
零基础学AI大模型之LangChain Embedding框架全解析


前情摘要
8、零基础学AI大模型之LangChain六大核心模块与大模型IO交互链
10、零基础学AI大模型之LangChain-PromptTemplate
11、零基础学AI大模型之ChatModel聊天模型与ChatPromptTemplate实战
12、零基础学AI大模型之LangChain聊天模型多案例实战
15、零基础学AI大模型之解析器PydanticOutputParser
16、零基础学AI大模型之LangChain Output Parser
17、零基础学AI大模型之大模型修复机制:OutputFixingParser解析器
20、零基础学AI大模型之RAG系统链路解析与Document Loaders多案例实战
21、零基础学AI大模型之LangChain PyPDFLoader实战与PDF图片提取全解析
22、零基础学AI大模型之LangChain WebBaseLoader与Docx2txtLoader实战
23、零基础学AI大模型之RAG系统链路构建:文档切割转换全解析
24、零基础学 AI 大模型之 LangChain 文本分割器实战
25、零基础学AI大模型之Embedding与LLM大模型对比全解析
零基础学AI大模型之LangChain Embedding框架全解析
一、为什么需要LangChain的Embedding模块?—— 解决"模型适配难题"

在之前的学习中,我们知道文本嵌入(Text Embedding)是RAG系统的核心环节——将分割后的文档片段转为向量,才能存入向量数据库进行检索。但实际开发中会遇到一个问题:
- 不同场景需要不同的Embedding模型(比如追求精度用OpenAI的text-embedding-3,注重隐私用本地开源的Sentence-BERT);
- 每个模型的调用方式、参数格式、返回结果都不一样(比如阿里云的API需要传入
dashscope_api_key,而HuggingFace模型需要指定model_name)。
这就像你有一堆不同品牌的手机,每个手机的充电接口都不一样,每次充电都要换充电器——效率极低。而LangChain的Embedding模块,就相当于一个"万能充电头":通过标准化接口封装了各种Embedding模型,让开发者用统一的方式调用不同模型,无需关心底层实现细节。
二、LangChain Embedding核心功能:标准化接口的威力
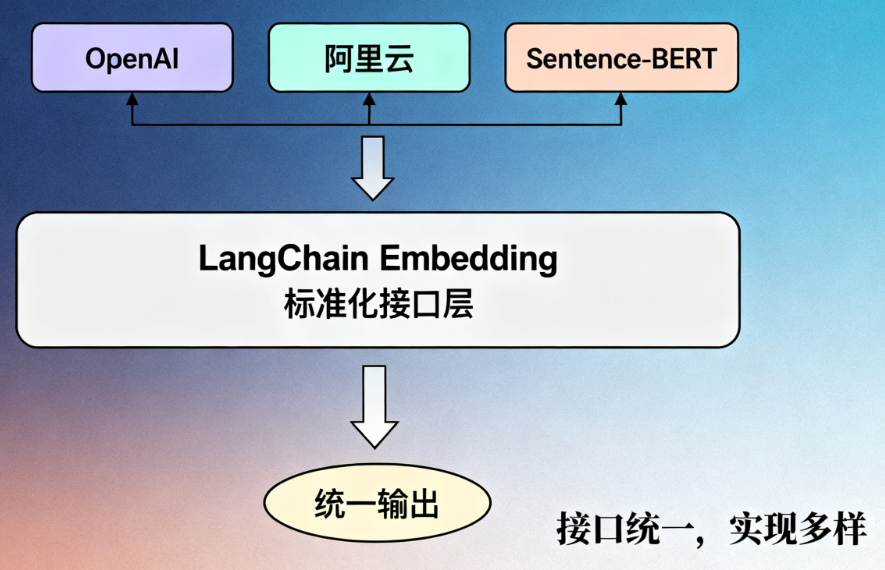
LangChain对Embedding的核心设计理念是"接口统一,实现多样"。简单说就是:
- 不管你用的是OpenAI、阿里云还是本地开源模型,都通过相同的方法(如
embed_query、embed_documents)调用; - 输出结果的格式完全一致(都是浮点型向量列表),后续的向量存储、相似度计算逻辑可以复用。
这种设计带来两个显著优势:
- 降低切换成本:今天用OpenAI的模型,明天想换成开源的BERT?只需修改初始化代码,其他逻辑不用动;
- 简化协作开发:团队中有人熟悉阿里云模型,有人擅长本地部署?统一接口让代码兼容无压力。
三、源码解析:Embedding的"标准协议"是什么?
LangChain通过抽象基类(ABC)定义了Embedding的"标准协议",所有集成的模型都必须遵守这个协议。我们来看核心源码:
关键解读:
Embeddings是所有嵌入模型的父类,通过@abstractmethod强制子类实现两个核心方法;embed_documents:处理批量文档(比如初始化向量数据库时,把1000个文档片段转成向量);embed_query:处理单个查询(比如用户实时提问时,把问题转成向量去匹配数据库)。
这种设计就像"电器接口标准"——只要符合标准,不管是哪个品牌的电器(模型),都能插上电源(接入LangChain流程)。
四、LangChain支持的3类Embedding模型:各自适用什么场景?
LangChain几乎兼容市面上所有主流的Embedding模型,按部署方式可分为3类,各自有明确的适用场景:
模型类型 | 代表模型 | 核心特点 | 适用场景 |
|---|---|---|---|
云端API | OpenAI的text-embedding-3系列、阿里云DashScope、Google PaLM Embedding | 无需本地资源,调用简单;但需要联网,按调用量付费 | 快速原型开发、中小规模应用(如企业客服知识库) |
本地开源模型 | Sentence-BERT、E5、FastText | 数据无需上传云端,隐私性好;但需要本地算力支持(建议至少8G内存) | 医疗、金融等对数据隐私敏感的场景,或离线部署需求 |
自定义微调模型 | 基于BERT微调的行业模型(如法律、医疗领域) | 针对特定领域优化,语义理解更精准;需要数据标注和训练资源 | 垂直领域应用(如法律文档检索、医学文献分析) |
五、核心API与属性:调用Embedding模型的"必知参数"
无论使用哪种模型,LangChain的调用方式都高度统一,掌握以下API和属性即可应对大部分场景:
5.1 两个核心方法
- embed_query(text: str) → list[float]
- 功能:将单个文本(如用户问题)转为向量
- 示例:
- embed_documents(texts: list[str]) → list[list[float]]
- 功能:批量转换多个文本(如分割后的文档片段)
- 示例:
5.2 实用属性(以云端API为例)
- max_retries:API调用失败时的重试次数(默认1,建议设为3应对网络波动);
- request_timeout:单次请求超时时间(单位秒,默认60,长文本处理可设为120);
- api_key:云端模型的密钥(如OpenAI的
openai_api_key、阿里云的dashscope_api_key)。
六、实战案例:用阿里云DashScopeEmbeddings处理商品评论
下面以阿里云的文本嵌入模型为例,演示如何在LangChain中实现文本转向量,并用向量分析商品评论的语义特征。
6.1 准备工作
- 注册阿里云账号,获取
dashscope_api_key(地址:https://bailian.console.aliyun.com/); - 安装依赖:
6.2 代码实现:商品评论向量转换
6.3 输出结果解读
- 每条评论都被转换为1536维的向量(模型固定维度);
- 向量中的数值是模型对文本语义的编码,后续可通过计算向量距离(如余弦相似度)分析评论的相似性(比如“物流太慢”和“尺寸偏小”都是负面反馈,向量距离会较近)。
七、避坑指南:使用LangChain Embedding的3个注意事项

- 向量维度匹配:不同模型的向量维度不同(如OpenAI是1536维,Sentence-BERT是384维),同一向量数据库必须使用相同维度的模型,否则无法计算相似度;
- 长文本处理:部分模型对输入文本长度有限制(如OpenAI单文本最多8191 tokens),超过会截断,建议结合之前学的文本分割器预处理;
- 本地模型性能:开源模型在CPU上运行速度较慢(1000条文本可能需要几分钟),生产环境建议部署到GPU服务器(如NVIDIA T4以上)。
八、总结:LangChain Embedding是RAG的"向量转换枢纽"
LangChain的Embedding模块通过标准化接口,解决了不同嵌入模型的兼容问题,让开发者可以"一键切换"模型,专注于业务逻辑而非底层调用。
- 云端API适合快速开发,本地模型适合隐私场景;
- 核心方法
embed_query和embed_documents是所有模型的通用入口; - 实际应用中需根据数据量、隐私要求、成本预算选择合适的模型。
