
国产编程AI天花板Qwen3.6-35B VS Gemma4


阿里新出的 Qwen3.6-35B-A3B让编程AI赛道彻底不一样了。不只是一个参数更新,这是国内大模型在编程和智能体能力上的极限施压。在SWE-bench和Terminal-Bench 2.0这类实打实的工程代码测试里已经表现出能够压制一众国际模型的态势。抛开官方华丽的柱状图直接拆解其 benchmark 数据,会发现一个明显的转折点那就是大模型正在从储存变成执行。对于靠写代码或写脚本谋生的技术人这说明着手里那把AI刷子的成色需要重新评估了。

参数大小不是第一指标
最开始都在猜 K2.6-code-preview会发什么,没想到这次更新把编程能力拉到了天花板。这次评测的核心是能不能在终端里把任务跑完。Coding Agent能力的硬核指标Qwen3.6-35B在编程任务测试(如Terminal-Bench 2.0、Claw-Eval)中拿到了第一。这些任务的特征就是不讲废话要求直接操作终端环境。要求模型必须理解文件结构、环境依赖、编译过程。以前的模型经常在环境操作阶段卡壳,是因为看不见操作后的反馈或者反馈了也理解不了。
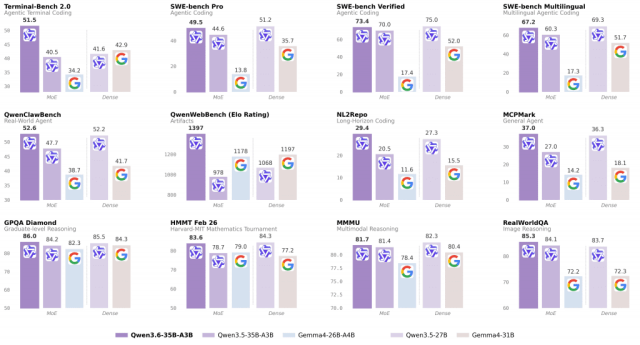
编程是最考验Agent执行力的场景,代码必须精确。如果模型在生成代码时出现了逻辑跳跃,编译器就会直接报错。因为这种严格的纠错环境,所以那些能够在Claw-Eval这种任务里拿高分的模型,在其他任务处理上通常也不会差。

路线转向
目标是彻底替代人的交互。MiniMax-M2.7则在玩Skill协同。他们建立了一个基于本地记忆库的强化学习框架,允许 20 个 Skills 在同一个任务下协同。这种路径适合极度复杂的业务自动化(比如ERP系统集成)。 Kimi K2.6的逻辑是极致效率。专注于编程环境的优化通过减少不必要的Token消耗,可以把模型变得精而快。开发者发现盲目给AI喂资料是没用的。K2.6证明了,真正的Agent能力来自于对工具调用协议的深度集成。通过对ClawBench这一类 Agent评测框架的适配,可以让模型在处理长链任务时,知道什么时候该调用搜索,什么时候该执行代码。模型聪明底层的调用逻辑也是很重要的。

国产大模型的竞争已经进入了拼工程能力的阶段。谁能让模型在调用工具时少犯错,谁就能留住开发者。那些盯着ClawBench刷分的策略,在长远来看会有风险过于拟合单一任务指标,往往会牺牲模型在数学和基础逻辑上的广度,这波编程场景的内卷,正是现阶段能最快带来商业价值的正道。

不被参数规模迷惑
不再被参数规模所迷惑。Qwen3.6-35B的出现,是在告诉市场35B这种体量的模型,如果优化到位完全可以吊打过去100B+的重型模型。ClawBench SWE-bench这些评测数据不错,但反映的是一种实验室环境。真实的工程环境比这些Benchmarks杂乱得多。代码里充满了乱七八糟的历史债务、没有注释的遗留逻辑,以及各种不规范的命名规则。要看模型强不强就得把它们拉到真实的屎山代码里跑一跑,能不能在不破坏现有功能的前提下修好一个Bug,这才是开发者认定的天花板。本地化部署和远程API调用的混合开发范式,将成为未来一年AI软件研发的主旋律。
阿里这次的发布,算是一个非常强烈的行业信号编程已经成为AI Agent的第一战场。大家都不再藏着掖着了谁能把这一套工作流磨得最顺畅,谁就先跑向了未来软件工厂。

