

OpenClaw(原名 Clawdbot)爆火后,我们离 Agent 规模化落地还有多远



OpenClaw 的爆火,让全球技术爱好者们狂欢。
我们用 OpenClaw 炒股、订机票、处理文件,但这股热浪却在企业端快速散去,因为过去 95% 的 Agent 项目都未能带来营收。
我们离真正的 Agent 规模化,还隔着数座难以逾越的大山。
一、规模化的难点
对于个人来说,OpenClaw 是有趣的,它满足了我们对 AI 管家的渴望。但对于企业来说,Agent 是昂贵的、不可控的、危险的。
任何东西的规模化,最终都得回归经济模型。如果 Agent 创造的价值覆盖不了它消耗的 Token、算力和维护成本,那么无论模型多么先进,在商业上都是不可行的。
可以说,目前的 Agent 更多还是惊艳的玩具,而不是可以规模化量产的产品。
1. 数据之痛
在监督微调模式下,我们需要专家来调试模型。为了获得高质量的任务数据,企业需要雇佣 985 博士生来进行标注。即使是高水平人才,标注一条数据也需要耗费 20 分钟。
这种高昂的成本直接限制了数据的规模,大部分团队只能标注了 200 多个任务,简单来说,我们在堆砌专家换取智能的提升,一旦场景变得复杂,Agent 就不好使了。
所以行业必须转向强化学习,让 Agent 在虚拟环境里自己试错。只有这样,才能把数据成本降低,用显卡替换专家,这也是英伟达这样的巨头正在做的事。
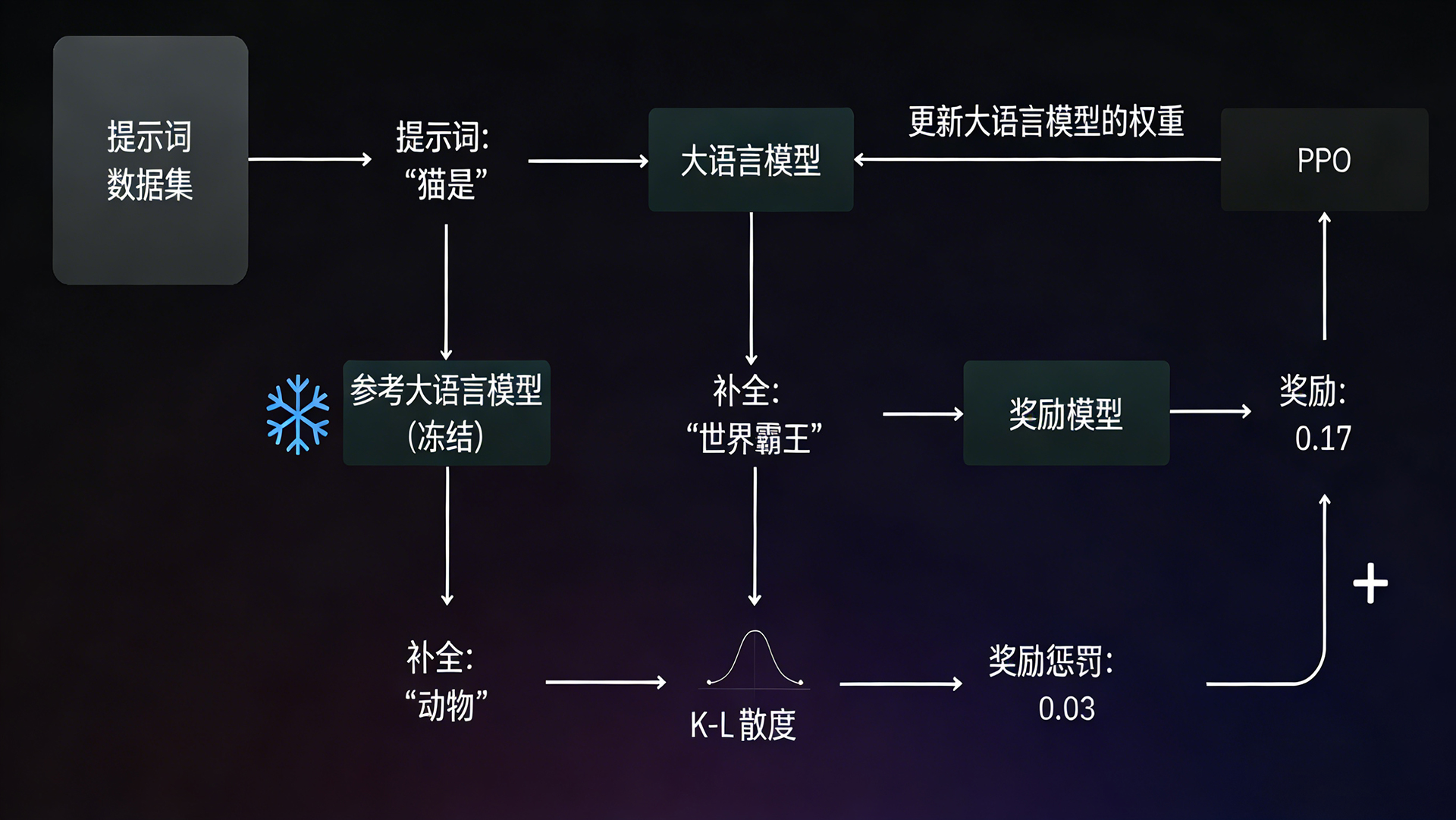 强化学习工作原理示意
强化学习工作原理示意
2. 基建之痛
当前 Agent 训练存在一个矛盾,GPU 算力很快,但操作系统还是龟速。
在传统的强化学习任务(比如下棋)中,环境反馈是毫秒级的,但在 Agent 训练中,Agent 在虚拟机里点击一次 Excel 按钮,需要经历"虚拟机渲染 → 截屏 → 图像回传 → 视觉模型处理"的漫长路程。
完成一个交互甚至需要 30 秒以上,当 GPU 在更新模型时,环境在等待;而当环境在采样数据时,GPU 又在空转。
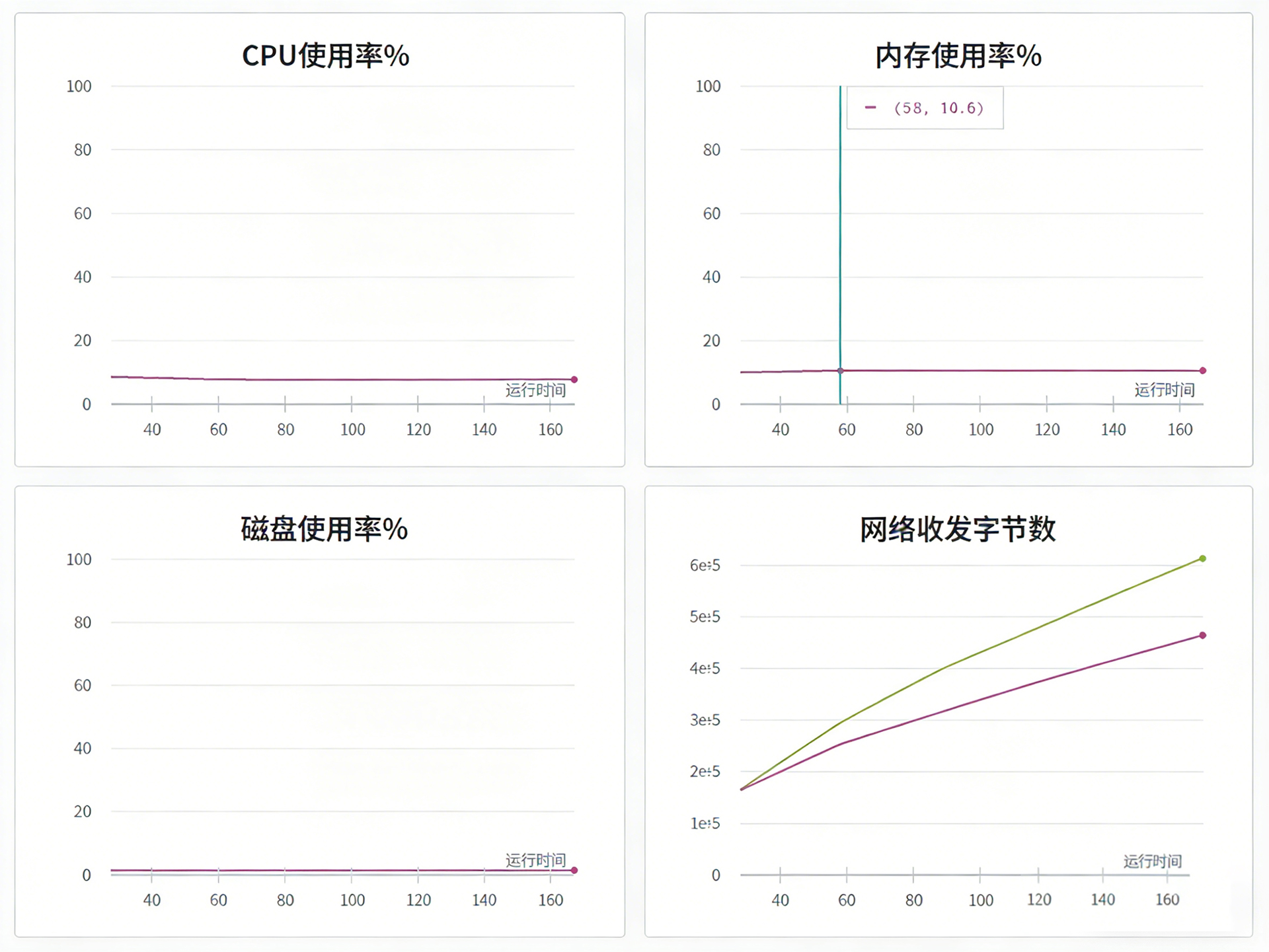 GPU 利用率监控,CPU 空转
GPU 利用率监控,CPU 空转
3. 记忆之痛
算力和环境之外,另一个问题是状态管理。很多人误以为长上下文就是记忆,只要把窗口拉长到 100 万 token 就行了。
但这是一个巨大的误区。对于企业级应用来说,客户不在乎你能读多少字,只在乎 AI 能不能记住"我上次说过什么"。
Agent 需要的是文件系统式的记忆,能随时精准调取,而不是在庞大的上下文窗口(临时缓存)。没有可靠的记忆,Agent 就永远是一个只有 7 秒记忆的金鱼,无法处理复杂的长程任务。
 ChatGPT 记忆力问题梗图
ChatGPT 记忆力问题梗图
二、硅谷与中国的破局
面对这几座大山,全球科技巨头们各有策略。
1. 硅谷:AAIF 的成立

2025 年 12 月,一个罕见的联盟诞生了。OpenAI、谷歌、微软、Anthropic 这些在模型领域打得头破血流的对手,联手成立了 AAIF(Agentic AI Foundation)。
他们的目的很明确:制定标准。
现在的 Agent 各自为战,OpenAI 的 Agent 听不懂 Anthropic 的指令。AAIF 试图通过 MCP 等协议,打破 Agent 之间隔阂。就像当年的 HTTP 协议定义了互联网一样,AAIF 试图为 Agent 通修一条标准化的高速公路。
2. 中国:成本与场景的突围

我国企业则选择了一条更务实的路径:降本与深耕场景。
DeepSeek 用 R1 模型证明了低成本训练的可行性。把模型价格打下来,是 Agent 能够普及的前提。如果每调用一次 Agent 都要花几美元,那企业还不如请人。
百度则在具体场景上发力。其"千帆深度研究 Agent"在 DeepResearch Bench 评测中登顶,能够在十几分钟内生成带引用的专业级研究报告。
这就是中国企业的优势,在应用层和降本上走得更快,更愿意在用户层找机会。
三、解法
为了解决龟速系统的问题,技术界正在进行解耦。
一种名为 Dart 的框架应运而生。其核心逻辑是将采样端与训练端在物理上彻底分开。GPU 专心负责训练模型,CPU 专心负责跑环境采样。
这种设计消除了 GPU 等待环境反馈的空转时间,实现了 5.5 倍的环境利用率提升。
同时,轻量化也成为趋势。不需要大规模集群,模块化设计让小团队也能训 Agent。研究者可以像搭积木一样,通过插件化配置自由组合算法组件,大幅降低了底层分布式的负担。
在商业层面,解法则是从通用助手转向垂类专家。百度做研报,阿里做电商客服。先在窄场景里把 ROI 跑正,再谈更多。
四、结语

OpenClaw 是极客的玩具,AAIF 是巨头的基建。两者的结合,才是 Agent 的未来。
要让 Agent 从玩具变成同事,便宜的数据(摆脱人工标注)、高效的系统(Dart 框架)、可靠的记忆(文件系统),我们必须给他配齐。
当这一切基础设施就绪时,Agent 的工业革命,才会开始。
