
商业级配音革命:ElevenLabs "Voice Changer" (原 STS) 多语种实操指南


目录导航
- 前言:告别“棒读”,AI 配音的下半场
- 核心逻辑:为什么 TTS 满足不了 3A 叙事?
- 功能定位:Voice Changer (变声器) 的表演驱动机制
- 实操流程:从录制表演到 AI 变声 (最新 UI 路径)
- 参数调优:控制 AI 的“演技”与“稳定性”
- 结语:让策划直接变成配音导演
前言:告别“棒读”,AI 配音的下半场
在 2023 年,我们谈论 AI 配音时,主要是在谈论 Text-to-Speech (TTS) —— 输入文本,AI 读出来。虽然 ElevenLabs 的 TTS 已经是行业天花板,但在面对游戏剧情中复杂的“阴阳怪气”、“濒死喘息”或“歇斯底里”时,纯文本驱动依然显得力不从心。2024 年起,ElevenLabs 将其核心的 Speech-to-Speech (STS) 技术独立产品化,命名为 “Voice Changer (变声器)”。这彻底改变了工作流:现在,我们不再是“输入文字”,而是“输入表演”。
本文将带你通过最新的 Voice Changer 功能,实现 “你对着麦克风演一遍,AI 用史诗级声线完美复刻”的商业级工作流。
核心逻辑:为什么 TTS 满足不了 3A 叙事?
传统的 TTS 有一个致命缺陷:情感颗粒度不够。
比如台词:“哈?你救了我?”
- TTS 理解:这是一个疑问句,语调上扬。
- 剧情需要:这可能是一句讽刺,需要先冷笑一声,然后语调下压。
Text-to-Speech 很难通过 Prompt 精准控制重音和停顿。而 Voice Changer (基于 STS 技术) 的逻辑是:“保留韵律,替换音色”。 开发者(甚至策划本人)只需要对着麦克风录制一段拥有正确情绪、停顿和语气的“草稿”,ElevenLabs 就能保留这段表演的灵魂,将其“换肤”成好莱坞级别的旁白音或萌妹音。
功能定位:Voice Changer (变声器) 的表演驱动机制
在最新版界面中,STS 技术主要承载于 Voice Changer 模块中,它包含两个核心价值:
1. 跨越语言的音色克隆 (Cross-Lingual Cloning)
你可以用中文录制一段话,然后让 AI 用完全相同的音色,说出流利的英语、日语或德语。这对于游戏出海 (Global Launch) 意味着:你只需要这一个“声音 IP”,就能覆盖全球市场,无需在每个国家单独雇佣 CV。
2. 情感传递 (Emotion Transfer)
这是重点。如果你在录音源文件中加入了叹气、笑声、犹豫的结巴,AI 在生成时会极力保留这些非语言特征 (Non-verbal cues)。这是让 NPC 活过来的关键。
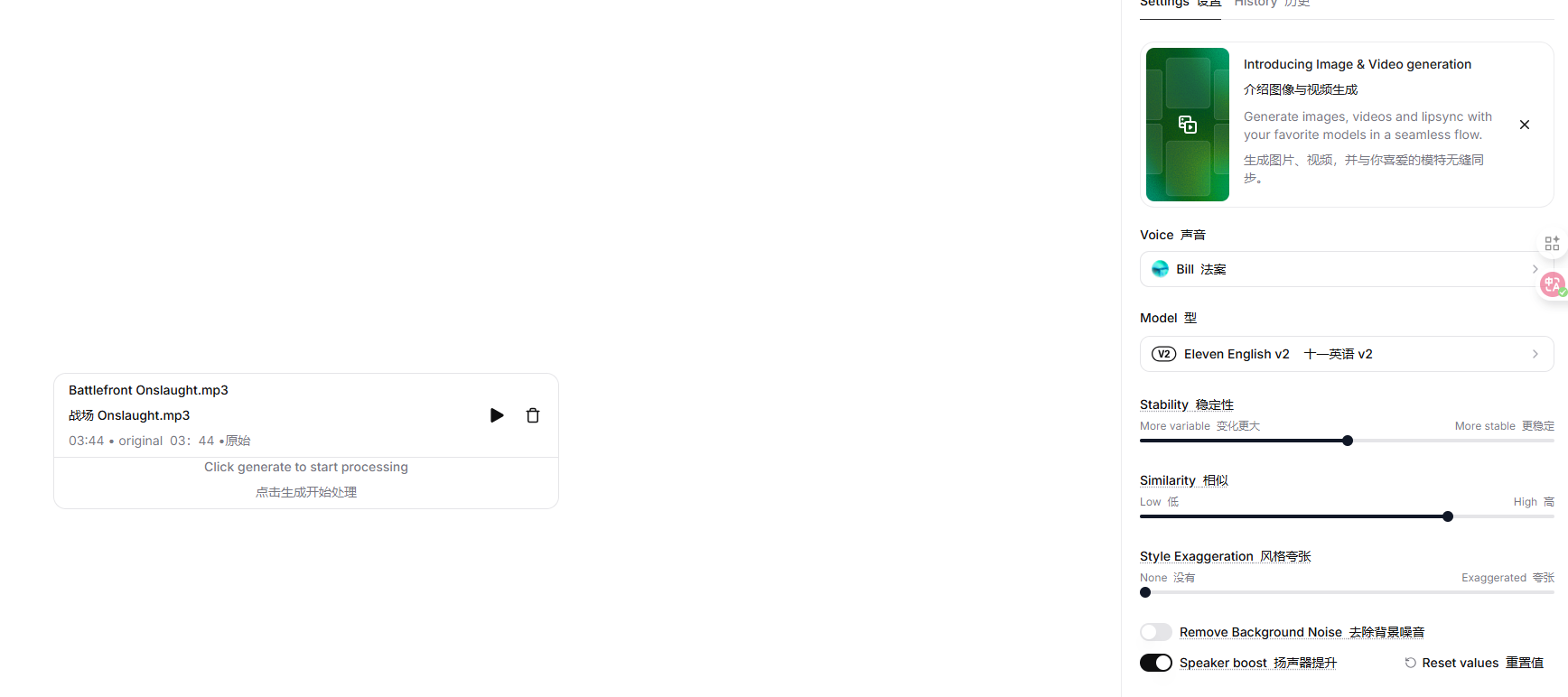
- 图注:STS 工作流逻辑:左侧输入“粗糙的人声表演” -> 中间经过“ElevenLabs 模型处理” -> 右侧输出“目标音色 + 原始情感”的高品质音频。
- 配图目的:帮助读者理解 Voice Changer 不是简单的变声器,而是基于生成的音色重构。
实操流程:从录制表演到 AI 变声 (最新 UI 路径)
下面是一套标准化的生产管线,基于 PC 端 Chrome 浏览器操作。
Step 1. 声音克隆 (Voice Cloning)
首先,你需要一个“目标音色”。
- 进入左侧导航栏的 Voices -> VoiceLab。
- 点击 Instant Voice Cloning(商业版推荐 Professional Voice Cloning,效果更细腻)。
- 上传 1-5 分钟干净的干声素材(WAV 格式,44.1kHz)。
- 注意:素材的情绪要尽可能丰富,不要只上传平淡的朗读流。
Step 2. 找到功能入口 (UI 避坑关键)
在 2025 年的新版界面中,不要在 Speech Synthesis 里死磕。请直接看左侧导航栏:
- 找到 Products 或 Tools 区域。
- 点击 Voice Changer 图标(通常是波形图或人像互换图标)。
- 如果左侧没有,直接访问地址:
https://elevenlabs.io/app/voice-changer。
Step 3. 上传参考表演 (Source Input)
进入 Voice Changer 界面后:
- Upload Audio:上传策划试配的音频文件(支持 MP3/WAV)。
- 或者 Record Audio:直接点击麦克风录制。
- 表演要点:夸张一点。AI 会稍微平滑掉一些极端情绪,所以在源文件中,你的语速快慢、重音起伏要比平时说话更用力。
Step 4. 生成变声
- 在 Output Voice 下拉菜单中,选择你刚才在 Step 1 克隆好的目标音色。
- 点击 Generate。系统会消耗字符数(Characters)进行生成。
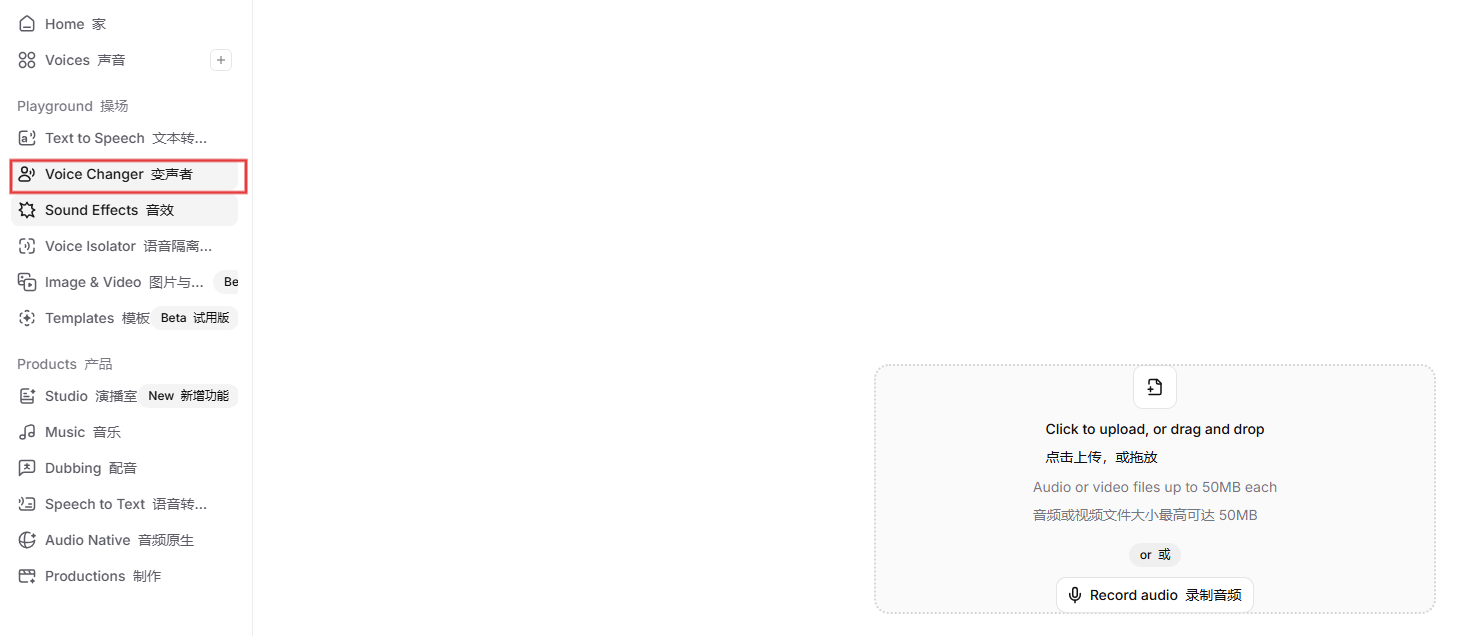
- 图注:ElevenLabs 最新 Voice Changer 界面。红框高亮了左侧导航栏的“Voice Changer”入口,以及中间的“Upload Audio”区域。
- 配图目的:修正旧版教程的误导,帮助用户快速定位新功能入口。
参数调优:控制 AI 的“演技”与“稳定性”
在 Voice Changer 界面右边,通常有 Voice Settings。很多开发者觉得 AI 配音“飘忽不定”,通常是因为没有调教好这三个核心滑块。
1. Stability (稳定性)
- 定义:控制 AI 发挥的随机性。
- 数值建议:
- 30% - 50%:适合游戏角色配音。允许 AI 有更多的抑扬顿挫,哪怕偶尔出现一点破音,也能增加真实感。
- 80% - 100%:适合新闻播报/新手引导。声音非常稳,但很平,像机器人。
- 秘籍:如果觉得配音太死板,把 Stability 降到 35% 试试。
2. Similarity (相似度)
- 定义:控制生成声音与克隆源素材的相似程度。
- 数值建议:75% 是黄金分割点。
- 拉到 100% 会强制 AI 模仿源素材的底噪和录音瑕疵,反而导致音质下降。
- 保持在 70%-80%,AI 会在保留音色特征的同时,利用自带的高清数据修补音质。
3. Style Exaggeration (风格夸张度)
- 定义:仅在 v2/v2.5 模型生效,控制对输入音频风格的放大程度。
- 数值建议:0% (None) 到 20%。
- 除非你在做极其卡通夸张的角色,否则不要开高。开高了容易导致 AI “胡言乱语”或产生电流麦。
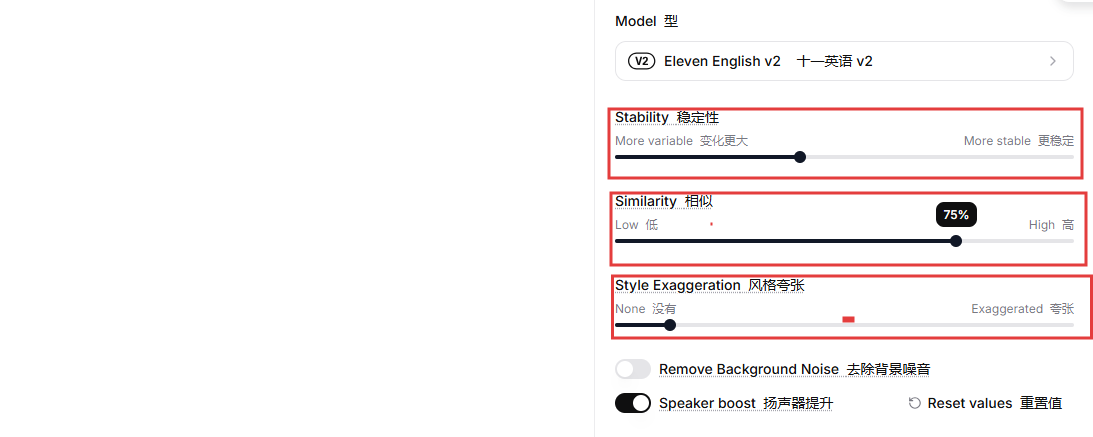
- 图注:Voice Settings 面板详解。展示了 Stability, Similarity, Style Exaggeration 三个滑块的推荐位置(呈“左低右高”的阶梯状)。
- 配图目的:提供“抄作业”级别的参数设置,减少用户的试错成本。
结语:让策划直接变成配音导演
ElevenLabs 的 Voice Changer (STS) 功能,实际上是将“配音 (Acting)”和“音色 (Timbre)”解耦了。
- 过去:你需要找一个既有“萝莉音”又有“好演技”的配音演员,这很难,也很贵。
- 现在:你只需要找一个懂戏的策划录制表演(Acting),再找一个好听的 AI 模型(Timbre),两者一合成,就是完美的资产。
对于独立游戏出海而言,这不仅是成本的节省,更是创作控制权的回归。你终于可以指着音频波形说:“这里的语气,必须是我刚才演的那样!”
Tags: #游戏配音 #ElevenLabs #VoiceChanger #AI语音 #本地化 #游戏出海 #SpeechToSpeech #音频设计#
