

中国智源 Emu3 登顶 Nature:我们正在用最简单的逻辑重塑 AI



继 DeepSeek 之后,中国 AI 再次站在了世界科研之巅。
北京智源人工智能研究院研发的 Emu3 大模型,登上了顶级学术期刊 Nature 的正刊。
Emu3 的技术突破总结起来很简单,让模型能预测下一个 Token。过去大模型要多模态,能看、能听、能画、能写,现在这一技术的问世,告诉大家:不需要那么多复杂的零件,一个模型就能干所有事。

Emu3 登上 Nature 正刊
一、第一性原理
要理解 Emu3 为什么能让 Nature 折服,我们必须回看过去的多模态大模型。
1. 缝合怪
在 Emu3 之前,主流的多模态模型(如 Gemini、豆包)本质上是缝合怪。为了让 AI 既能创作又能绘画,技术通常会这样做:
- 一个文本编码器,负责理解文本
- 一个扩散模型,负责把噪点还原成图像
- 一个视觉编码器,负责看懂图片
这好像为了造一个全能机器人,把人的大脑、狗的鼻子、鹰的眼睛缝在了一起,结果就是,系统极度复杂,训练效率低下,且不同模态之间的隔阂始终存在。
2. Emu3 的统一
Emu3 把这些乱七八糟的组件全扔了。它回归到了大语言模型(LLM)最底层的逻辑,预测下一个 Token。
在 Emu3 的眼里,世界万物没有区别:文本是 Token;图像的像素块是 Token;视频的一帧画面也是 Token。
它只需要做一件事:**根据上文,猜出下一个 Token 是什么。**如果下一个 Token 是文字,它就在写作;如果下一个 Token 是视觉信号,它就在画图或生成视频。
这种通感,让 Emu3 成为了真正的多模态模型,也证明了 Transformer 架构具有普适性,可以是语言的容器,也可以是世界的模拟器。
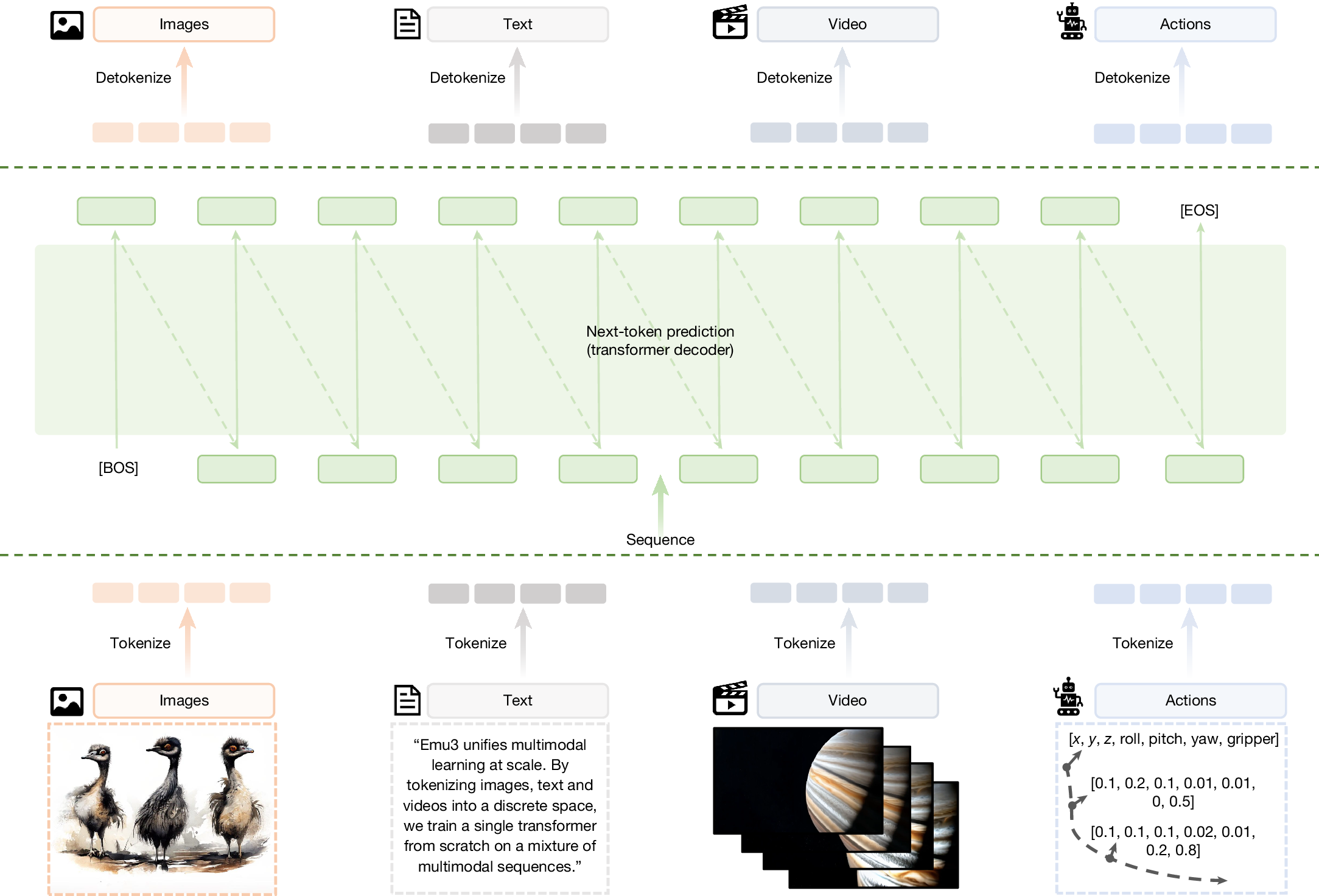
统一 Token 处理多模态数据
二、如何把世界塞进 Token 里?
上述虽然简单,但要实现它,会面临难题。智源团队在三个关键点上做到了极致。
1. 视觉分词器
如何把一张高清图片变成模型能读懂的文字?这就需要视觉分词器。
传统的处理方式太粗糙,容易丢失细节。而 Emu3 的分词器就像是一张二向箔,它能把一张 512×512 的高清图片,转化成 4096 个"视觉 Token"。
更厉害的是,它不仅能压缩空间,还能压缩时间。对于视频,它引入了 3D 卷积核,能够同时捕捉画面的空间信息(猫的耳朵在头顶)和时间信息(猫正在起跳)。这意味着生成的视频不再是一堆静态图的堆砌,而是有了连贯的动作逻辑。

Emu3.5 视觉分词器高清重建效果
2. 不同的方向
这是 Emu3 和主流模型不同的地方。目前市面上最火的生图模型(如 Midjourney 等),用的都是扩散模型,通过不断去除噪点来生成图像。
但 Emu3 坚持用自回归,像写文章一样,从左到右,一个像素块接一个像素块地写出图片。
Nature 的论文数据显示:Emu3 在图像生成质量上超越了基于扩散模型的 SDXL;在视频生成上,其 VBench 得分高达 81,甚至超过了早期的 Sora。
3. 速度的突破
自回归模型有一个天然的劣势:慢。因为要一个一个猜 Token,生成一张高清图可能要等 2 分钟。
为了解决这个问题,后续的 Emu3.5 引入了 DiDA(Distilled Diffusion Awareness)技术。简单来说,这是一种并行加速的黑科技。它把"一个人写文章"变成了"一群人写"。
**效果立竿见影:**生成一张 1024×1024 的大图,时间从 120 秒缩短到了 10 秒。在入门级显卡(如 NVIDIA L4)上,生成一张图只需要 2-3 秒。让 Emu3 具备了大规模落地的可能性。

Emu3 多任务生成效果展示
三、中国 AI 的换道超车
Emu3 登顶 Nature 有着深远的产业意义。
话语权的争夺
在很长一段时间里,多模态 AI 的技术路线是由谷歌和 OpenAI 定义。大家都在卷扩散模型,都在卷 CLIP。中国公司只能尝试弯道超车,而 Emu3 证明了,自回归路线不仅可行,而且上限更高。Nature 的认可,意味着中国科研机构开始参与并影响下一代 AI 的研究方向。
开源的胜利
智源作为非营利机构,Emu3 的代码、权重、训练数据处理方法,全部开源。任何创业公司、大学实验室,都可以基于 Emu3 构建自己的多模态应用。
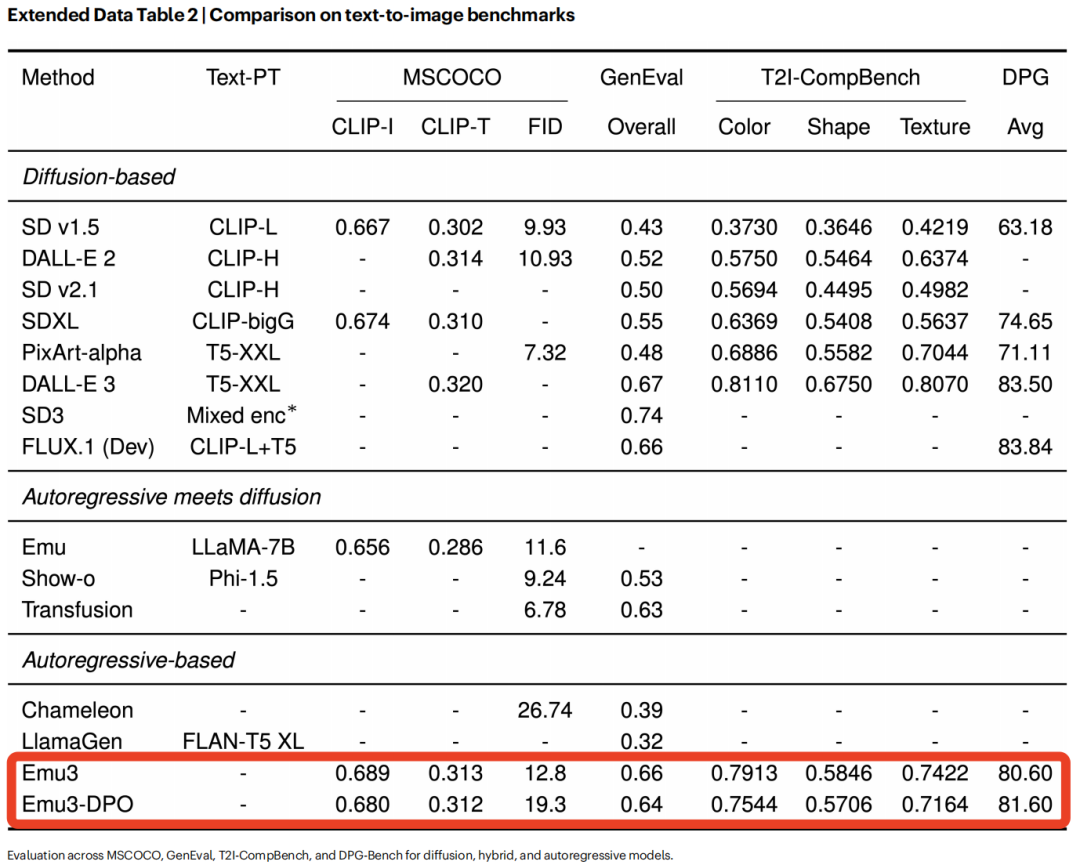
Emu3 超越主流扩散模型
四、结语
从 2022 年立项,到 2026 年登顶 Nature,Emu3 走过了一条孤独而坚定的路。
它没有选择最热门的赛道,而是死磕最底层的 Transformer 扩展性。它用 790 年的视频数据和 13 万亿 Token 的文本数据,跑出了一条新赛道。
Emu3 的成功告诉我们,真理往往是朴素的。
未来的 AGI,或许不需要复杂的模块,它只需要一条通向未来的直线,让 AI 像人类一样通过预测未来,来理解现在。而 Emu3,已经帮我们画出了这条线的起点。
