
不换模型,性能涨了39%:让AI智能体自己修bug的开源方案来了



NeoSigma 团队今天开源了一个叫 auto-harness 的系统,核心做的事只有一件:让智能体自己发现自己的 bug,自己修,自己验证。
不换模型、不加参数、不手动调优。在 Tau3 基准测试上,验证分数从 0.560 一路爬到了 0.780,提升了 39.3%。靠的不是更强的模型,而是一套闭环的自我改进机制。
这件事为什么值得关注?因为它回答了一个很多做智能体开发的人都在头疼的问题:上线之后怎么办?
我自己做智能体产品的过程中深有体会——搭原型很快,但上线之后的维护才是真正吃精力的地方。用户一多,各种边界情况就像地鼠一样冒出来,打完一个又来一个。
01 真正的瓶颈
现在做智能体,写代码本身已经不是最难的了。大模型写代码越来越强,原型搭起来很快。但真正让团队头疼的是:上线之后,智能体开始在真实数据上跑,各种奇怪的失败就冒出来了。
而且这些失败有个特别讨厌的特点——随机、难复现、分布依赖。你改了一个提示词,下游行为可能完全变了。你换了一批输入数据,之前没出过的问题突然就出了。
这就像你养了一只会说话的鹦鹉,但你永远不知道它下一句会蹦出什么。
传统的做法是:人工排查日志,手动分类失败原因,写新的测试用例,改提示词或者工具接口,再跑一轮验证。这个过程通常需要资深工程师花几天时间,而且很容易修了一个 bug,又引入另一个。这种「打地鼠」式的维护方式,在智能体时代是不可持续的。
更糟糕的是,很多失败之间存在隐藏的关联。表面上看是三个不同的 bug,深入分析可能发现根因只有一个——比如上下文窗口里塞了太多无关信息,导致模型在不同任务上都出了偏差。如果你一个个 bug 去修,可能越修越乱;但如果能从根因入手,一刀就能解决一片问题。
NeoSigma 的想法很直接:既然大模型能写代码,为什么不让它自己来完成这个调试循环?
02 四步闭环
auto-harness 的核心是一个四阶段的自我改进循环,每个阶段都是自动化的:
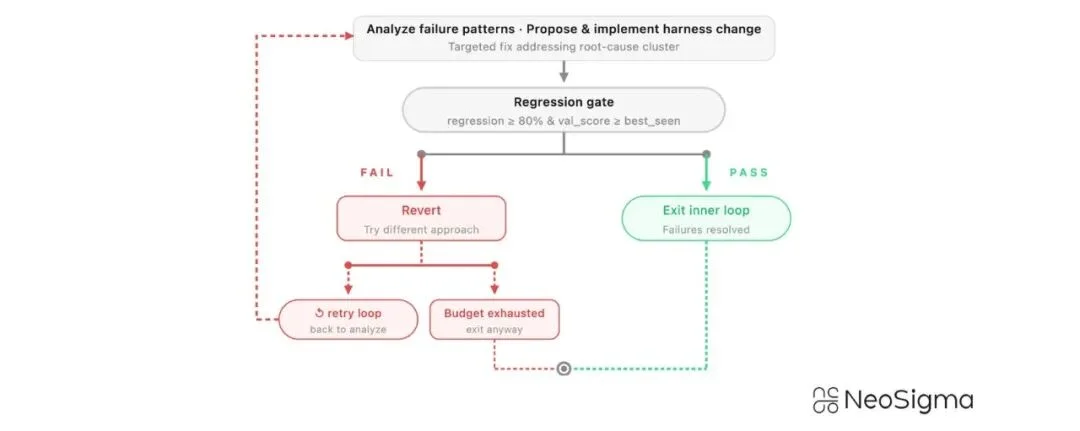
auto-harness 的优化循环:分析失败模式 → 回归门控 → 通过则保留,失败则回退重试
第一步:失败挖掘。系统从生产环境的运行日志中提取失败案例,不是简单地看「成功/失败」,而是深入分析执行轨迹,找到到底在哪一步、因为什么原因出了问题。
第二步:根因聚类。把挖掘出来的失败按照根本原因进行分组。比如有 10 个不同的失败案例,可能归根结底是 3 种根因。系统自动识别这些模式,按复现频率排优先级。
第三步:定向优化。针对每一类失败,系统自动提出修复方案——可能是改提示词、改工具接口、改上下文构建方式、改工作流设计。然后在回归测试集和验证集上跑验证。
这里有个关键机制:80% 回归门控。每次修改必须保证之前已经修好的问题不会重新出现。如果回归测试通过率低于 80%,这次修改直接打回,换个方案重来。
这一步特别像人类工程师做代码审查:改完跑测试,测试不过就不许合并。只不过这里的「审查员」也是 AI,而且它比人类工程师更耐心——可以 24 小时不间断地跑验证。
第四步:回归套件维护。每一个被成功修复的失败模式,都会被转化为永久性的回归测试用例,加入到测试套件中。这样,测试覆盖面会随着系统运行越来越广。
换句话说,系统不只是在修 bug,它是在一边修 bug 一边给自己写考题。
03 实验数据
NeoSigma 在 Tau3 基准测试上跑了完整实验。Tau3 是一个专门评估智能体在复杂任务上表现的测试集,包含多步推理、工具调用、信息整合等多种能力考核,难度不低。很多在简单任务上表现不错的智能体,到了 Tau3 上就会暴露出各种问题——因为真实世界的任务往往不会按你设想的路径走。
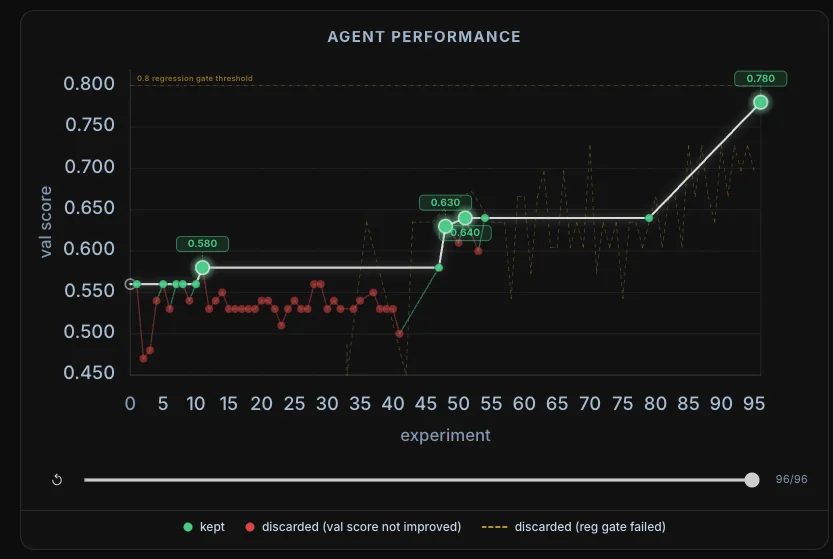
96 轮实验的性能曲线:绿点为保留的改进,红点为被丢弃的尝试,最终从 0.56 攀升到 0.78
先看结果:
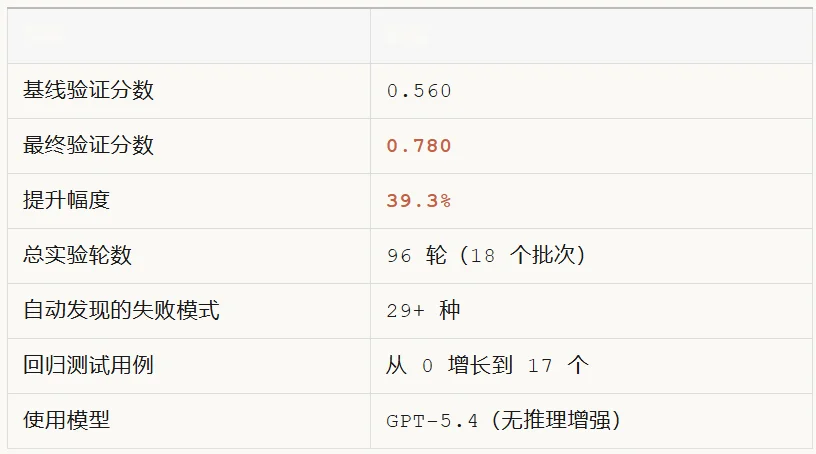
注意最后一行:模型没换。全程用的是同一个 GPT-5.4,而且没开推理模式。所有的提升都来自系统层面的策略优化。
这很反直觉。大部分人的第一反应是:性能不够?换个更好的模型。但 NeoSigma 的实验证明,在同一个模型上,光靠优化提示词、工具接口和工作流设计,就能把分数拉高近 40%。
另外还有两个数字值得关注:29 种以上的失败模式是系统自动发现的,回归测试套件从 0 增长到了 17 个。这意味着系统不仅在修复问题,还在不断扩大自己的「视野」——它能看到的问题类型越来越多,防御的范围也越来越广。
04 曲线背后
看那张性能曲线图会发现一个有意思的细节:红色的点远远多于绿色的点。
96 轮实验里,大部分尝试都被丢弃了。有些是因为验证分数没有提升(红色实心点),有些是因为回归门控没过(虚线标记)。真正被保留下来的改进(绿色点),只是其中一小部分。
这恰恰说明了这套系统的价值:它不怕试错。人类工程师一天能手动尝试几个方案?5 个?10 个?这套系统跑了 96 轮,每一轮都有完整的验证和门控。
从曲线上还能看到几个关键跃升点:第 10 轮左右从 0.56 跳到 0.58,第 45 轮突破 0.63,最后在第 90 轮以后出现了一次大幅跳跃,直接拉到了 0.78。
这种「台阶式上升」在优化问题中很常见——系统可能在很多轮里都在积累小的改进,直到某一次修改恰好解决了一个核心瓶颈,性能就会突然跳一个台阶。
这也意味着,如果你只手动尝试了 10 种方案就放弃了,可能恰好错过了第 11 种方案带来的突破。而机器不会放弃,只要预算还在,它就会继续试。
另一个值得注意的点:被丢弃的「失败尝试」并不是浪费。每一次失败的修改都会留下记录,系统可以从中学到「这条路走不通」,从而在后续迭代中避开类似的方向。这跟人类工程师积累经验的过程是一样的——只不过机器积累的速度快得多。
05 改的是什么
具体来说,auto-harness 在 96 轮实验中改了哪些东西?根据博客的描述,改动涵盖了智能体系统的几乎每一层:
提示词优化——调整给模型的指令措辞,让它更精确地理解任务要求。这是最直观的一层,也是很多人手动在做的事。但手动调提示词是个反复试错的过程,auto-harness 把这个过程自动化了。
工具接口改造——智能体调用外部工具的方式。比如参数格式、返回值处理、错误处理逻辑。这些细节对最终表现的影响往往比人们想象的要大得多。
上下文构建策略——给模型看什么信息、看多少信息、以什么顺序呈现。这是个非常微妙的工程问题,信息太少模型缺乏判断依据,信息太多又会淹没关键线索。
工作流设计——智能体执行任务的整体流程。先做什么后做什么,什么时候该调用工具,什么时候该自己推理。
简单来说,模型不变,变的是模型周围的一切。
这个思路其实很有启发性。我们平时总习惯把智能体的表现好坏归结于模型本身的能力,但实际上,「包装层」的质量同样关键。同一个模型,给它好的提示词、好的工具接口、合理的上下文管理,和随便配置一下,表现差距可以非常大。auto-harness 的实验数据(39.3%的提升)就是最好的证明。
06 活的测试集
这套系统里有一个设计我觉得特别巧妙:回归测试套件是「活」的。
传统做法是:开发前写好测试用例,然后在开发过程中验证。测试集是固定的,你得事先想好要测什么。
但 auto-harness 的测试集是从真实失败中长出来的。每修好一类 bug,就多一组测试用例。在 Tau3 的实验中,回归套件从 0 个用例增长到了 17 个,而且每个用例都对应一类真实存在过的失败模式。
这就像一个老中医,每治好一种病就把症状和药方记下来。看的病人越多,经验手册就越厚,误诊的概率就越低。
而且这些测试用例不只是检查「能不能通过」,它们还充当了安全网:任何新的修改,都必须先过回归门控。80% 的通过率是硬性要求,低于这个数就打回重做。
使用这套系统的感觉,就像是从被动调试变成了一个会自己进化的系统。——Chirag Mahapatra,Mercor
07 为什么不直接换模型
你可能会问:费这么大劲优化系统层,为什么不直接用个更强的模型?
这是个好问题。答案有三个层面:
第一,成本。更强的模型通常意味着更高的推理费用。而且在很多场景下,差距没有你想象的那么大——一个调优好的弱模型,往往能打过一个配置粗糙的强模型。NeoSigma 用的是 GPT-5.4 不带推理增强,这已经是一个性价比很高的配置了。
第二,可控性。换模型是个非常粗粒度的操作——你没法精确控制它会改善哪些行为、同时可能损害哪些行为。而系统层的优化是精准的:针对特定的失败模式,做定向修复,然后验证不会引入新问题。
第三,可叠加。系统层的改进和模型升级并不冲突。你可以先用 auto-harness 把当前模型的潜力榨干,等新模型出来了,再叠加上去。这两条路是互补的。
打个比方:换模型就像给车换一台发动机,而优化系统层就像改进变速箱、悬挂和空气动力学。发动机当然重要,但如果传动系统效率只有 60%,你再强的发动机也有 40% 的力被浪费掉了。auto-harness 做的就是把传动效率往上拉。
08 开源了
值得一提的是,auto-harness 是完全开源的。代码在 GitHub 上,任何人都可以拿去用。
对于正在做智能体产品的团队来说,这是一个可以直接接入的工具。你有一个在跑的智能体,把 auto-harness 接上去,它就开始自动分析失败、聚类根因、提出修复方案、跑验证。整个过程不需要你手动干预。
当然,开源不代表拿来就能用。你需要根据自己的智能体架构和任务类型做适配。但核心的思路——失败挖掘、根因聚类、定向修复、回归门控——是通用的,不管你用的是什么模型、做的是什么应用。
从推文里 Gauri Gupta 的描述来看,NeoSigma 团队的目标不只是这一个工具,而是构建一整套让智能体自我改进的基础设施。auto-harness 是其中的第一个开源组件。
09 对我们意味着什么
如果你在做智能体相关的产品或服务,这套东西的启发至少有三点:
1. 不要只盯着模型能力。同一个模型,系统层面的优化空间可能比你想象的大得多。NeoSigma 在不换模型的情况下拉了 39.3% 的性能,这个数字很能说明问题。
2. 把失败当资产。每一次失败都是改进的原材料。如果你的系统没有在系统性地收集和分析失败数据,你就是在浪费最有价值的信号。
3. 回归防护不是可选的。auto-harness 的 80% 回归门控看起来是个小细节,但正是这个机制保证了系统在进步的同时不会倒退。很多团队改完一版反而更差了,就是因为缺少这层保护。
这三条原则说起来简单,但真正能做到的团队不多。大部分团队还停留在「出了问题手动查日志」的阶段,甚至连系统性的失败收集都没有。更别提自动化的根因分析和定向修复了。
软件工程的历史告诉我们,成熟的工程实践最终都会走向自动化。单元测试自动化了、部署自动化了、代码审查也在逐步自动化。现在轮到了智能体系统的调试和优化。
auto-harness 做的,就是把这件原本只有资深工程师才能干的事,变成了一个可以 7x24 小时自动运转的闭环系统。
而这件事的本质,是让 AI 自己负责自己的质量。
我最近在想一个问题:现在大家都在谈「智能体」,但大部分所谓的智能体其实是一次性的——你给它一个任务,它执行完就结束了。真正值得兴奋的,是那些能在运行过程中不断变得更好的系统。auto-harness 让我们看到了这种可能性的一个具体实现。
从「能跑」到「跑得好」,再到「自己越跑越好」——这中间的每一步跨越,难度都是指数级增长的。NeoSigma 至少在第三步上给出了一个可行的方案。
相关链接:
• GitHub:https://github.com/neosigmaai/auto-harness
• 博客:https://www.neosigma.ai/blog/self-improving-agentic-systems
• 推文:https://x.com/gauri__gupta/status/2040251170099524025
数据来源:NeoSigma AI Blog, Gauri Gupta / Ritvik Kapila
文章来自于"深思SenseAI",作者 "深思SenseAI"。
