
进阶必看:深度解析 RAG 检索策略,从新手到高手的关键一步


正文
如果你有构建RAG系统的经历,你就会理解那种辛辛苦苦搭建起来的AI系统,被业务人员骂成智障的挫败感,当你向AI系统问了一个问题,系统却返回了一堆驴唇不对马嘴的答案。
这背后的问题不在于AI的生成能力不够强,而是检索环节出了岔子:RAG不在于生成能力,而在于检索的精准度。尤其是检索策略的选择直接决定了RAG系统能否找到真正相关的知识片段,进而影响最终生成答案的质量。
今天,我们来详细剖析RAG领域的三大检索策略——稀疏检索、密集检索和混合检索,以及它们如何通过不同的技术路径提升检索精准度,分别适应的场景,希望对你有所启发。
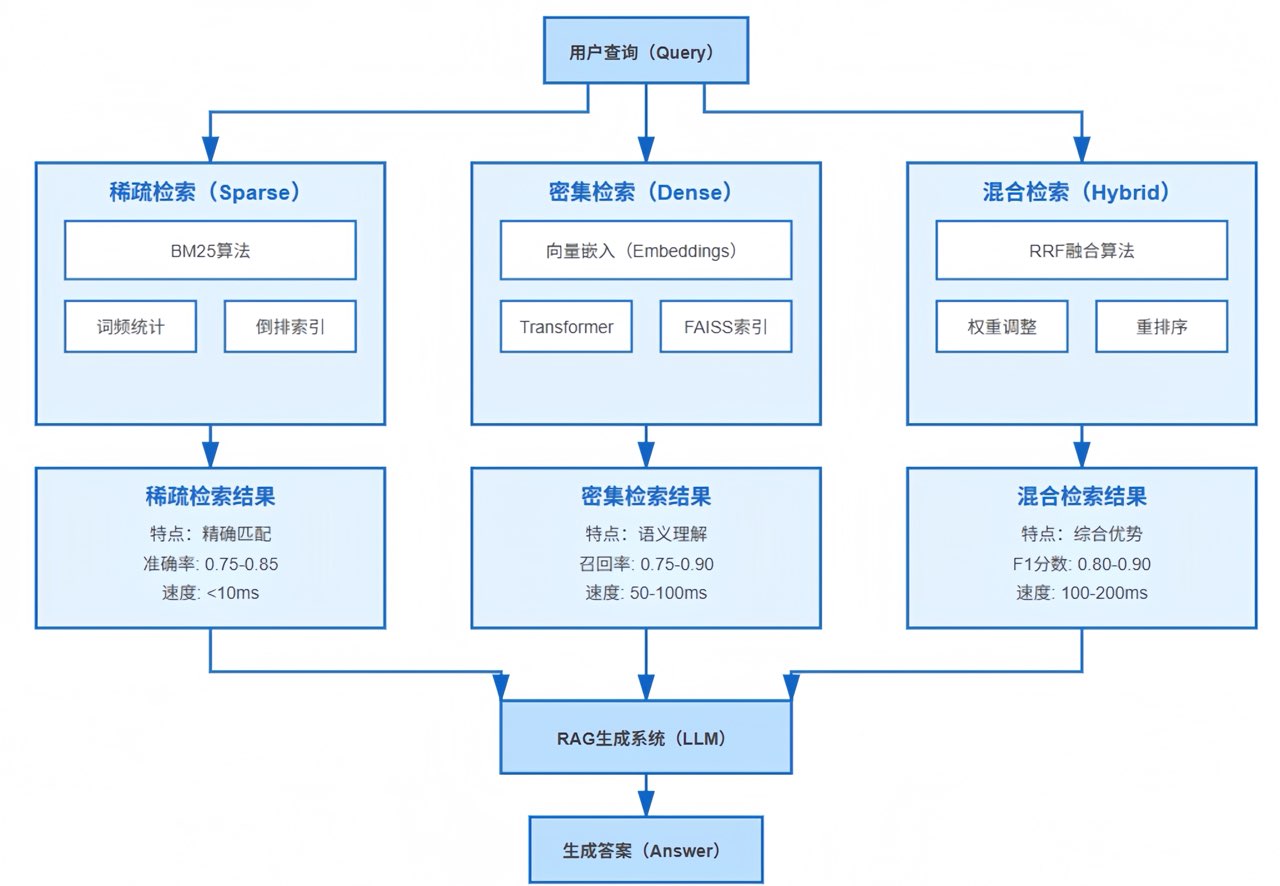
一、 RAG检索的精准度挑战
传统的关键词匹配方法在处理自然语言查询时存在明显的局限性。当用户搜索"如何提升模型性能"时,系统可能无法匹配到包含"优化算法效率"的文档,因为两者的词汇表面没有重叠。这种词汇失配(Vocabulary M ismatch)问题一直困扰着基于关键词的检索系统。
另一方面,纯语义搜索虽然能理解查询意图,但在处理专业术语、产品型号等精确匹配需求时又显得力不从心。这就是RAG系统面临的核心矛盾:准确率(Precision)和召回率(Recall)的平衡。
稀疏检索擅长精确匹配但容易漏掉语义相关的结果,密集检索能捕捉语义但可能引入噪声,而混合检索试图融合两者的优势。根据实际测试数据,单一策略的F1分数通常在0.65-0.75之间,而精心设计的混合检索可以将这一指标提升到0.85以上。
更重要的是,不同业务场景对检索策略的需求差异巨大:技术文档检索需要精确匹配专业术语,客服知识库需要理解口语化表达,电商搜索需要兼顾产品属性和用户意图。选择合适的检索策略,就像为不同的路况选择合适的交通工具,这是构建高质量RAG系统的第一步。
二、 稀疏检索:BM 25的词频智慧
从早期的TF-IDF(词频-逆文档频率)到现在广泛应用的BM25(Best Matching 25),稀疏检索算法经历了数十年的演进。
TF-IDF的局限在于它对词频的线性增长假设——一个词出现10次的文档不应该比出现5次的文档重要性高出一倍。BM25通过引入饱和函数解决了这个问题,其核心公式为:
score(D, Q) = Σ IDF(qi) × (f(qi, D) × (k1 + 1)) / (f(qi, D) + k1 × (1 - b + b × |D| / avgdl))
其中f(qi, D)是词频,|D|是文档长度,avgdl是平均文档长度,k1和b是可调参数。

这个公式的精妙之处在于三个设计:一是饱和函数让词频的影响递减,二是文档长度归一化避免长文档的天然优势,三是IDF(逆文档频率)惩罚常见词。
在实际应用中,BM25在处理精确术语匹配、产品型号查询、专有名词检索等场景时表现出色。
但BM25也有明显的局限性:它无法理解同义词("购买"和"采购"会被视为完全不同的词),无法捕捉词序信息("苹果手机"和"手机苹果"得分相同),也无法处理跨语言检索。
更关键的是,BM25完全依赖词汇匹配,当查询和文档使用不同的表达方式描述同一概念时,就会出现检索失败。
例如,搜索"机器学习模型训练"可能无法匹配到"深度神经网络参数优化"相关的文档,尽管两者语义高度相关。这正是密集检索要解决的问题。

三、 密集检索:向量嵌入的语义理解
密集检索通过将文本映射到连续的低维向量空间,彻底改变了信息检索的范式。每个文档和查询都被编码为一个密集向量(通常是768或1024维),相似的语义内容在向量空间中彼此接近
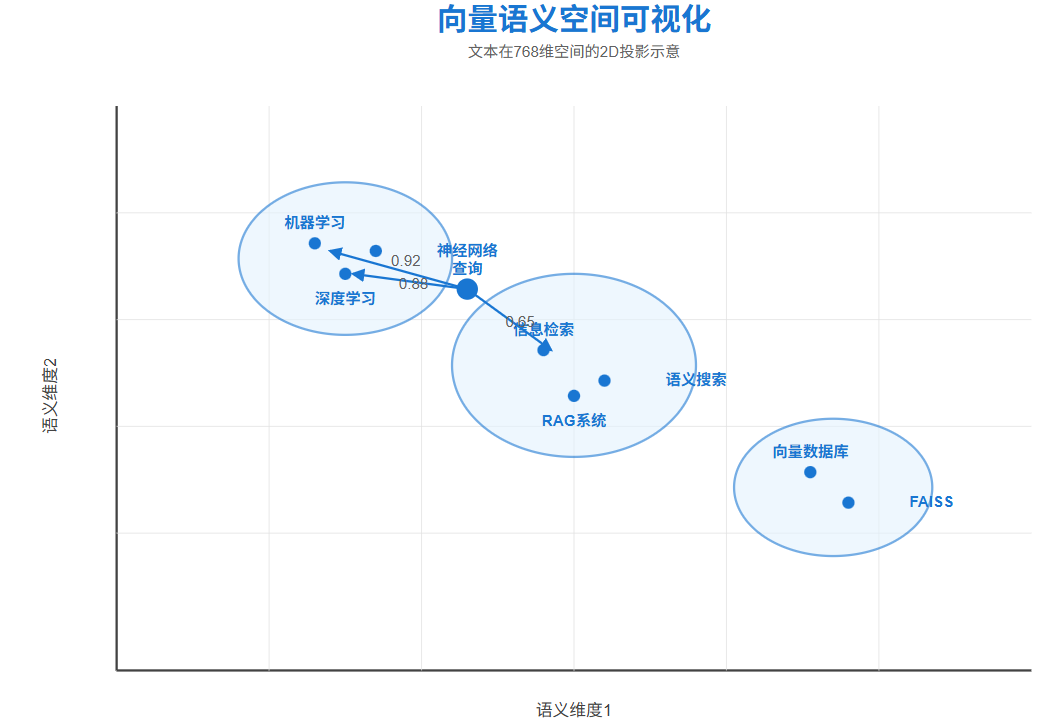
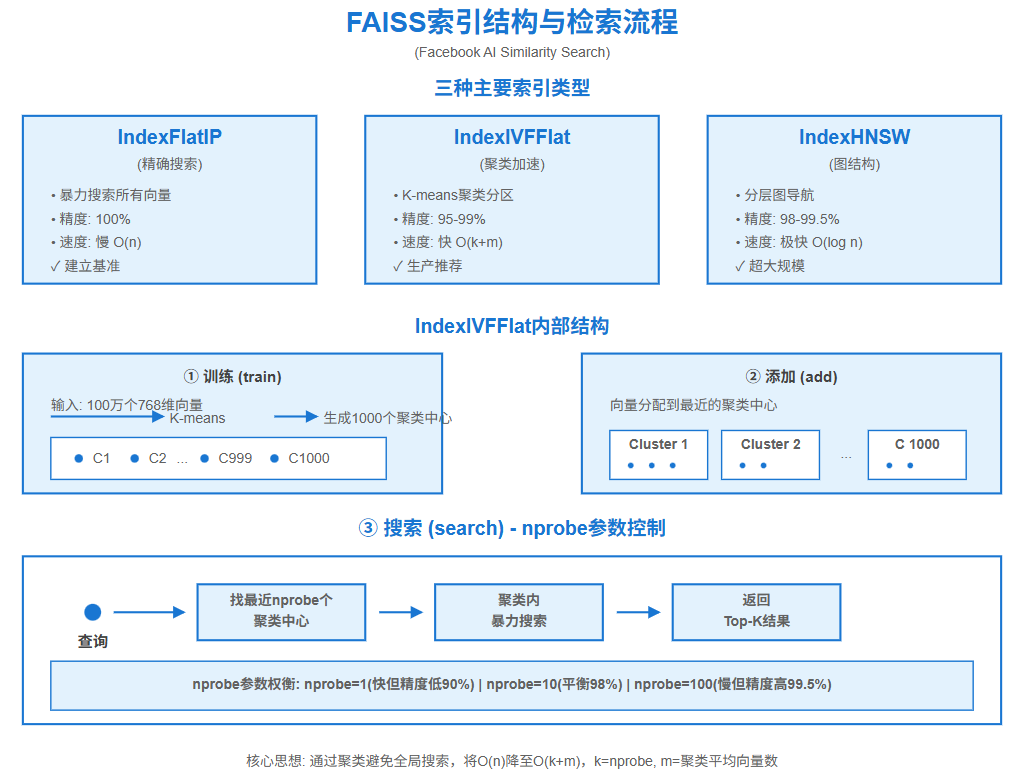
在实际部署中,通常使用IndexFlatIP构建基准,然后根据性能需求选择合适的ANN索引。
另一个问题是密集检索在处理精确匹配需求时的弱势。当用户搜索特定的产品型号"iPhone 15 Pro Max"或文档编号"RFC-8446"时,向量检索可能返回语义相关但型号不符的结果。
此外,密集向量的训练高度依赖数据质量,如果预训练模型的领域与应用场景不匹配,检索效果会显著下降。这就是为什么混合检索成为了生产环境的首选方案——它融合了稀疏检索的精确性和密集检索的语义理解能力。
四、 混合检索:RRF融合策略实战
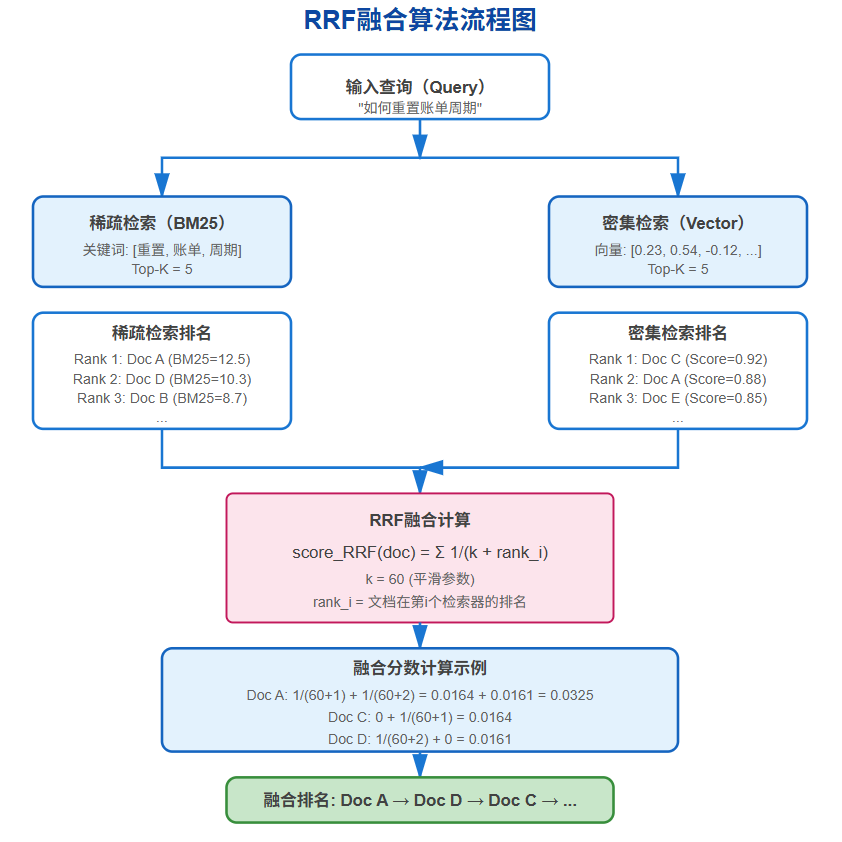
混合检索的核心是如何合理融合稀疏检索和密集检索的结果。最广泛采用的融合算法是RRF(Reciprocal Rank Fusion,倒数排名融合),它通过对每个检索器返回结果的排名进行归一化计分,避免了不同检索器分数量级不一致的问题。RRF算法简单而有效,其公式为:
score_RRF(doc) = Σ 1 / (k + rank_i(doc))
其中rank_i(doc)是文档在第i个检索器中的排名(从1开始),k是平滑参数(通常设为60)。
这个设计的巧妙之处在于:排名靠前的文档贡献更高的分数,而k参数避免了排名第1和第2的文档分数差距过大。下面是一个完整的混合检索实现示例,可以直接在你的项目中使用。
五、 三种策略的性能对比与选型
三种检索策略在不同维度的表现差异显著。从准确率(Precision)来看,稀疏检索在精确匹配场景下可达到0.85-0.90,但在语义泛化场景下降至0.50-0.60;
密集检索的准确率曲线则恰好相反,在语义检索中稳定在0.75-0.85,但处理专业术语时下降到0.60-0.70;
混合检索通过融合策略将准确率稳定在0.80-0.90的高水平区间。
召回率(Recall)方面,密集检索凭借语义理解能力达到0.80-0.90,稀疏检索仅为0.55-0.70,而混合检索接近0.85-0.95。
检索速度上,BM25可以在10ms内完成百万文档的检索,FAISS向量搜索需要50-100ms,混合检索因需要执行两次检索和融合计算,通常在100-200ms之间。

选型决策的关键在于理解业务需求的特征。
技术文档检索系统通常包含大量专业术语和API函数名,这些精确匹配需求使得稀疏检索成为基础,但用户也会提出"如何提升性能"这类语义查询,因此推荐"稀疏为主+密集补充"的混合策略,权重配置为alpha=0.3(30%密集,70%稀疏)。
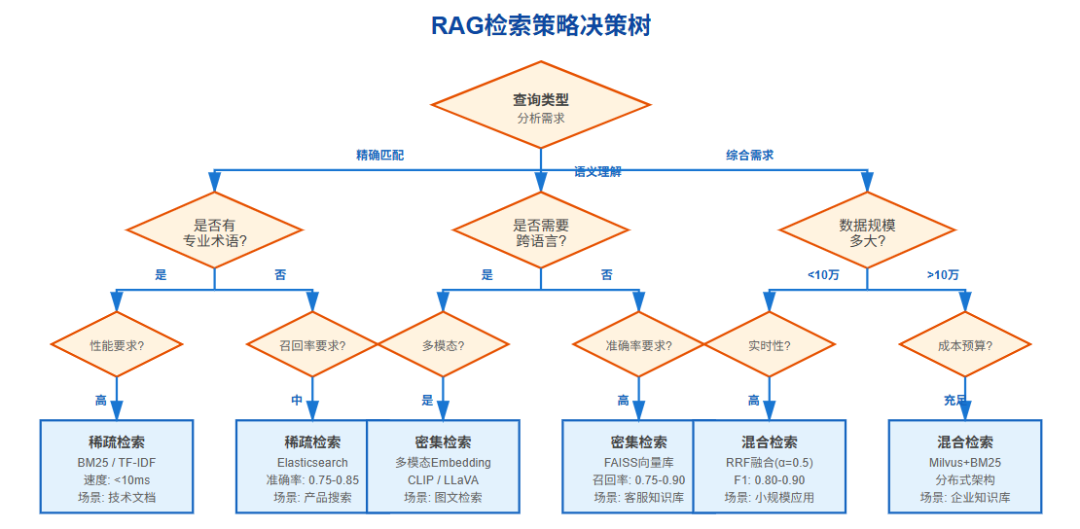
客服知识库面对的是口语化表达和同义词变换,密集检索的语义理解能力至关重要,建议alpha=0.7的配置。
电商搜索需要兼顾"iPhone 15"的精确匹配和"性价比高的手机"的语义理解,标准的混合检索(alpha=0.5)是最佳选择。
成本效益分析不能忽视部署和维护成本。
稀疏检索的Elasticsearch部署成本较低,单台服务器即可支撑千万级文档;密集检索需要向量数据库(如Milvus、Qdrant、Weaviate),通常需要配备GPU服务器,成本增加3-5倍;混合检索需要维护双索引,运维复杂度提升30%-50%。
但从业务价值角度,混合检索带来的检索质量提升可以显著改善用户体验,在知识密集型应用中,F1分数每提升0.1,用户满意度通常提升15%-20%。对于初创团队,建议从稀疏检索起步,积累数据后逐步引入混合检索;对于成熟产品,混合检索的投资回报率通常在6-12个月内显现。
结语
自适应检索策略的探索,更预示着检索技术将走向“按需调整”的智能新阶段。当前混合检索的固定融合权重,已难以适配多样化查询需求——对“iPhone 15 Pro”这类实体查询,稀疏检索更高效;对“如何提升工作效率”这类语义查询,密集检索更精准。LlamaIndex的RouterRetriever与LangChain的ContextualCompressionRetriever已实现初步自适应能力,而“检索-生成-检索”的迭代方案,通过LLM参与检索决策,在复杂问答中展现出巨大潜力。只是数倍增加的查询成本,提醒着技术落地需在质量与经济性之间找到平衡。
