

国内顶尖机构揭露:大模型只是在假扮主治医生


当我们使用大模型(ChatGPT)时,经常会输入这样的指令,“你现在是一名经验丰富的主治医师,请根据病历给出最肯定的诊断”。
但看似专业的语气背后,真的有医生级思考吗?
中国顶尖机构联合研究,在采用神经元消融这一尖端技术后,得出了结论。
医疗大模型的角色扮演,只改变了语言风格,却没有带来任何认知差异。换句话说,你的角色提示词并未增强AI的推理能力,不过是让AI披上了表面华丽的手术服。

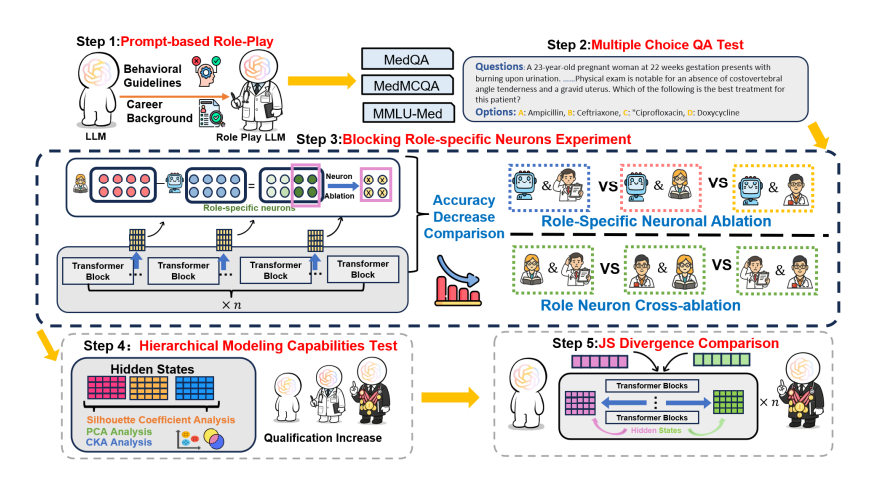
首次“解剖”大模型的角色神经
提示词中的角色扮演是目前医疗大模型中最常用的增强技巧,简单概括就是让模型以实习医生、主治医生或外科专家的身份回答问题,提升专业性。
但这一做真的改变了模型的推理结构吗?
研究团队指出在临床决策中,不同层级医生拥有显著差异的思维模式。
实习医生属于记忆回忆型,主治医生属于概率整合型,专家属于启发式风险校准,而且这些差异在人类神经层面可被观测。
为此,研究团队用神经元消融(Neuronal Ablation)的方式追踪不同角色提示下模型的内部变化。
先比较带角色提示与无提示状态下的神经元激活差异,识别出所谓的角色敏感神经元;
再将这些神经元删除,观察模型答题准确率是否下降;
如果模型真存在角色专属思考路径,删除后性能应显著下降。
结果却让研究者意外,无论删除哪个角色对应的神经元,模型准确率几乎相同(差异<2%)。这说明角色提示并未构建出独立的推理回路,只是调节了语气与用词。
语言在变,思考没变
研究团队在三个医学数据集(MedQA、MedMCQA、MMLU-Med)上,对Qwen2.5系列、GPT-4o与DeepSeek-R1共六种模型进行对比。
结果一致:
准确率无显著差异,专家医生模式与医学生模式的答题正确率几乎重合(p > 0.05);
神经路径高度重叠,跨角色的激活相似度高达0.96~1.00,说明模型在内部表示上几乎没有角色区分;
层级效应缺失,即使输入主任医师或实习医生,模型也不会形成分层的认知结构,深层表示最终趋同。
神经差异分析显示,角色提示的影响仅集中在Transformer模型的前25层(语言模式区),而在更深层(推理区)趋于消失。也就是说,模型的医生身份停留在表面语言层,没有深入到思维层。
研究团队指出,这项研究首次用实验证明:
当前医疗大模型的角色扮演,是一种语言幻觉,而非认知模拟。


警惕AI的专家口吻
角色扮演仅改变语言,不改变思维。
在医疗应用中,依赖扮演专家的AI可能会误导用户,以为其具备专家级判断力,从而耽误治疗;
在AI安全监管上,未来的合规评估应从语言真实性转向认知真实性。
这次将AI语言与神经可解释性相连,开启了认知级AI评估的新范式。
