
零基础学AI大模型之RAG系统链路解析与Document Loaders多案例实战


前情摘要:
8、零基础学AI大模型之LangChain六大核心模块与大模型IO交互链
10、零基础学AI大模型之LangChain-PromptTemplate
11、零基础学AI大模型之ChatModel聊天模型与ChatPromptTemplate实战
12、零基础学AI大模型之LangChain聊天模型多案例实战
15、零基础学AI大模型之解析器PydanticOutputParser
16、零基础学AI大模型之LangChain Output Parser
17、零基础学AI大模型之大模型修复机制:OutputFixingParser解析器
零基础学AI大模型之RAG系统链路解析与Document Loaders多案例实战
在之前的AI大模型系列中,我们从基础概念(如大模型“幻觉”、LangChain核心模块)逐步深入到实战(如Stream流式输出、PydanticOutputParser解析),并在第17篇初步提及RAG技术的重要性。
RAG(Retrieval-Augmented Generation,检索增强生成)是解决大模型“幻觉”的核心方案——通过“检索外部知识”为LLM提供精准上下文,让生成结果更可靠。但RAG系统并非单一技术,而是一条完整的“数据处理→存储→检索→生成”链路,其中数据加载(Document Loaders)是整个链路的“入口” ——没有高质量的原始数据加载,后续的向量化、检索都无从谈起。
本文将聚焦RAG系统的完整链路解析,并通过多案例实战,带你掌握LangChain中Document Loaders的核心用法,为后续RAG项目打下坚实基础。
一、RAG系统核心链路:从数据到生成的完整流程
RAG的本质是“让LLM带着外部知识回答问题”,其核心链路可拆解为数据准备”和“检索生成”两大阶段,每个阶段包含多个关键技术环节。理解这条链路,是后续实战的前提。
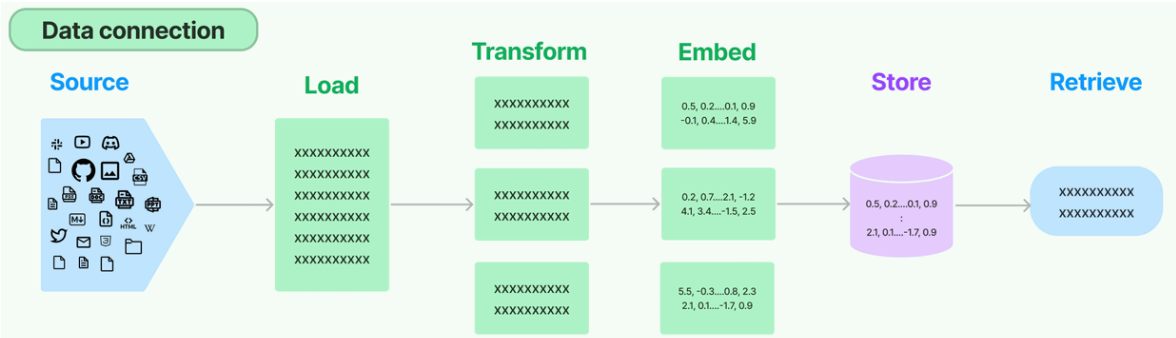
1.1 RAG数据流流水线示意图
原始数据需要经过一系列处理,才能最终为LLM提供有效支撑,完整流程如下:

1.2 RAG关键技术环节解析
链路中每个环节都有明确的职责,缺一不可:
- 文档加载器(Document Loaders):本文核心,负责将不同来源、不同格式的原始数据(如本地PDF、在线网页、MySQL数据库)转为LangChain统一的
Document对象,解决“数据入口不统一”问题。 - 文档转换器(Document Transformers):对
Document进行清洗(去除乱码、空白行)和分块(如按500字符/块分割),避免长文本向量化时的语义失真。 - 文本嵌入模型(Embedding Models):如OpenAI的
text-embedding-3-small、开源的BERT,负责将文本转为高维向量(如1536维),让计算机能通过“向量距离”判断文本相似度。 - 向量存储(Vector Stores):如Pinecone、Chroma、Milvus,专门存储文本向量,支持快速相似性检索(毫秒级找到与查询最像的文本)。
- 检索器(Retrievers):定义检索逻辑(如“相似性检索Top 3”“关键词过滤+相似性检索”),从向量库中抓取与用户查询匹配的上下文。
二、RAG与LLM交互架构:为什么RAG能解决“幻觉”?
传统LLM直接生成回答时,依赖的是训练时的“记忆”,但存在“知识过时”“虚构信息”问题;而RAG通过“检索+生成”的交互模式,让LLM“带着参考资料答题”,从根本上减少幻觉。
2.1 RAG与LLM交互架构图
2.2 架构核心优势
- 知识实时更新:无需重新训练LLM,只需更新向量库中的数据(如新增2024年LangChain新特性),即可让LLM获取最新知识。
- 结果可追溯:生成的回答可对应到具体的原始数据(如“该结论来自XX PDF第5页”),便于验证准确性。
- 降低训练成本:无需训练千亿参数的大模型,用中小模型(如7B的Llama3)+ RAG,即可实现高精度回答。
三、Document Loaders核心概念:LangChain如何统一数据入口?
LangChain为了解决“不同数据源适配”问题,设计了统一的加载器接口,无论原始数据格式如何,最终都能转为Document对象。
3.1 LangChain Loaders的核心设计:BaseLoader接口
LangChain所有加载器都继承自抽象类BaseLoader,确保统一的调用方式。核心接口定义如下(简化版):
load()方法:最常用,直接返回所有Document组成的列表,适合小文件。lazy_load()方法:生成器模式,逐个返回Document,适合大文件(如1000页的PDF),避免一次性加载到内存导致OOM。
3.2 Document对象:数据的“统一载体”
所有Loader最终输出的都是Document对象,其结构非常简单,包含两个核心字段:
示例Document对象:
3.3 Loaders分类:覆盖所有常见数据源
LangChain的langchain_community.document_loaders模块提供了上百种Loader,按数据源类型可分为三大类:
分类 | Loader类型 | 功能描述 | 适用场景 |
|---|---|---|---|
文件加载器 | TextLoader | 加载纯文本文件(.txt) | 本地日志文件、纯文本笔记 |
PyPDFLoader | 加载PDF文件,支持提取页码元数据 | 技术文档、论文 | |
Docx2txtLoader | 加载Word文档(.docx) | 工作报告、需求文档 | |
CSVLoader | 加载CSV文件,按行生成Document | 数据报表、用户列表 | |
网页加载器 | WebBaseLoader | 抓取静态网页文本(无需JS渲染) | 博客文章、百科页面 |
SeleniumURLLoader | 加载动态网页(需JS渲染,如Vue/React页面) | 电商商品页、登录后页面 | |
数据库加载器 | SQLDatabaseLoader | 执行SQL查询,加载结果为Document | MySQL、PostgreSQL等关系库 |
MongoDBLoader | 从MongoDB集合中加载文档 | NoSQL数据库数据 |
四、Document Loaders多案例实战:从理论到代码
光说不练假把式,下面通过3个最常用的Loader案例(TextLoader、CSVLoader、JSONLoader),带你掌握实战技巧,所有代码可直接复制运行。
前置准备:安装依赖
首先安装LangChain及Loader所需的额外依赖:
案例1:TextLoader——加载纯文本文件
纯文本文件(.txt)是最基础的数据源,TextLoader支持自定义编码,解决中文乱码问题。
实战代码
关键说明
- 中文乱码解决:如果
test.txt是GBK编码,直接用encoding="utf-8"会乱码,开启autodetect_encoding=True后,Loader会自动识别编码。 - 大文本处理:如果
test.txt有10万行,用lazy_load()逐个获取Document:
案例2:CSVLoader——加载Excel表格数据
CSV文件(.csv)常用于存储结构化数据(如销售报表),CSVLoader支持按行生成Document,且可指定字段名。
实战场景
假设data/sales.csv文件内容如下(销售数据):
实战代码
关键说明
- 自定义分隔符:如果CSV是用制表符(\t)分隔,需将
delimiter设为"\t"。 - 字段筛选:如果只需加载“产品名称”和“销售数量”,可在
csv_args中添加"usecols": ["产品名称", "销售数量"]。
案例3:JSONLoader——加载JSON文件(复杂结构解析)
JSON文件常用于存储半结构化数据(如接口返回、日志),JSONLoader的核心是通过jq_schema指定数据提取规则,支持复杂结构解析。
实战场景
假设data/articles.json文件内容如下(文章列表):
实战代码
关键:jq_schema语法常用模式
jq_schema是JSONLoader的核心,用于定义“从JSON中提取哪些数据”,常用语法如下:
需求场景 | jq_schema示例 | 说明 |
|---|---|---|
提取根级数组 | ".[]" | 适合JSON本身是数组(如[{"id":1},{"id":2}]) |
提取嵌套数组 | ".data.articles[]" | 提取深层数组元素(如本文案例) |
条件过滤 | ".data.articles[] | select(.id > 1)" |
多字段合并 | ".data.articles[] | {c: .content, t: .title}" |
五、Loaders实战常见问题与解决方案
实战中难免遇到各种问题,这里整理3个高频问题及解决方案:
常见问题 | 原因分析 | 解决方案 |
|---|---|---|
中文乱码(如“��”) | 文本编码与Loader指定的encoding不匹配 | 1. 开启 |
JSONLoader报错“jq: error” | jq_schema语法错误,或JSON结构与预期不符 | 1. 用jq在线验证工具测试语法;2. 打印原始JSON确认结构 |
六、总结
本文我们掌握了RAG系统的核心链路,以及作为“数据入口”的Document Loaders实战技巧。
如果觉得本文有帮助,欢迎点赞+关注,你的支持是我持续更新的动力!有任何问题,也可以在评论区留言交流~
