
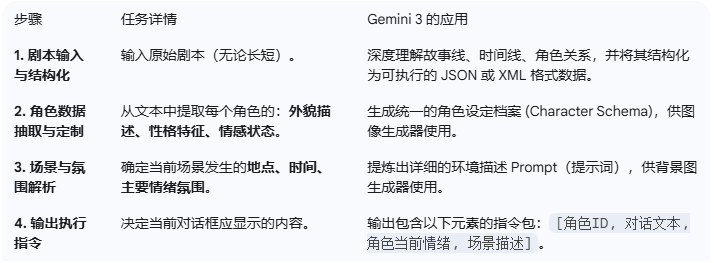
实现「Gemini 3 AI 漫剧游戏」的四阶段框架


这个系统需要利用 Gemini 3 作为中央智能大脑 (The Orchestrator),协调多个专业的 AI 工具链来完成复杂的实时内容生成任务。
阶段一:剧本解析与情景规划(Gemini 3 核心职能)
这一阶段主要利用 Gemini 3 的长上下文窗口和高级推理能力。
阶段二:实时视觉资产生成(与专业工具协作)
Gemini 3 输出指令后,系统会调用专业的文生图模型(例如 Google 的 Imagen 或其他优化模型)来生成视觉内容。
1. 角色立绘实时生成与一致性保持(最难点)
1. Prompt 工程: 将 阶段一 输出的 [角色ID, 外貌描述, 角色当前情绪] 组合为一个精确 Prompt。
a. 例如: 画一个25岁,黑长短发,手上拿着一把匕首,身穿学生制服的少年(角色ID:A),他正在表现出“防备”的表情,画风:日系 Galagame 风格。
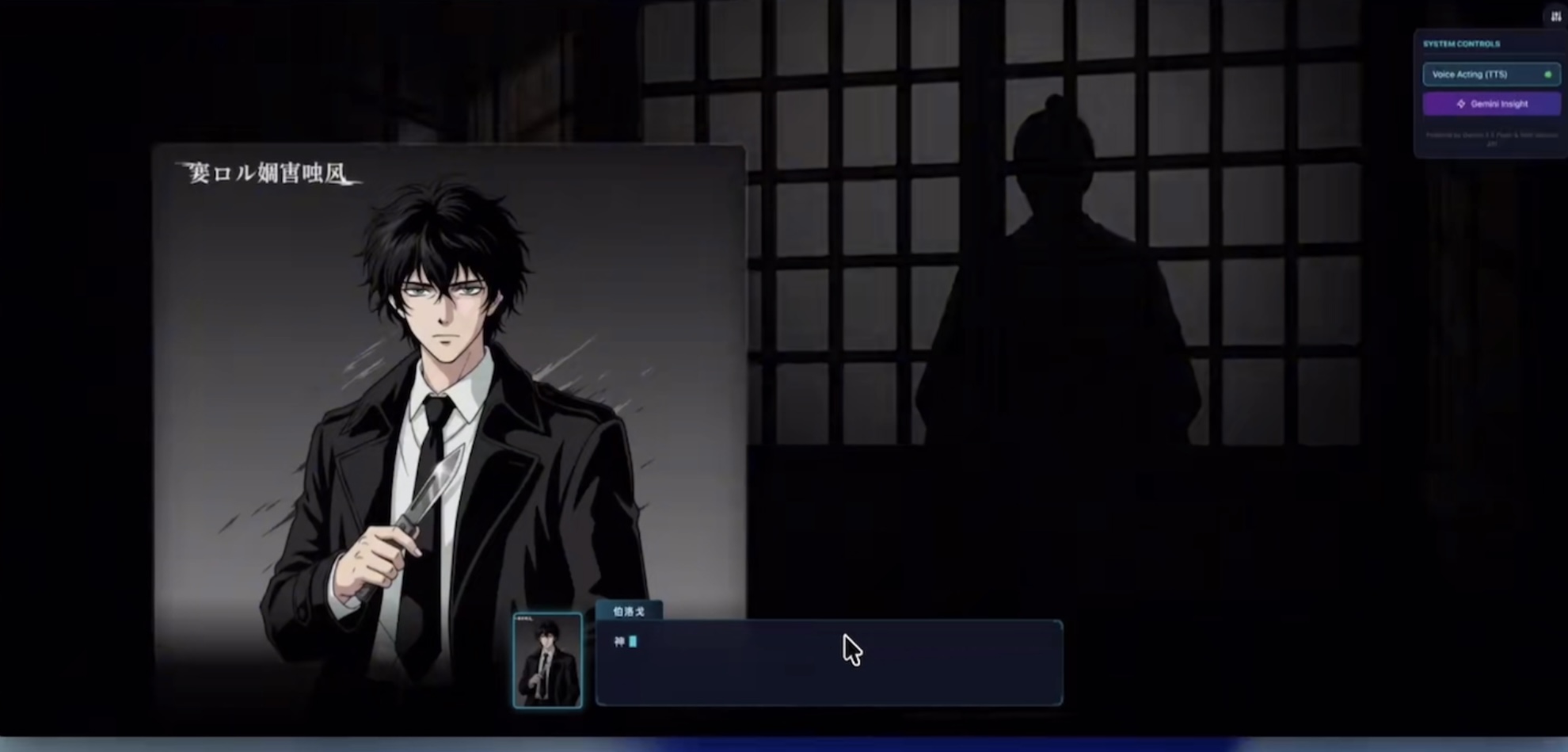
2. 一致性控制: 这是关键。可能需要利用 LoRA (Low-Rank Adaptation) 或 Hypernetworks 技术,在游戏开始前先针对每个角色训练一个小型模型权重,保证无论表情或姿势如何变化,角色的脸部特征和衣着细节始终保持一致。
2. 背景场景实时生成
1. Prompt 工程: 使用 阶段一 输出的 [场景描述]。
a. 例如: 一间晚上的日式房间,窗门上有一个黑色影子,氛围严肃而紧张。
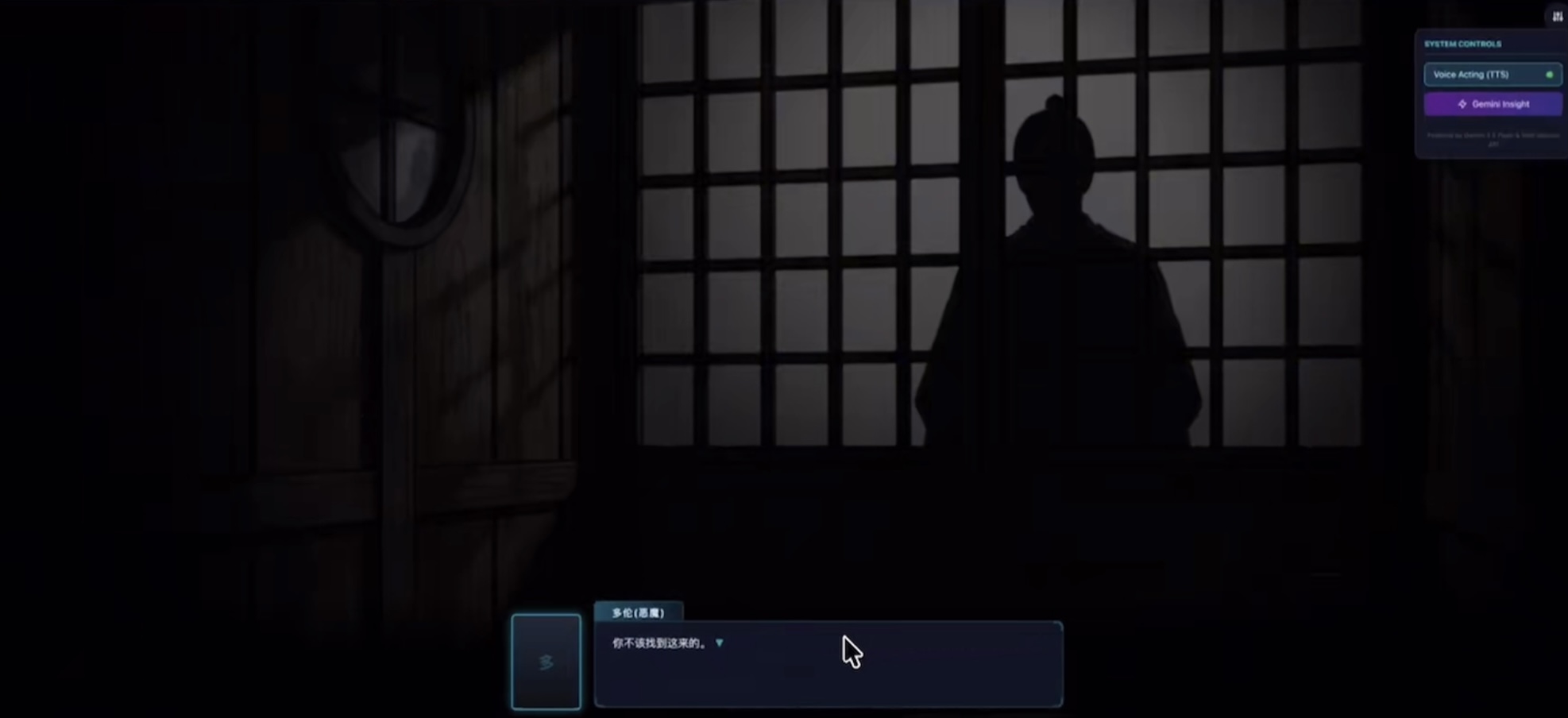
2. 图像渲染: 生成与游戏画风匹配的背景图像,并应用景深或模糊效果以突出前景角色。
阶段三:实时语音与交互整合
在视觉内容生成完成之后,需要音频输出和 UI 整合。
1. TTS 语音对话生成
1. 情感 TTS: 使用高质量的文本到语音 (TTS) 服务。
2. 输入: 接收 [对话文本, 角色当前情绪]。
3. 输出: 语音应根据情绪(如:惊讶、悲伤、喜悦)调整语速和音调。Gemini 3 或许能直接推荐最适合的情感标签,指导 TTS 服务。
2. 游戏前端整合
1. 将生成的 立绘、背景、对话文本 和 音频文件 实时载入到一个轻量级的 Galagame 交互前端(可能使用 Unity、Ren'Py 或 WebGL/JavaScript 框架)。
2. 等待用户点击屏幕或按键,触发下一条 Gemini 3 的指令。
阶段四:决策点与剧情分支(体现互动性)
当剧本来到一个决策点时,系统的互动性就体现出来了。
1. Gemini 3 的决策点识别: 识别出剧本中的关键选择,并生成 2-4 个选项供玩家选择。
2. 长上下文影响: 玩家的每一次选择将作为新的输入,被存储在 Gemini 3 的长上下文记忆中,进而影响后续剧情的走向和角色的回应。
3. 实时剧情续写: 玩家选择后,Gemini 3 不仅执行预设的剧本线,还能根据用户选择和当前角色关系,
