
拒绝AI“多动症”!AI漫剧如何靠“可控SOP”颠覆传统文娱产能?

随着 Sora、可灵(Kling) 等模型的爆发,生成一段富有“大片感”的视频已非难事。
但对于AI漫剧创作者而言,真正的门槛在于“连续性”——上一秒主角还是清冷御姐,下一秒就成了邻家小妹;镜头一转,卧室的装修风格竟从欧式变成了赛博朋克。
在长篇连载中,如何让AI像签约演员一样容貌稳定,像实体影棚一样场景固化?
本文将深入文娱工业最前沿的作业流程,揭秘实现人物与场景跨集一致性的“驯化”逻辑,带你完成从“抽卡玩家”到“AI导演”的进阶。

一、痛点溯源:破解算法生成的“随机魔咒”
要解决问题,先要理解病灶。目前的文生图/视频模型(如 Stable Diffusion, Midjourney, Runway 等),本质上是基于 “扩散模型”(Diffusion Model)。简单来说,它们是从一团噪点中“猜”出画面的。
当你输入“一个穿着红裙子的女孩”,AI每次“猜”出来的红裙女孩都不一样。因为它没有记忆,没有对“这个特定女孩”的具象认知。
在单张海报设计中这是创意,但在连续剧情中,这就是灾难。因此,“控制” 成为了AI漫剧的核心关键词,我们需要给狂野的AI套上缰绳。
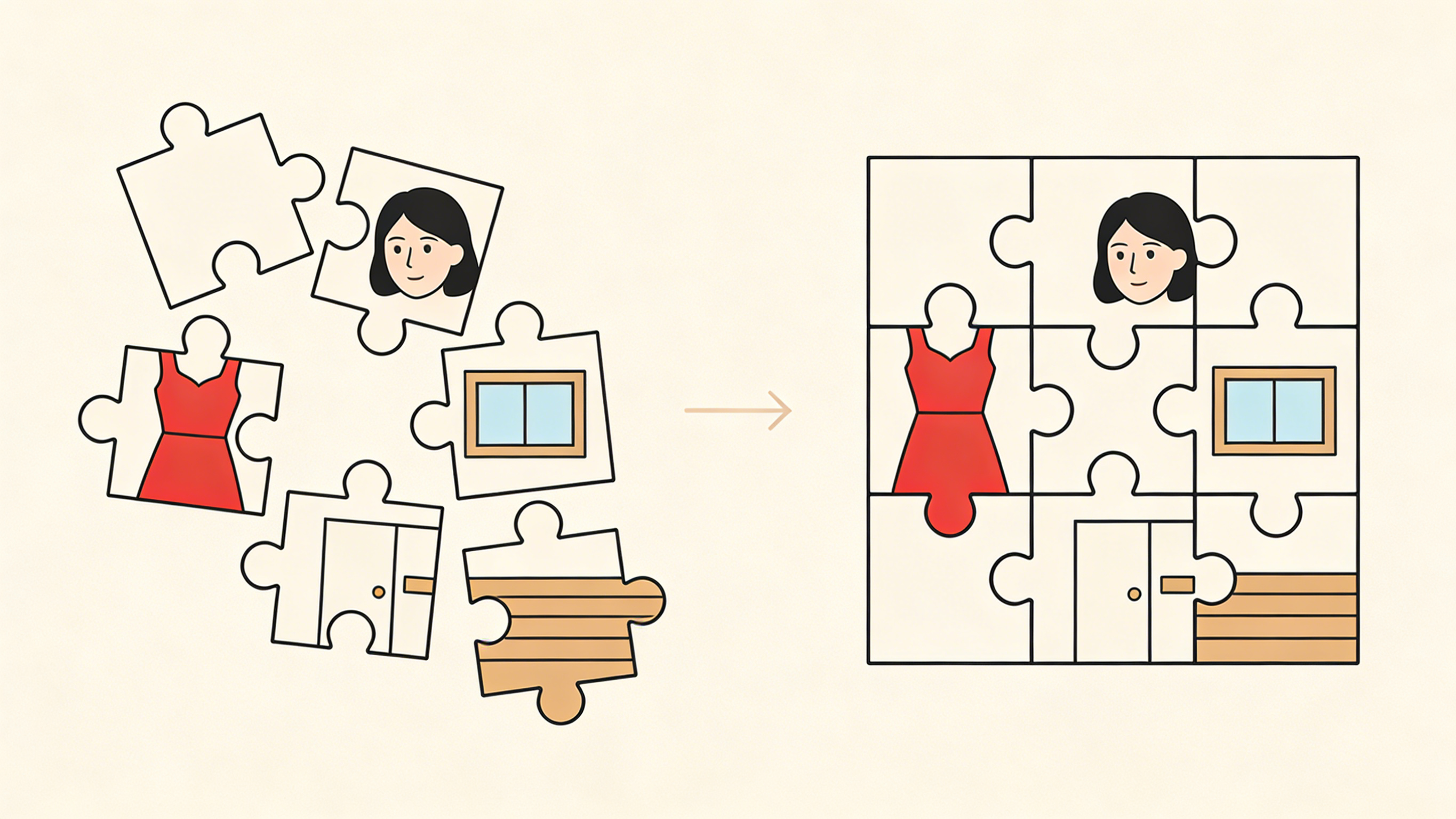
二、角色定锚:驯化“数字演员”
在传统影视中,演员进组前要定妆。在AI漫剧制作流中,我们通过以下四步技术手段,打造永远不崩的“数字演员”。
1. 基础地基:标准三视图与种子值锁定
一切的一致性始于一张完美的 “角色设定图”。 在创作初期,不要直接生成剧情图,而是先利用Midjourney或Stable Diffusion生成主角的三视图(正面、侧面、背面)。
- ⚡️ 操作要点: 拿到满意的角色后,记录下它的 种子值。虽然种子值不能保证100%一致,但它锁定了噪点的初始状态,是后续所有生成的“基因锚点”。
2. 进阶核心:LoRA模型训练
如果是制作长达几十集的连续剧,仅靠提示词是不够的,目前文娱工业界的标准做法是训练专属的 LoRA。
- 📖 通俗解释: 如果大模型是通识百科全书,LoRA就是这本百科里夹着的一张“便利贴”。你只需要投喂 15-20张 同一角色的高质量图片,训练一个几十MB的小模型。
- 🚀 效果: 加载了专属LoRA后,无论你怎么写动作提示词,例如在吃饭、在打架、在哭泣,AI生成的脸部特征和服装细节都能保持 90%以上 的相似度。
3. 即时控制:IP-Adapter
对于不想训练模型的轻量级创作者,IP-Adapter(图像提示适配器) 是神器。
- ⚙️ 原理: 它允许你上传一张 参考图,告诉AI:“别管提示词怎么写,脸必须长这样。”
- 🛠 应用场景: 当你需要主角换衣服但脸不变,或者脸不变但换动作时,IP-Adapter能实现 “垫图生成”,权重设置在 0.6-0.8 之间,往往能达到惊人的锁脸效果。
4. 后期大招:InsightFace换脸修复
即使前三步做得很完美,在某些大的动态镜头,如大笑、回眸中,AI还是可能画崩。这时候,传统的 Face Swap(换脸) 技术作为最后一道防线登场。
- 利用 InsightFace 等插件,将定妆照的五官“贴”回跑偏的生成图中,是行业内修正瑕疵的常用手段。
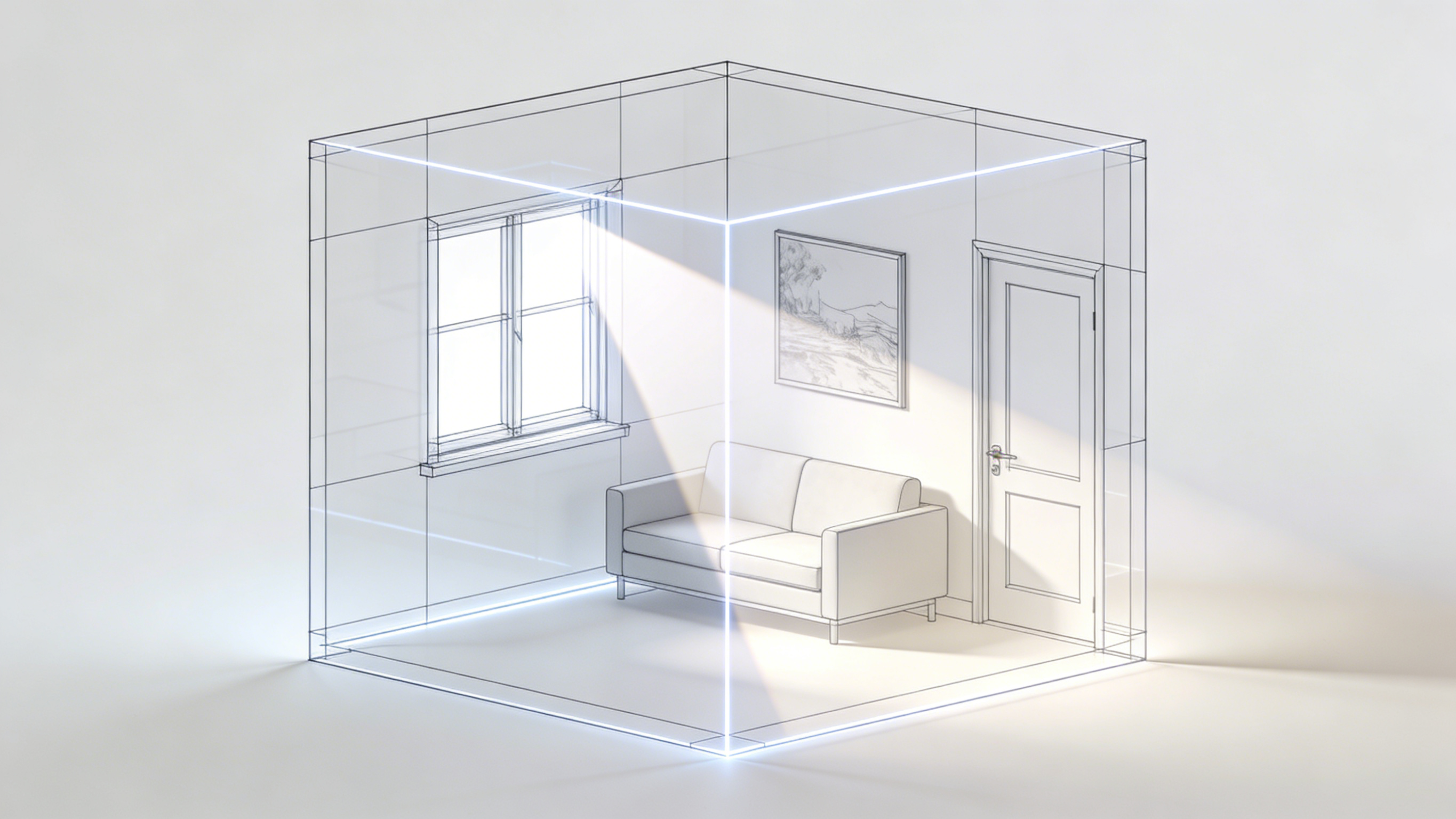
三、场景固化:搭建永不穿帮的“虚拟影棚”
人物稳住了,场景怎样实现不乱跳?在漫剧中,主角可能要在同一个房间待三集。如果墙上的画变来变去,观众会非常出戏。
1. ControlNet:AI界的“导演取景框”
ControlNet 是 Stable Diffusion 生态中的革命性工具,它让AI学会了“照葫芦画瓢”。
- ✏️ Canny/Lineart(线稿控制): 你可以用简单的简笔画勾勒出房间的透视结构,或者直接找一张实拍的空镜照片提取线稿。无论怎么重绘,房间的墙角、窗户位置永远固定。
- 📐 Depth(深度图): 控制场景的景深关系,确保主角永远站在前景,背景永远是那张沙发。
2. 局部重绘:只动该动的地方
在生成漫剧视频时,不要每次都重新生成整张图。
- 🔒 操作逻辑: 保持背景图层锁死,利用 蒙版 把主角所在的区域涂抹并重新生成。
- 🎥 视频化应用: 在 Runway 或 Pika 等视频工具中,使用运动笔刷涂抹人物,人物便会随之活动;而未被涂抹的背景则会像三脚架拍摄般保持稳定。这一方法有效解决了长期存在的“画面闪烁”与“背景液化”难题。
3. 3D辅助工作流
对于头部制作团队,最硬核的场景一致性方案是 “3D资产 + AI渲染”。
- 先在 Blender 或 UE5 里搭建一个粗糙的3D房间模型,截取不同角度的画面作为底图,再配合 ControlNet 进行AI渲染。这样无论镜头怎么推拉摇移,场景的空间结构都是物理正确的。

四、流程重构:建立工业标准的“生产闭环”
为了实现跨集一致性,单打独斗的工具是不够的,文娱公司需要建立 SOP:
📄 第一步:企划阶段 使用 ChatGPT/Claude编写剧本,并拆解为分镜描述。
⚓️ 第二步:资产阶段(定锚) Midjourney生成三视图与概念图;训练 角色 LoRA 模型,确立美术风格。
🎨 第三步:画面生成(生产) 使用 SD + ControlNet + LoRA 批量生成分镜;利用 IP-Adapter 确保脸部统一。
🎬 第四步:动态化(动效) 导入 Runway Gen-3 或 Luma 生成动态片段;使用 Sora 类模型做图生视频,利用首尾帧控制。
✂️ 第五步:后期合成 剪辑合成,并使用 ElevenLabs 等工具生成对口型台词。

五、价值跃迁:跨越抽卡游戏的“导演思维”
解决了一致性问题,意味着AI漫剧从 “随机艺术” 变成了 “可控工业”。
对于文娱产业而言,这带来了两个巨大的改变:
- 💰 IP孵化成本骤降: 以前验证一个网文IP是否适合改编动画,需要几百万做Demo。现在,两三个人的AI小组,一周就能做出一集高质量的漫剧样片。
- 💥 个性化内容爆发: 只要有了 LoRA 和流程控制,粉丝甚至可以自己训练模型,制作同人番外,UGC(用户生成内容)将反哺 PGC(专业生产内容)。
💡 结语
AI漫剧的控制力之战,本质上是人类审美意图与算法随机性的博弈。随着ControlNet、LoRA以及新一代视频模型的迭代,我们已经掌握了赢下这场博弈的筹码。
在这个时代,技术的迭代并非为了制造焦虑,而是为了释放想象。当我们真正掌握了AI一致性的“控制权”,它就不再是难以驾驭的黑盒,而是每一位造梦者手中最忠实、最强大的画笔。
