首发即获vLLM等框架支持,但细节全是魔鬼。Gemma4独特的异构head维度和新的Transformers v5依赖,导致了诸如“特定GGUF量化在某款GPU上乱码”、“Ollama加载后跳CPU”等各种工程摩擦。而Qwen3.5在中文开发者生态内的工具链(如Qwen-Agent)已经历了充分的打磨。
第五:最终决策,是否值得放弃Qwen3.5?
基于以上调研,我们为不同类型的技术团队提供明确的迁移决策建议:
立刻尝试甚至切换至Gemma4 31B的人:
- 资源充沛的AI实验室与高端本地玩家:如果你有80GB显卡,且核心关注通用智能、多语种交叉理解以及类似人类对话的质感(高Elo偏好),Gemma4的潜力上限极高。
- 跨国业务与强英文合规团队:如果业务数据源高度依赖英文文档,且公司内部对模型训练数据的安全审核、CSAM过滤等合规叙事有严格要求,Gemma4的官方白皮书能为你省去很多内审麻烦。
坚守Qwen3.5 27B,不要轻易动摇的人:
- 中文主导业务:无论日常交互还是专业领域解析,Qwen在中文对齐上的底蕴依然是最稳的护城河。
- 极端长上下文(128K - 256K常态)使用者:处理海量财报、超长代码库的团队,Qwen的混合架构和极低KV占用是目前的最佳解。
- 硬件受限与成本极度敏感型:如果你要在24GB显卡上榨干最后一滴算力来跑并发,Qwen的MTP路线和FP8量化成熟度将救你于水火。
暂时观望,双轨并行的人:
- 复杂的Agent开发团队:双方都宣称自己工具调用极强。建议在现有服务器上拉起一个vLLM双节点,跑一套A/B测试。用你们真实的业务Schema去压测两者的JSON输出失败率,让数据说话。
结论
Gemma4 31B绝不是“Qwen3.5时代的终结者”,而是一个在通用偏好和多模态协议上极具吸引力,但在长上下文显存调度上依然昂贵的“偏科优等生”。对于大多数已经跑通Qwen3.5工作流的国内团队来说,Gemma4目前更像是一个“值得高度关注并小规模评估的备用引擎”,而不是一个“必须立刻倾囊迁移的终极答案”。
文章来自于"AI修猫Prompt",作者 "AI修猫Prompt"。
