
AI赋能数据分析师:从重复劳动到价值决策的转型指南


一、AI接管重复劳动:数据处理效率提升10倍
数据预处理(清洗、缺失值填充、异常值识别)是分析师最耗时的环节,AI工具可通过“规则生成+自动化执行”完成90%的工作,且准确率高于人工。
1. 📊 数据清洗:AI生成规则,Pandas自动执行
传统数据清洗需手动编写条件判断语句,面对复杂场景(如“不同渠道的手机号格式不一致”“订单金额异常值随品类变化”)时,规则编写耗时且易出错。借助ChatGPT生成清洗规则代码,效率提升显著。
实操案例:电商订单数据清洗
场景:某电商平台订单数据,存在“手机号格式错误”“金额为负”“缺失用户ID”“同一订单号重复录入”四类问题,需快速清洗并生成日志。
步骤1:向AI提需求(精准描述场景)
Prompt:“我有一份电商订单数据,字段包括order_id(订单号)、user_id(用户ID)、phone(手机号)、amount(金额)、category(品类)、create_time(创建时间)。请用Python Pandas编写清洗代码,满足:1. 手机号需为11位数字,不符合的标记为‘格式错误’并记录;2. 金额≤0的标记为异常值,替换为该品类金额的中位数;3. 缺失user_id的订单,用‘未知用户_时间戳’填充;4. 重复的order_id保留创建时间最新的一条,删除其余并记录;5. 生成清洗日志,包含问题类型、原数据、处理结果。”
步骤2:AI生成代码(直接复用,微调参数)
import pandas as pd
import numpy as np
from datetime import datetime
# 读取原始数据
df = pd.read_csv("ecommerce_orders.csv", encoding="utf-8")
# 初始化清洗日志
clean_log = []
# 1. 手机号清洗
def clean_phone(phone):
if pd.isna(phone):
clean_log.append({"问题类型": "手机号缺失", "order_id": df[df["phone"]==phone]["order_id"].iloc[0], "原数据": "缺失", "处理结果": "未填充"})
return "缺失"
phone_str = str(phone).strip()
if phone_str.isdigit() and len(phone_str) == 11:
return phone_str
else:
clean_log.append({"问题类型": "手机号格式错误", "order_id": df[df["phone"]==phone]["order_id"].iloc[0], "原数据": phone, "处理结果": "格式错误"})
return "格式错误"
df["cleaned_phone"] = df["phone"].apply(clean_phone)
# 2. 金额异常值处理
def clean_amount(row):
amount = row["amount"]
category = row["category"]
if amount <= 0:
# 取该品类金额中位数替换
category_median = df[df["category"] == category]["amount"].median()
clean_log.append({"问题类型": "金额异常", "order_id": row["order_id"], "原数据": amount, "处理结果": category_median})
return category_median
return amount
df["cleaned_amount"] = df.apply(clean_amount, axis=1)
# 3. 缺失user_id填充
def fill_user_id(row):
if pd.isna(row["user_id"]):
timestamp = datetime.strptime(row["create_time"], "%Y-%m-%d %H:%M:%S").strftime("%Y%m%d%H%M%S")
new_user_id = f"未知用户_{timestamp}"
clean_log.append({"问题类型": "user_id缺失", "order_id": row["order_id"], "原数据": "缺失", "处理结果": new_user_id})
return new_user_id
return row["user_id"]
df["filled_user_id"] = df.apply(fill_user_id, axis=1)
# 4. 去重:保留同一order_id最新的记录
df["create_time"] = pd.to_datetime(df["create_time"])
# 按order_id分组,保留create_time最大的行
duplicate_order_ids = df[df.duplicated(subset=["order_id"], keep=False)]["order_id"].unique()
for order_id in duplicate_order_ids:
duplicate_rows = df[df["order_id"] == order_id].sort_values("create_time")
# 记录待删除的行
for idx in duplicate_rows.index[:-1]:
clean_log.append({"问题类型": "订单号重复", "order_id": order_id, "原数据": duplicate_rows.loc[idx].to_dict(), "处理结果": "已删除"})
# 去重操作
df_cleaned = df.sort_values("create_time").drop_duplicates(subset=["order_id"], keep="last")
# 保存清洗后的数据和日志
df_cleaned.to_csv("cleaned_orders.csv", index=False)
log_df = pd.DataFrame(clean_log)
log_df.to_csv("cleaning_log.csv", index=False)
print(f"数据清洗完成,共处理{len(clean_log)}条问题数据")
print(f"清洗后数据量:{len(df_cleaned)}条,原始数据量:{len(df)}条")
步骤3:分析师核心工作(10%干预)
1. 检查AI生成的“品类金额中位数”逻辑是否符合业务(如奢侈品品类金额异常值不能用大众品类中位数替换);2. 核对清洗日志中的高频问题(如某渠道手机号格式错误占比超50%,需反馈给数据采集团队)。
2. 🚀 自动化取数:AI生成SQL,对接业务系统
分析师常需响应“临时取数需求”,如“取近30天各城市、各品类的订单量及客单价,按客单价降序排列”。用LangChain连接数据库,配合大模型可实现“自然语言转SQL”,无需手动编写。
实操案例:自然语言转SQL取数
from langchain.llms import OpenAI
from langchain.utilities import SQLDatabase
from langchain.chains import SQLDatabaseChain
import os
# 配置环境变量(API密钥)
os.environ["OPENAI_API_KEY"] = "你的API密钥"
# 1. 连接数据库(以MySQL为例)
db = SQLDatabase.from_uri(
"mysql+pymysql://用户名:密码@数据库IP:端口/数据库名",
include_tables=["orders", "users"] # 指定可用表,提升SQL生成准确率
)
# 2. 初始化大模型和SQL链
llm = OpenAI(model_name="gpt-3.5-turbo-instruct", temperature=0)
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True, return_intermediate_steps=True)
# 3. 自然语言提需求
user_query = "取2024年10月1日至2024年10月31日,各城市(从users表的city字段获取)、各品类(orders表的category字段)的订单量和客单价,客单价=订单总金额/订单量,结果按客单价降序排列,只保留订单量≥100的记录"
# 4. 执行查询并获取结果
result = db_chain(user_query)
# 5. 提取SQL和查询结果
generated_sql = result["intermediate_steps"][1]["sql_cmd"]
query_result = result["result"]
print("生成的SQL语句:")
print(generated_sql)
print("\n查询结果:")
print(query_result)
关键优化:提升SQL准确率
1. 向AI提供“表结构说明”(如“orders表的amount字段为订单总金额,不含运费”);2. 限制可用表范围,避免AI关联无关表;3. 复杂需求分步骤提问(如先取基础数据,再计算衍生指标)。
二、AI辅助深度分析:从“数据呈现”到“洞察生成”
分析师的核心价值是“从数据中发现业务问题”,AI可通过“特征挖掘、趋势预测、归因分析”辅助提升洞察深度,尤其在用户行为分析、流失预警等场景效果显著。
1. 🎯 用户流失分析:AI自动挖掘关键特征
传统流失分析需手动假设影响因素(如“近7天登录次数”“消费频率”),AI可通过特征重要性分析,发现分析师忽略的潜在因素(如“客服投诉后48小时未跟进”)。
实操案例:电商用户流失预测
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import seaborn as sns
# 读取用户数据(含流失标签:churn=1为流失,0为留存)
user_data = pd.read_csv("user_churn_data.csv")
# 分离特征和标签
X = user_data.drop(["user_id", "churn"], axis=1)
y = user_data["churn"]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练随机森林模型(AI特征挖掘核心)
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
# 模型评估
y_pred = rf_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"流失预测准确率:{accuracy:.2f}")
# 提取特征重要性(AI挖掘关键因素)
feature_importance = pd.DataFrame({
"feature": X.columns,
"importance": rf_model.feature_importances_
}).sort_values("importance", ascending=False)
# 可视化特征重要性
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(10, 6))
sns.barplot(x="importance", y="feature", data=feature_importance.head(10))
plt.title("用户流失关键影响因素(TOP10)")
plt.xlabel("特征重要性")
plt.ylabel("特征名称")
plt.savefig("churn_feature_importance.png", dpi=300, bbox_inches="tight")
# 向AI提问:基于特征重要性,生成业务洞察
prompt = f"""以下是用户流失的TOP5关键特征及重要性:
1. 近7天登录次数:0.28
2. 客服投诉后48小时内是否跟进:0.22
3. 近30天平均订单金额:0.15
4. 会员等级:0.12
5. 近15天浏览商品后转化率:0.09
请结合电商业务场景,分析每个特征对流失的影响,并给出具体的挽留策略,要求:
1. 解释特征与流失的逻辑关系;
2. 每个特征对应1-2条可落地的策略;
3. 优先推荐投入产出比高的策略。"""
# 调用ChatGPT获取洞察(此处省略API调用代码,与前文一致)
# 示例AI生成的洞察:
# 1. 近7天登录次数(重要性0.28):登录次数≤1的用户流失率是≥5次的8倍,说明用户活跃度是核心指标。策略:对登录次数1-2次的用户推送“专属优惠券”,弹窗提醒未付款订单。
# 2. 客服投诉跟进(重要性0.22):未跟进用户流失率达65%,已跟进的仅12%。策略:建立投诉跟进SOP,要求48小时内通过电话+短信双重触达,跟进完成后24小时内推送补偿券。
2. 📈 自动化可视化:AI一键生成多维度图表
传统可视化需手动调整图表类型、配色、标签,面对“老板要换维度看数据”的需求时,反复修改耗时。Tableau AI、Power BI Copilot可通过自然语言生成图表,并支持实时迭代。
实操案例:Tableau AI生成可视化
1. 导入清洗后的订单数据(cleaned_orders.csv);2. 在Tableau中输入自然语言需求:“用组合图展示近30天各时段的订单量(柱状图)和客单价(折线图),突出显示客单价峰值时段,用红色标记订单量低于均值的时段”;3. Tableau AI自动生成图表,分析师仅需微调配色和标题,适配汇报场景。
核心价值:将“制作图表”的时间从1小时缩短至5分钟,分析师可聚焦“图表背后的业务逻辑”(如“凌晨2-4点客单价高,对应夜间抢购活动,可加大该时段的推广投入”)。
三、数据分析师的AI时代核心竞争力:3大能力不可替代
AI能处理“流程化工作”,但无法替代“业务理解、逻辑判断、决策建议”。数据分析师需构建以下3大核心能力,实现从“工具使用者”到“业务伙伴”的转型。
1. 🔍 业务洞察力:AI的“方向盘”
AI生成的分析结果需结合业务场景判断合理性。例如:AI发现“某城市周末订单量骤降”,若分析师不了解该城市周末有大型展会导致物流停运,可能会错误建议“加大推广投入”,而正确结论是“协调临时物流资源”。
提升方法:1. 参与业务会议,了解前端运营、销售的核心痛点;2. 建立“业务-数据”映射表(如“促销活动对应订单量峰值,新用户注册对应渠道转化率”)。
2. 🔧 数据治理能力:AI的“燃料质量控制”
AI分析的准确性依赖高质量数据,分析师需负责“数据源头质量把控”。例如:某平台用户数据存在“同一用户多ID”问题,若直接用于AI分析,会导致“用户流失率计算偏差”。分析师需先通过用户手机号、设备号进行ID合并,再交给AI处理。
核心技能:掌握数据血缘分析(了解数据从采集到存储的全链路)、数据质量监控指标(完整性、一致性、准确性)。
3. 📢 决策沟通能力:AI的“翻译官”
AI生成的“特征重要性报告”“预测结果”对业务人员而言过于技术化,分析师需将其转化为“可落地的业务语言”。例如:将“用户流失预测准确率85%”转化为“基于模型,我们能提前识别出85%的潜在流失用户,通过针对性挽留,预计可降低15%的流失率,对应月增收200万元”。
提升方法:1. 汇报时遵循“结论先行+数据支撑+建议具体”的结构;2. 用“业务指标”替代“技术指标”(如用“客单价提升10%”替代“模型MAE降低0.5”)。
四、避坑指南:数据分析师用AI的5大常见问题
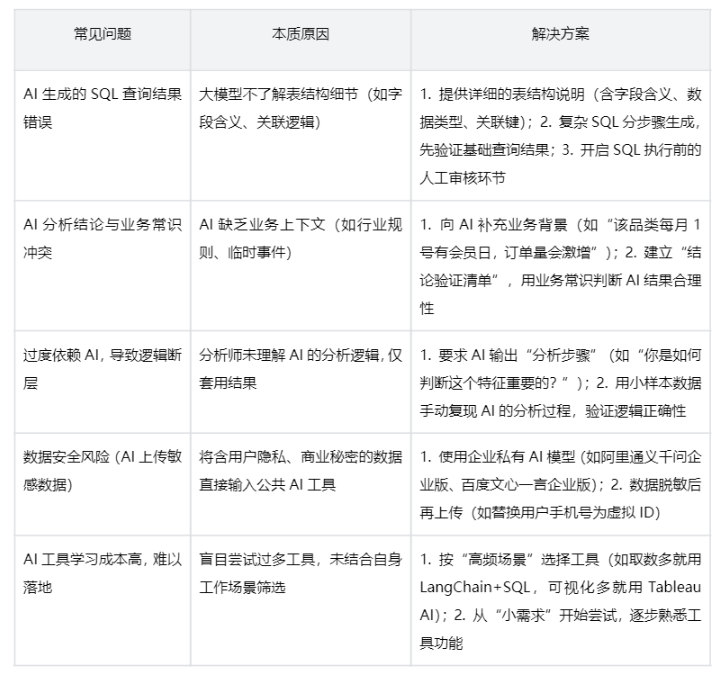
总结:AI时代数据分析师的成长路径
AI不是数据分析师的“竞争对手”,而是“升级工具”。未来1-2年,优秀的分析师将具备“AI工具实操能力+业务洞察能力+决策沟通能力”的三维竞争力,成长路径清晰:
1. 入门阶段(0-1年):熟练用AI工具处理重复劳动(数据清洗、SQL生成、基础可视化),将工作效率提升50%以上;
2. 进阶阶段(1-3年):结合业务场景优化AI分析逻辑,用AI完成深度分析(如用户分群、流失预测),输出有落地价值的洞察报告;
3. 专家阶段(3年以上):主导企业AI分析体系搭建,制定“数据-AI-决策”的落地流程,成为连接技术与业务的核心枢纽。
