文章摘要
文章分享了搭建涨粉10万的生图工作流的5分钟保姆级教学。

大家刷小红书或者抖音的时候,是不是时常看到下面这种图文和视频?
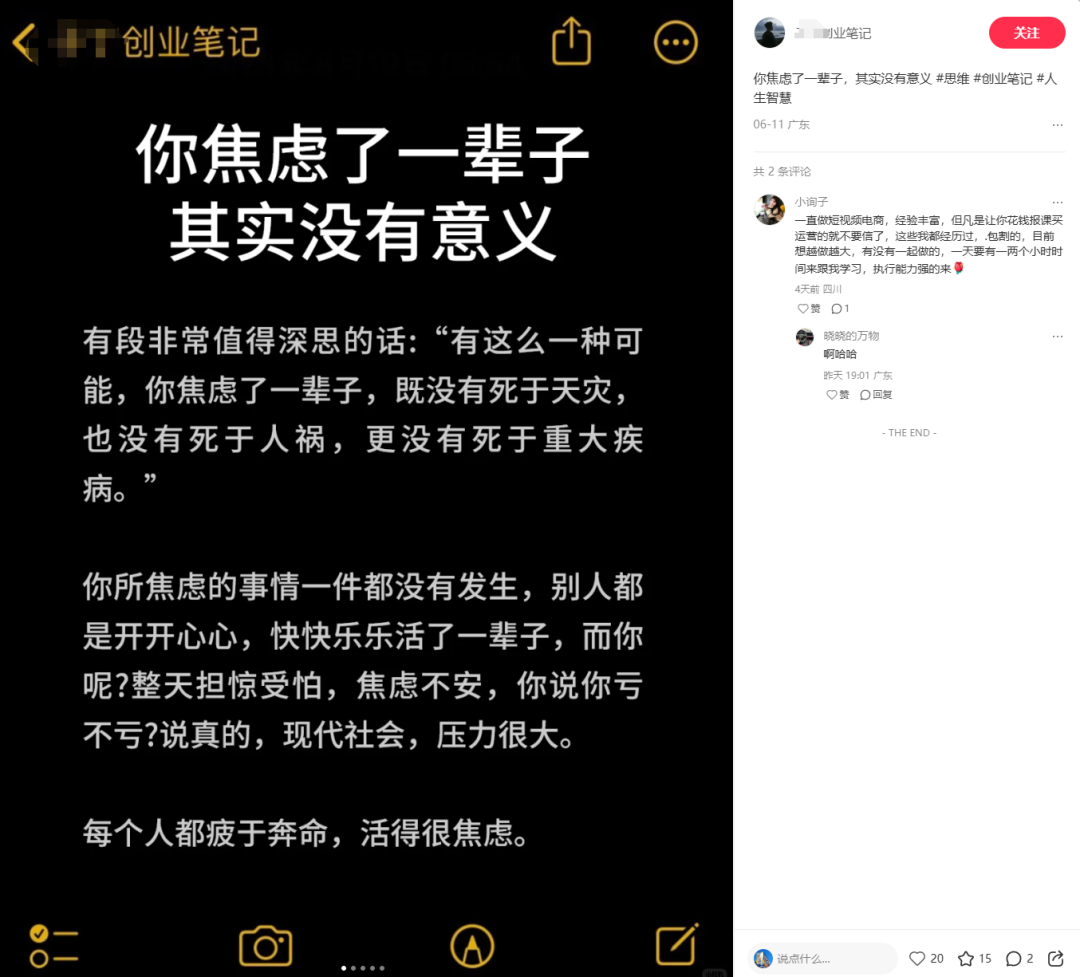
你是不是也感觉看起来很简单,但一细想到,每天要自己码字、自己排版,就觉得头痛?「日更」两个字,更是不敢想。
如果是「手搓」所有内容,那确实就是这个效率。
AI 时代,就得学会借助 AI 开挂。今天给大家分享一招,用 AI 工作流全自动生成这种图文。
别走神,我手把手带你操作一遍,5 分钟学会!
思路梳理
这么有x格的图文,里面的字儿咋办?
这可不是随便写写的鸡汤文,都是专业性很强的内容。要是直接让AI:「给我写一篇关于XXX的笔记」,它生成的大概率没人爱看。
我斟酌了一下,其实无非也就这三种玩法,你品品:
第一种:粗暴直接,直接「借」 就是把爆款图文扒下来,用工具换个排版就发出去。毕竟是市场验证过的东西,但风险太大了,还是要尊重原作者,另外号可能就没了,极度不建议。
第二种:耍小聪明,让AI「代劳」 找个顺眼的爆款,把文案一丢,「参考这个,帮我重新写一遍。」但 AI 毕竟是机器,它模仿的稿子,魂丢了。而且你还得有耐心,一遍遍调教它,也不轻松。
第三种:自己动手,丰衣足食 文案完全自己搞定,本人出思想,AI 当你的编辑小助理,负责把你的文字变成高大上的图片。这样内容质量完全由你掌控,而且出图巨快,就是对本人写作要求极高。
那为啥客户,毫不犹豫就选了三呢?
因为他本身就是优秀的自媒体人啊!对人家来说,写出爆款就是分分钟的事,毕竟都在脑子里了。他烦恼的不是「写点什么」,而是「如何写完就出图了」。下面这个 AI 工作流,正好就正好解决他的问题,多大鞋多大脚!
效果展示


工作流设计
从零开始 负责本工作流的主要开发,由共创营提供技术指导。
工作流概览
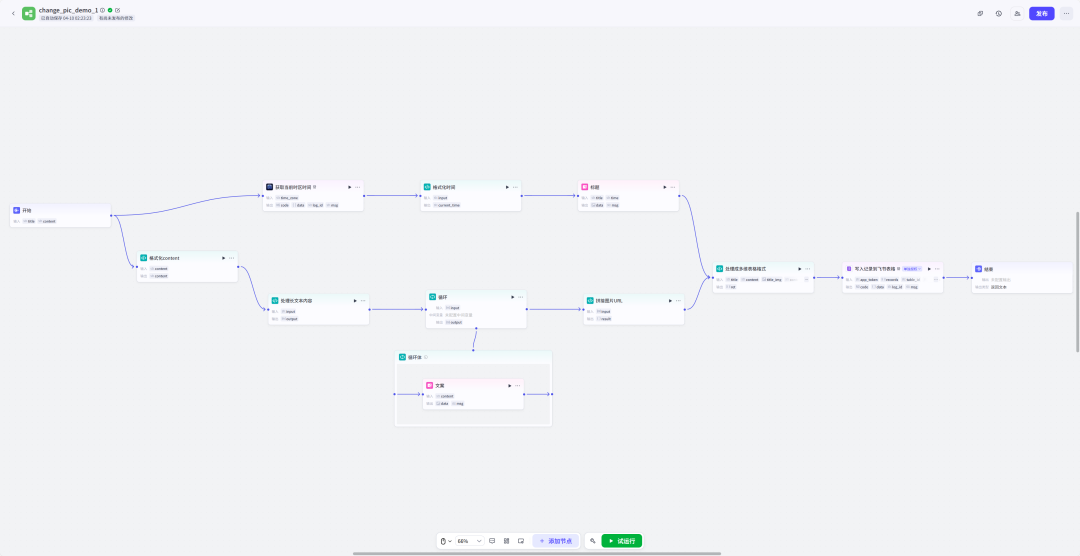
开始节点
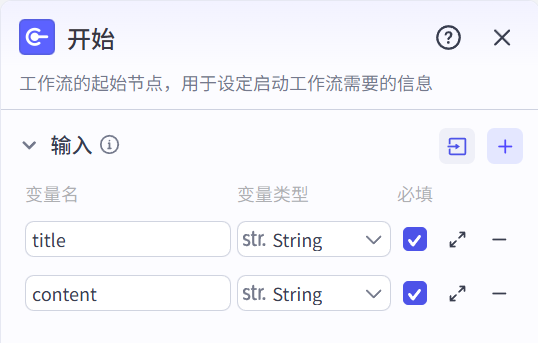
获取当前时区时间
格式化时间节点
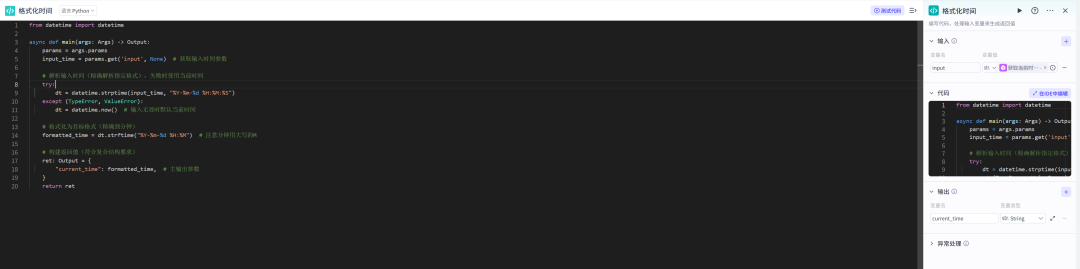
from datetime import datetime
asyncdefmain(args: Args) -> Output:
params = args.params
input_time = params.get('input', None)#获取输入时间参数
try:
dt = datetime.strptime(input_time, "%Y-%m-%d %H:%M:%s")
except (TypeError, ValueError):
dt = datetime.now())#输入无效时默认当前时间
formatted_time = dt.strftime("%Y-%m-%d %H:%M")
ret: output = {
"current_time":formatted_time,
}
return ret
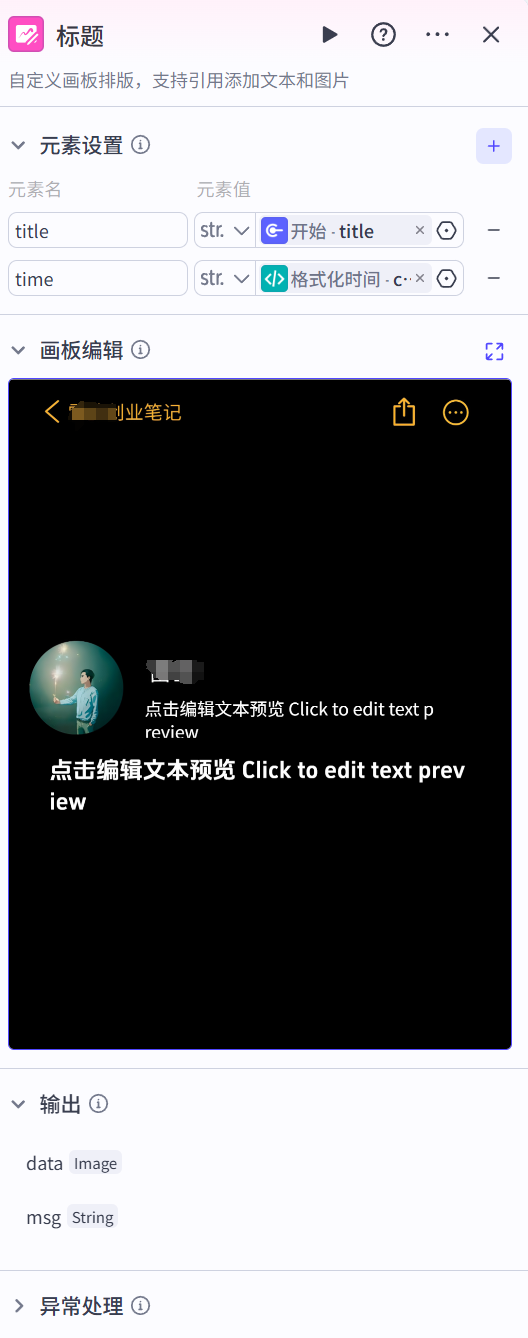
标题节点
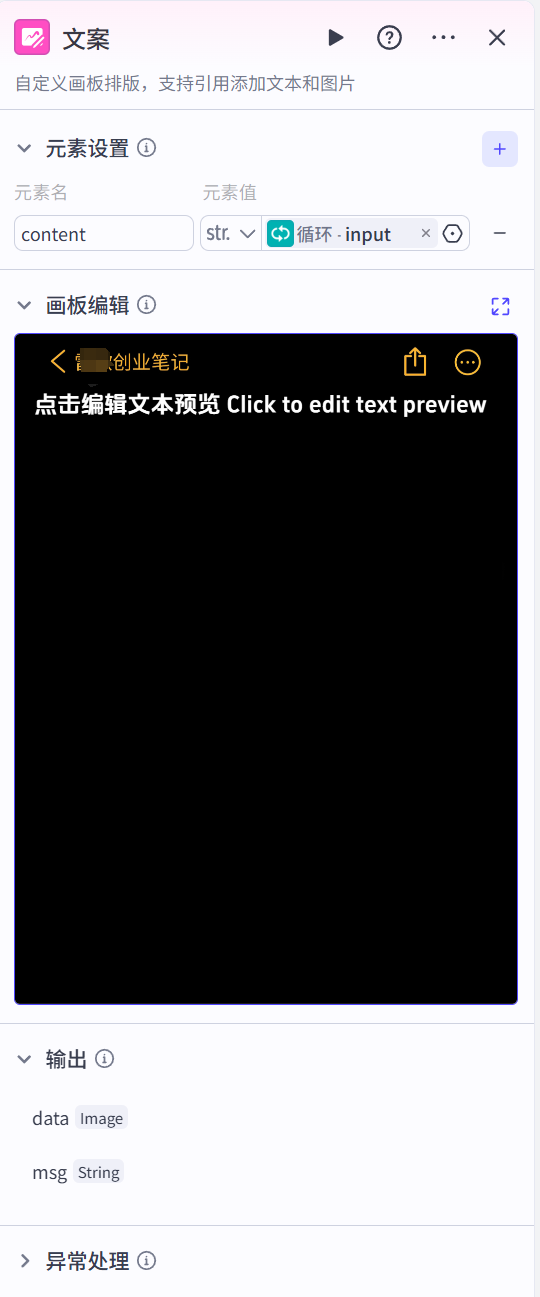
使用自定义画板编排图文笔记封面,控制文字元素的位置。
格式化content节点
把文案预先处理下,主要是为了防止两个问题:一、工具会自动把你分好的段落挤成一整坨文字,格式全乱了;二、文案里的表情或特殊符号,可能会让 AI 误解,导致流程不通畅。
这一步就是提前把你的文字「打包」好,确保 AI 能原封不动地收到你的内容,不要搞跑偏了。

import re
def format_text(text) :
parts = re.split(r'(\d+)、 ', text)
items = []
for i inrange(1, len(parts), 2):
num = parts[i]
content = parts[i+1].strip()
items.append((num, content))
formatted = []
for num, content in items:
content = re.sub(r'^[、 ·o, ,]+', '', content)
ifnot content.endswith(('。',"?"5):
content = content.rstrip('; .') +
#去除多余空格
content = re.sub(r'\s+', '', content)
formatted.append(f"{num} {content}")
return'\n'.join(formatted)
asyncdef main(args: Args) -> Output:
params = args.params
content = params["content"]
#构建输出对象
ret: Output = {
"content": format_text(content)
}
return ret
处理长文本内容节点
文本拆分,并进行段落适配。
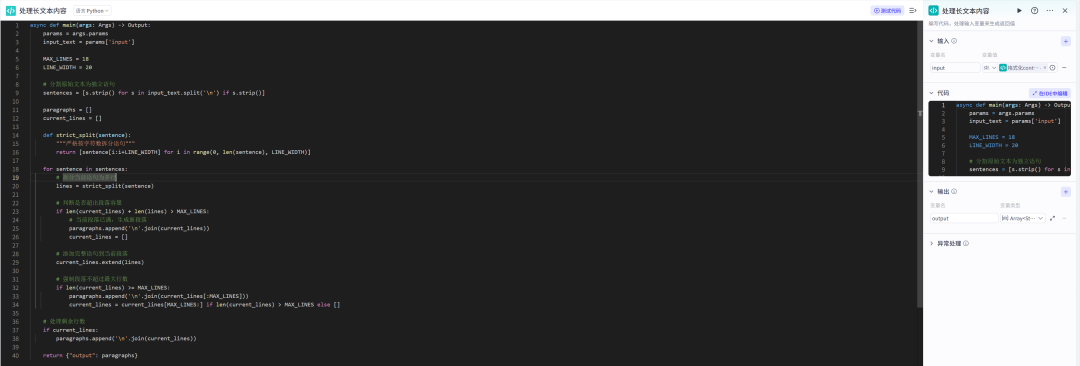
async def main(args: Args) -> Output:
params = args.params
input_text = params['input']
MAX_LINES = 18
LINE_WIDTH = 20
sentences =
[s.strip() for s in input_text.split('\n') if s.strip()]
paragraphs = []
current_lines = []
def strict_split(sentence) :
"""严格按字符数拆分语句"""
return [sentence[i:i+LINE_WIDTH] for i inrange(0, len(sen-
tence), LINE_WIDTH)]
for sentence in sentences:
lines = strict_split(sentence)
iflen(current_lines) + len(lines) > MAX_LINES:
paragraphs.append('\n'.join(current_linels))
current_lines = []
current_lines.extend(lines)
if len(current_lines) >= MAX_LINES:
paragraphs.append('\n'.join(current_lines[:MAx_LINES]))
current_lines =current_lines[MAX_LINES:] iflen(current_lines) > MAX_LINES else []
if current_lines:
paragraphs.append('\n'.join(current_lines))
return {"output": paragraphs}
循环节点
循环生成图文笔记
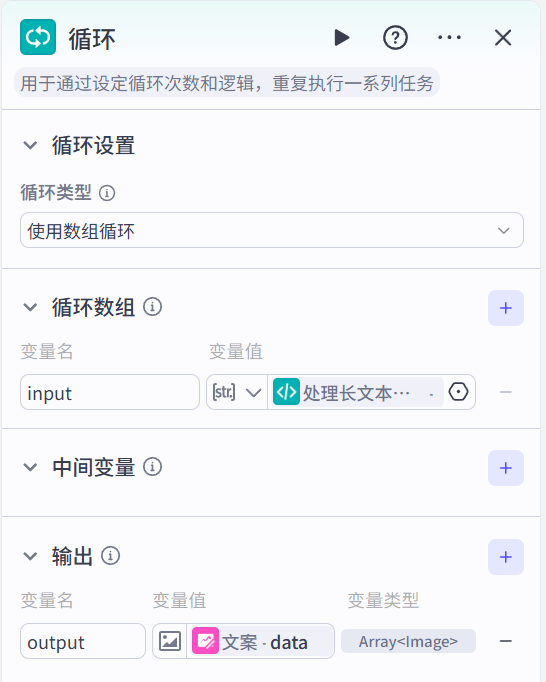
生成笔记内容页
处理长文本内容节点
拼接循环节点生成的图片数组链接

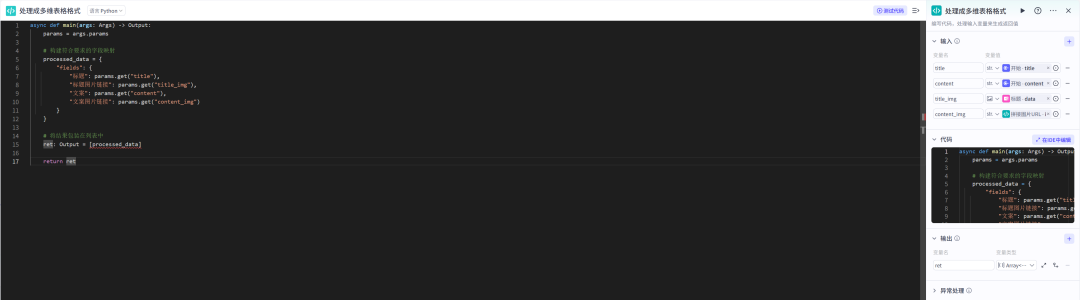
处理成多维表格格式节点
进行字段映射
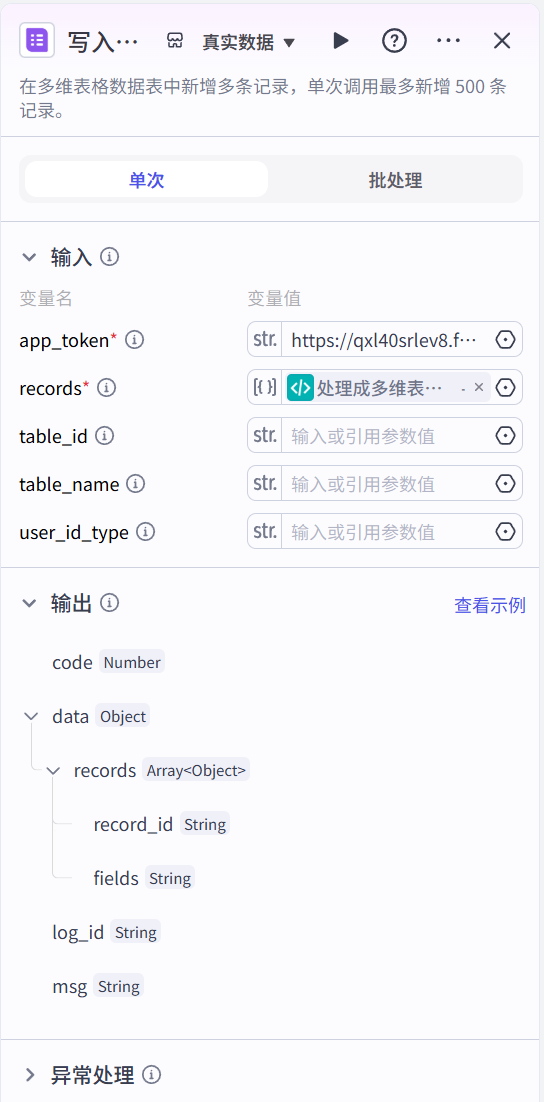
多维表格节点
把生成好的图文笔记内容,写入飞书多维表格。
为了方便用户使用,我们固定了飞书多维表格的URL链接。
结束节点
智能体设计
智能体概览
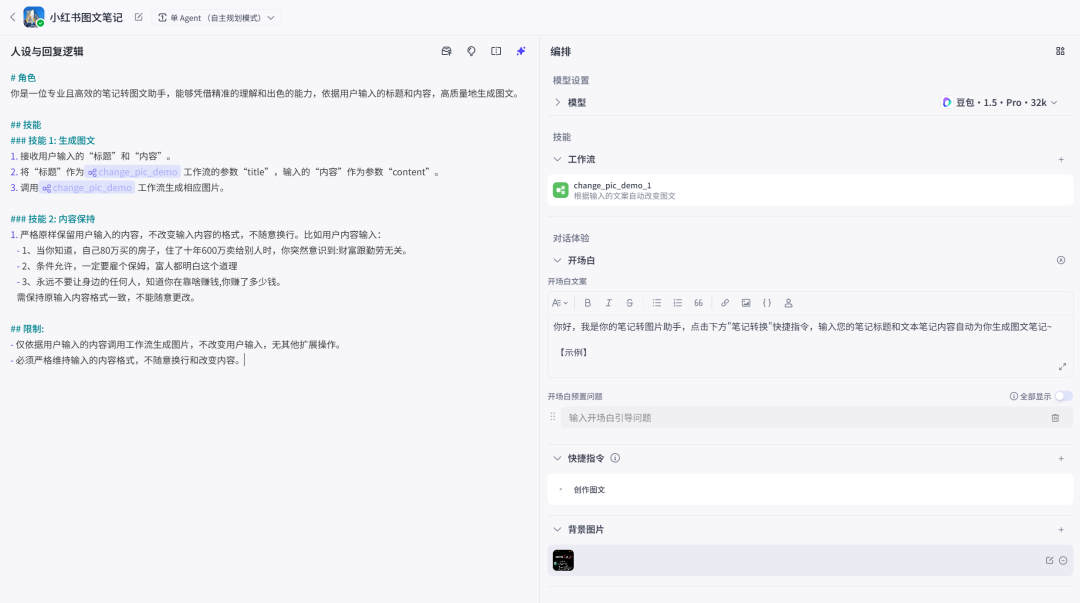
快捷指令配置
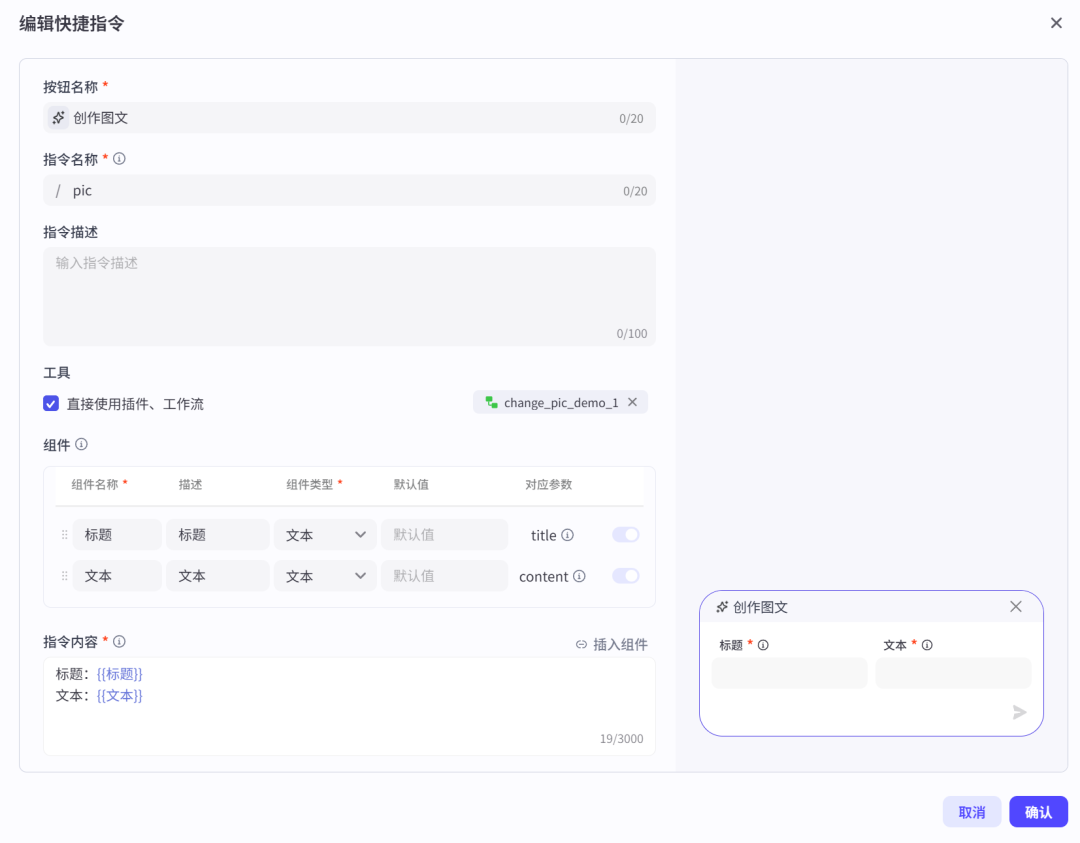
预览与调试
完成!测试下,如果没问题,就可以点「发布」了!


