
让开发者喊出惊人速度的Kimi K2.6要来了?


月之暗面的动作很快。Kimi K2.6-code-preview 的预览版刚一放出,就成了开发者群里的热门话题。从Reddit社区的实测来看,这次更新最核心的感知在于“快”,响应速度从上一代的1分钟级直接压缩到了5秒。在AI Agent领域,5秒的响应意味着它真的能成为你工作流里的“实时搭档”,而不是一个让你边等边刷手机的聊天工具。结合 GLM-5.1 和 MiniMax-M2.7 的布局,国产模型在智能体方向的竞争,已经从参数博弈彻底转向了“工具调用效率”和“长程任务稳定度”的硬核较量。
Kimi 这次发力,精准踩中了 Agent 时代最痛的脉点——TTFT。在复杂的 Agent 编排中,如果模型不能在几秒内完成工具决策和调用,整个工作流就会卡住。这波更新是在向所有开发者证明:国产模型不仅能写代码,更能跑通复杂的工程闭环。

性能跨越
不是简单的提速,是工具调用的“生死时速”,为什么 K2.6 的速度提升让开发者觉得“惊人”?在 AI Agent 的实战环境下,速度不仅仅是体验问题,它是决定这个 Agent 能不能用的生死线。
Reddit 用户反馈非常直接:以前 K2.5 在 OpenClaw 框架下处理任务,响应时间往往在 1 分钟左右,这对于自动化任务来说长得不可接受。现在 K2.6 压缩到了 5 秒。

这意味着什么?在自动化的场景中,5 秒钟是人类等待的忍耐上限。超过这个时间,开发者往往会觉得“它是不是卡死了”,从而产生手动干预的冲动,这会破坏整个自动化工作流的连续性。
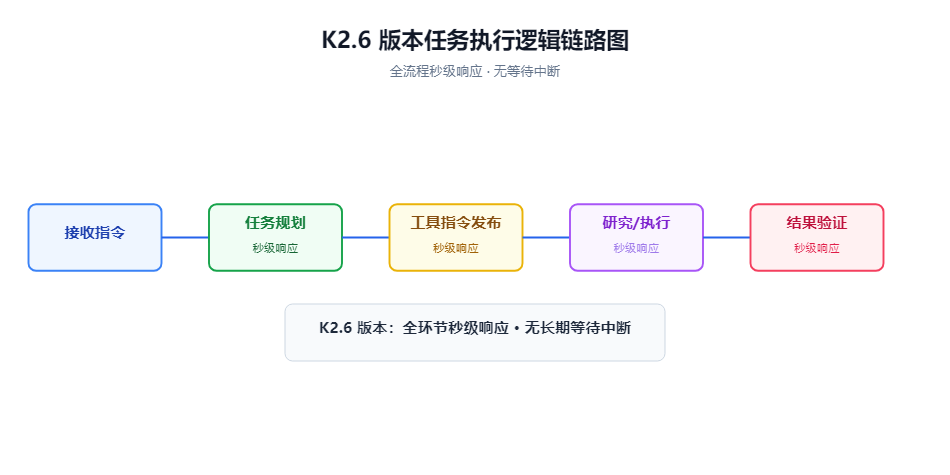
更关键的不是生成文字的速度,而是“工具调用”的爆发速度。模型发出调用指令的速度从分钟级降到秒级,直接让多步骤任务的编排成为了可能。
有开发者测试了“深入研究(Dig Deep)”功能,反馈 K2.6 对“清理依赖地狱”这类复杂任务的执行力远超以往。

它不是简单地吐出几行代码,而是真的开始进行长达十分钟的底层研究。以前 K2.5 在同样的任务下,往往几分钟后就给出浅薄的回答;现在 K2.6 则表现出一种“不搞定誓不罢休”的工程韧性。
Claude Code 曾经定义了这种深度研究的预期,但现在看来,国产模型正在通过这种“极致响应”的工程优化,强行把标准线拉高。这不是模型变聪明了多少,而是模型在执行指令时的“工程执行力”变强了。

赛道分化
三家巨头的Agent进化论:路径不同,目标一致,目前国内大模型阵营在 Agent 能力的打磨上,走出了三条截然不同的技术路线,这也预示了他们各自瞄准的落地场景。
GLM-5.1:模拟操作系统的路线
GLM 系列展现出的是一种“桌面操作系统”的构建逻辑。
他们的 Demo 展示了模型直接撸出一个包含整个桌面 UI、模拟各种桌面 APP 的环境。这走的完全是“操作系统模拟器”的路子。
这种路径的优势在于:它试图完全替代人的交互界面,让 Agent 像人类一样在桌面上“点点点”。
MiniMax-M2.7:Skill 协同的RL强化路线
MiniMax 则走了另一条路:基于 20 个 Skill 的协同工作,并配套了专门的强化学习框架。
他们更看重 Skill(技能模块)的复用性。通过本地记忆(通常基于 Markdown 文件存储)来不断优化 Agent 的决策性能。
这种逻辑适合流程极其复杂、要求极高可控性的企业内部流程自动化。
Kimi K2.6:重压效率,冲击工程流
Kimi 的路径非常务实:围绕 Agent 框架(特别是对 ClawBench 的适配)做极致的性能调优。
K2.6 追求的是在现有的开发框架下,跑得最快、响应最稳。
这本质上是把开发效率提升到了战略高度,旨在通过解决“延迟感”来留住那些极度挑剔的程序员。
三家路径清晰。GLM 在做“系统模拟”,MiniMax 在做“技能编排”,而 Kimi 在做“开发效率的统治者”。谁能在今年下半年解决“多模态 Agent 预填充速度”这一底层问题,谁就能拿到下一代 AI 操作系统的入场券。

ClawBench陷阱
不要为了刷榜而优化,尽管 K2.6 在 ClawBench 上表现优异,但我们必须对该评测标准保持警惕。
ClawBench 目前的任务集存在大量重复的通信类任务(比如邮件沟通)。在国内,真正的高效打工人极少用邮件沟通。这就导致了该评测结果可能存在“偏科”。只盯着 ClawBench 优化,容易导致模型在处理真实代码库时偏离方向,过度拟合那些单一且高频的 Agent 场景。
我们真正需要看的是模型在那种“充满了老旧债务代码、复杂依赖关系”的真实项目仓库中的表现。能否处理那些没有文档的老旧模块?能否在大型代码库中快速定位跨文件的影响范围?这才是衡量一个模型是否真的能替代初级工程师的标准。如果你是一个想要应用 AI Agent 的公司,不要只看榜单排名。带上你公司自己最复杂的代码库去跑一下,那才是最真实的“体检单”。K2.6 的这次更新,给出了一个很棒的工程模板,但行业要警惕“Benchmarking 陷阱”,别让跑分掩盖了业务实践中的真实断层。
关注塔猴公众号,扫码下载塔猴APP,查看更多干货

扫码加入官方社群

