
零基础学AI大模型之RAG系统链路构建:文档切割转换全解析


前情摘要
8、零基础学AI大模型之LangChain六大核心模块与大模型IO交互链
10、零基础学AI大模型之LangChain-PromptTemplate
11、零基础学AI大模型之ChatModel聊天模型与ChatPromptTemplate实战
12、零基础学AI大模型之LangChain聊天模型多案例实战
15、零基础学AI大模型之解析器PydanticOutputParser
16、零基础学AI大模型之LangChain Output Parser
17、零基础学AI大模型之大模型修复机制:OutputFixingParser解析器
20、零基础学AI大模型之RAG系统链路解析与Document Loaders多案例实战
21、零基础学AI大模型之LangChain PyPDFLoader实战与PDF图片提取全解析
22、零基础学AI大模型之LangChain WebBaseLoader与Docx2txtLoader实战
零基础学AI大模型之RAG系统链路构建:文档切割转换全解析
大家好,我是工藤学编程 🦉 ,一个专注AI大模型实战的小博主~ 上一篇我们详细拆解了RAG系统的文档加载环节,用PyPDFLoader、WebBaseLoader等工具搞定了PDF、网页、Word等多源数据的加载。但加载后的原始文档往往存在「长度超标」「格式混乱」「信息零散」等问题——500页的法律合同直接喂给模型会超token限制,网页文本混着广告导航栏,产品手册的关键参数散在不同页面……这时候就需要RAG链路中的核心环节:文档切割转换来“提纯”数据。
今天这篇就带大家吃透LangChain中的文档转换器(Document Transformers),从「为什么要做」到「核心参数怎么调」,再到「不同场景实战」,手把手教你做好RAG的数据预处理第一步~
一、先搞懂:为啥RAG必须做文档切割转换?
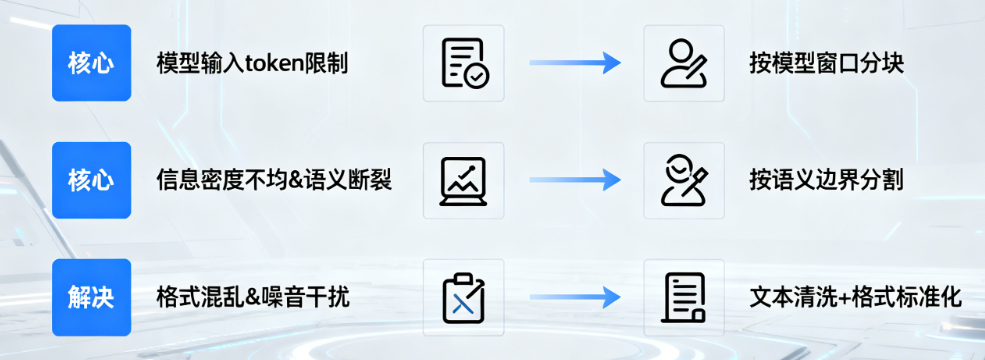
上一篇加载后的文档只是“原始素材”,直接用于向量化和检索会踩3个大坑,这也是文档切割转换的核心价值所在:
核心痛点 | 具体影响 | 解决思路 |
|---|---|---|
模型输入token限制 | GPT-4最大32k tokens、Claude 3最高200k,长文档(如500页合同)直接输入会API报错,或被截断导致信息丢失 | 按模型上下文窗口合理分块,确保每个文本块长度合规 |
信息密度不均 & 语义断裂 | 关键信息(如合同条款、产品参数)分散在长文本中,粗暴分割会把完整语义(如一个句子、一个功能模块)拆碎 | 按自然语义边界(段落、句子)分割,保留上下文连贯性 |
格式混乱 & 噪音干扰 | 网页文本含广告/导航栏、代码文档混着Markdown格式、PDF有乱码特殊字符,会降低向量检索精度 | 文本清洗去噪 + 格式标准化,提取纯净有效内容 |
简单说:文档切割转换的本质是「数据提纯+结构化」——把杂乱的原始文档变成「长度合规、语义完整、无噪音、带上下文元数据」的标准化文本块,为后续向量化和检索筑牢基础。
二、LangChain文档转换器:核心逻辑与核心任务
LangChain中的Document Transformers是处理文档流水线的“数据加工厂”,核心围绕3件事展开,缺一不可:
1. 三大核心任务(直接决定后续检索效果)
核心任务 | 具体操作 | 最终效果 |
|---|---|---|
文本分块 | 按「固定长度+语义边界」分割文本(优先用段落、句子分隔符) | 避免截断完整语义,适配模型token限制 |
去噪处理 | 移除特殊字符、乱码、HTML标签、广告内容、多余空格 | 提升文本信息密度,减少噪音对向量化的干扰 |
元数据增强 | 为每个文本块注入来源(如“XX合同第3章”)、页码、时间戳、加载器类型等上下文 | 检索时可追溯信息源头,提高答案可信度 |
2. 核心组件:TextSplitter抽象类
所有文档切割逻辑都基于langchain_text_splitters.TextSplitter抽象类实现——它定义了分块的核心接口,但不直接实现分割逻辑,需通过子类(如RecursiveCharacterTextSplitter、CharacterTextSplitter)按具体策略执行。
先看核心源码结构(关键参数带场景解读):
关键方法调用链路:split_documents → create_documents → split_text
TextSplitter的三个核心方法各有分工,很多新手会混淆,用表格一次性讲清:
方法 | 输入类型 | 输出类型 | 元数据处理 | 典型使用场景 |
|---|---|---|---|---|
| 单个字符串 | List[str](纯文本块列表) | ❌ 不保留 | 仅需分割纯文本(如无格式的TXT文件),无需上下文信息 |
| 字符串列表 + 可选元数据列表 | List[Document](文档对象列表) | ✅ 需手动传递 | 从纯文本构建带元数据的文档(如给网页文本添加“来源URL”元数据) |
| List[Document](加载后的文档对象) | List[Document](分割后的文档对象) | ✅ 自动继承 | 处理已加载的文档(如PyPDFLoader加载的PDF、WebBaseLoader加载的网页),无需手动管元数据 |
调用逻辑小技巧:实际开发中优先用split_documents()——它会自动继承原始文档的元数据(如PDF的页码、网页的URL),避免后续检索时“找不到信息来源”。
三、核心参数深度解析:调对参数=检索精度翻倍
TextSplitter的3个核心参数(chunk_size、chunk_overlap、separators)直接决定分块质量,新手最容易在这里踩坑,下面结合场景讲透:
1. chunk_size:文本块的“最大长度阈值”
- 定义:每个文本块的最大长度(默认按「字符数」计算,可通过
length_function改为token数) - 核心作用:控制文本块大小,既要适配模型上下文窗口,又要保证信息密度
- 关键技巧:
- 不是越小越好:细粒度分块(如chunk_size=500)能提高检索精准度,但会导致语义断裂(比如把一个完整的合同条款拆成两半);
- 不是越大越好:粗粒度分块(如chunk_size=10000)可能超出模型token限制,且包含无关信息,降低检索效率;
- 参考值:根据目标模型调整——GPT-4(32k)可设1500-2000,Claude 3(200k)可设5000-8000,预留部分token给后续prompt。
实战案例:分割产品手册文本
2. chunk_overlap:相邻文本块的“上下文粘合剂”
- 定义:相邻两个文本块之间重叠的字符数(或token数)
- 核心作用:避免因分割导致语义断裂,确保上下文连贯性
- 关键技巧:
- 重叠比例建议为
chunk_size的10%-20%(如chunk_size=1000时,chunk_overlap=100-200); - 无重叠会导致“信息断层”(比如前块结尾是“卷积神经”,后块开头是“网络(CNN)”,单独看都不完整);
- 重叠过多会导致冗余,增加存储和检索成本。
经典案例:长文本序列分割计算假设chunk_size=1024,chunk_overlap=128,处理长度为2560的文本:
- 文本块1:第1-1024个token(完整前半段)
- 文本块2:第897-1920个token(与块1重叠128个,衔接上下文)
- 文本块3:第1793-2560个token(与块2重叠128个,覆盖剩余内容)
3. separators:控制分块的“语义边界优先级”
- 定义:分隔符列表,按优先级顺序递归分割文本(优先用高优先级分隔符,分割后仍超chunk_size再用低优先级)
- 核心作用:让分块贴合自然语义(段落→句子→短语),减少“拆碎完整语义”的概率
- 默认分隔符:
["\n\n", "\n", " ", ""](先按段落分割,再按换行,最后按空格) - 自定义技巧:根据文档类型调整——
- 中文文本:添加
"。"“;”“,”(如["\n\n", "。", ";", ",", " "]); - 代码文档:添加
"\n\n", "\n", "{", "}", ";", " "(避免拆碎代码块); - Markdown文档:保留
"## "“### ”(按标题分割,保持章节完整性)。
实战案例:中文法律文本自定义分隔符
如果觉得这篇文章有帮助,别忘了点赞关注~ 有任何文档切割的踩坑问题,欢迎在评论区交流!咱们下一篇见~ 🚀
