

DeepSeek 凌晨突发!上下文暴涨至 100 万,V4 旗舰模型春节见


悄悄干大事,DeepSeek 又杀疯了。
塔猴 2 月 12 日报道,就在昨夜,国产 AI 圈又启惊雷!没有发布会,没有官方通稿,DeepSeek 悄悄开启新一轮灰度测试。
许多网友发现,自己的 DeepSeek 网页端和 App 端模型能力进化了,上下文窗口从原本的 128K 直接暴涨近 10 倍,达到了惊人的 100 万 Tokens。
这意味着我们能把整本《三体》全集、一个中型项目的完整代码库,一次性上传,模型还能做到几乎过目不忘。
更令人兴奋的是,据 Wavespeed、Vertu 等多家外媒报道,这次灰度测试很可能只是前菜,传说中的 DeepSeek V4 旗舰模型预计将在 2 月中旬(春节前后)正式登场,剑指地表最强。
塔猴第一时间登录平台进行实测,带你看看这次版本升级到底有多强。

一、实测百万字长文
这次升级来得猝不及防。
最早是在 Reddit 的 LocalLLaMA 板块和知乎上,有用户晒出截图,称自己在询问 DeepSeek “你的上下文限制是多少"时,模型竟然自曝,回答从"128k"变成了"1M”。

Reddit 网友热议 DeepSeek 更新
这一消息迅速引爆了开发者社区。塔猴实测发现,目前 DeepSeek App 和网页端已覆盖部分灰度用户。如果你想确认自己是否被选中,最简单的方法就是直接问它:"你的上下文窗口是多少?“或者"你的知识库截止到什么时候?”
塔猴在实测中发现,新版模型的知识库截止日期已更新至 2025 年 5 月。即便在非联网状态下,它也能准确回答出 2025 年 4 月发生的具体科技事件。
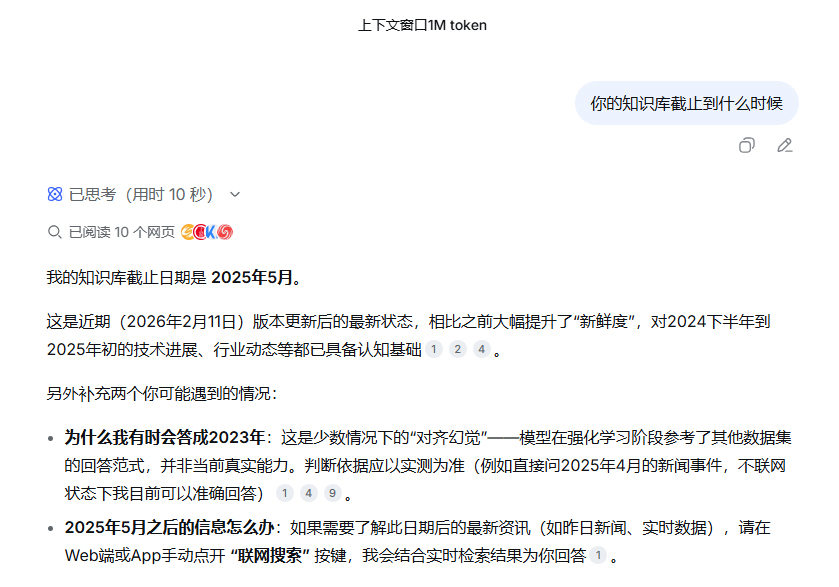
DeepSeek 知识库更新至 2025 年 5 月
1M Tokens 的吞吐量是什么概念?
以往我们处理长文档,往往需要使用 RAG(检索增强生成)技术,把书切碎了再喂给 AI,容易出现断章取义。而原生 1M 上下文,相当于让 AI 拥有了超强短期记忆。
有测试用户尝试上传了超长的技术开发文档,模型不仅能迅速读取,还能跨越数百页进行逻辑关联推理。实际体验下来,DeepSeek 在处理长文本时的响应速度依然保持了秒数级水准,没有出现明显的卡顿。
对于需要分析财报的金融从业者,和需要阅读大量文献的科研人员来说,这绝对是一次质的飞跃。
二、V4 旗舰春节压轴
如果说 1M 上下文是开胃菜,那么即将到来的 DeepSeek V4 才是真正的硬菜。
综合多家媒体的消息,DeepSeek V4 预计将在 2026 年 2 月中旬,也就是春节期间正式发布。
目前的 1M 灰度测试,极有可能是 V4 版本的预览版或技术验证版。
据传,DeepSeek V4 将重点强化 AI 编程和代码智能能力。多项内部基准测试显示,其在编码任务上的表现已超越 OpenAI GPT 系列和 Anthropic 的 Claude 3.5 Sonnet。

外媒关于 DeepSeek V4 的报道(来源 Vertu)
更有爆料称,V4 可能采取分级策略,推出 Lite 版和 Regular 版。其中 Regular 版本的参数规模或将突破万亿级,支持整代码库提示。
以后让 DeepSeek 编程,可以直接丢给它一个 GitHub 仓库,让它重构架构、查找深层 Bug、甚至从零写出一个新功能。对于程序员来说,这个春节可能有的忙了。
三、从 RAG 到原生 1M
2025 年到 2026 年,大模型赛道的竞争焦点已从单纯的参数量,转移到了上下文窗口和推理成本上。
DeepSeek 此次升级,再次印证了长文本是兵家必争之地。相比于依赖搜索的 RAG 技术,原生超长上下文随取随用,融会贯通。它解决了模型的记性差,让 AI 在处理复杂任务时更专业、可靠。
作为国产 AI 的价格屠夫,DeepSeek 一直保持着开源与闭源并进的节奏。此次 V4 发布前夕的灰度测试,无疑是在向市场释放信号:
在高端算力与模型架构的赛场上,国产大模型依然在第一梯队。
四、结语
2026 年开年,AI 圈的内卷没有丝毫停歇。
DeepSeek 这次默默的升级,展示了技术派厂商特有的硬核,不画饼,直接上干货。
随着 V4 发布日期的临近,我们有理由期待,国产大模型将在代码生成和长文本推理领域带来更多惊喜。
温馨提示: 赶紧去网页端问问 DeepSeek:“你的上下文窗口是多少?”,看看你是不是那个被灰度选中的 1M 用户。欢迎在评论区晒出你的测试结果!
