
零基础学AI大模型之Milvus向量数据库全解析


前情摘要
8、零基础学AI大模型之LangChain六大核心模块与大模型IO交互链
10、零基础学AI大模型之LangChain-PromptTemplate
11、零基础学AI大模型之ChatModel聊天模型与ChatPromptTemplate实战
12、零基础学AI大模型之LangChain聊天模型多案例实战
15、零基础学AI大模型之解析器PydanticOutputParser
16、零基础学AI大模型之LangChain Output Parser
17、零基础学AI大模型之大模型修复机制:OutputFixingParser解析器
20、零基础学AI大模型之RAG系统链路解析与Document Loaders多案例实战
21、零基础学AI大模型之LangChain PyPDFLoader实战与PDF图片提取全解析
22、零基础学AI大模型之LangChain WebBaseLoader与Docx2txtLoader实战
23、零基础学AI大模型之RAG系统链路构建:文档切割转换全解析
24、零基础学 AI 大模型之 LangChain 文本分割器实战
25、零基础学AI大模型之Embedding与LLM大模型对比全解析
26、零基础学AI大模型之LangChain Embedding框架全解析
28、零基础学AI大模型之向量数据库介绍与技术选型思考
零基础学AI大模型之Milvus向量数据库全解析
前面我们已经完整拆解了RAG技术链路,从文档加载、文本分割到Embedding向量转换,每一步都为“让大模型精准调用外部知识”打下基础。但生成的高维向量该如何高效存储、快速检索?这就需要专门的向量数据库来解决——今天我们聚焦AI大模型生态的核心存储组件:Milvus向量数据库,带你从基础概念到实战落地全面掌握。
一、什么是Milvus向量数据库?
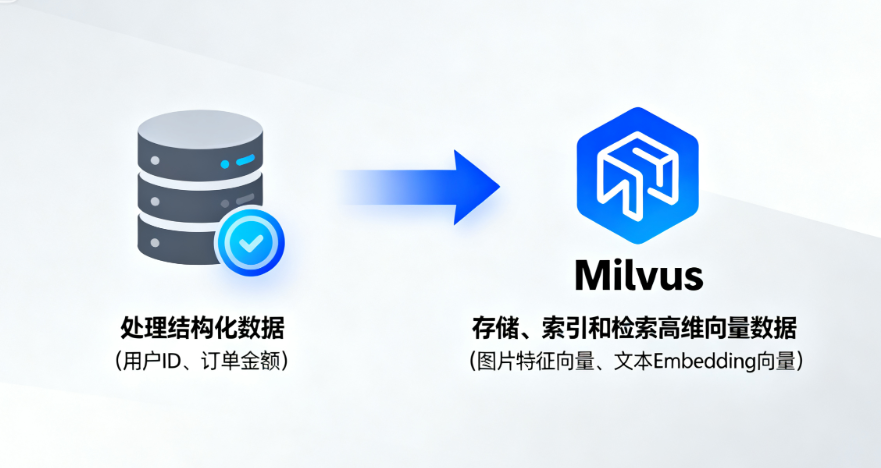
Milvus是一款高性能、高扩展性的开源向量数据库,专门用于存储、索引和检索高维向量数据。它既能以开源软件形式本地部署,也能通过云服务快速使用,适配从笔记本电脑到大规模分布式系统的全场景需求,是AI大模型(尤其是RAG系统)中向量存储的核心选择。
简单说,传统关系型数据库擅长处理结构化数据(如用户ID、订单金额),而Milvus专注于“理解”向量的相似度——比如两张图片的特征向量、两段文本的Embedding向量,它能快速找到最相似的结果,这正是AI应用需要的核心能力。
二、Milvus核心特性与性能指标
Milvus的优势集中在“快、大、灵”三大维度,关键指标如下:
指标类型 | 核心表现 |
|---|---|
数据规模 | 支持千亿级向量存储,适配PB级数据量 |
查询性能 | 亿级向量亚秒级响应,支持GPU加速提升效率 |
扩展性 | 水平扩展架构,可动态增删节点,应对数据增长 |
查询能力 | 支持相似度搜索、混合查询(向量+标量过滤)、多向量联合查询 |
生态兼容 | 原生支持Python/Java/Go/REST API,无缝整合TensorFlow、PyTorch等主流AI框架 |
核心能力补充:支持多种相似度计算方式,包括欧氏距离(L2,数值越小越相似)、余弦相似度(基于向量夹角,越接近1越相似)、内积(IP,数值越大越相似),满足不同AI场景需求。
三、Milvus部署方式:按需选择
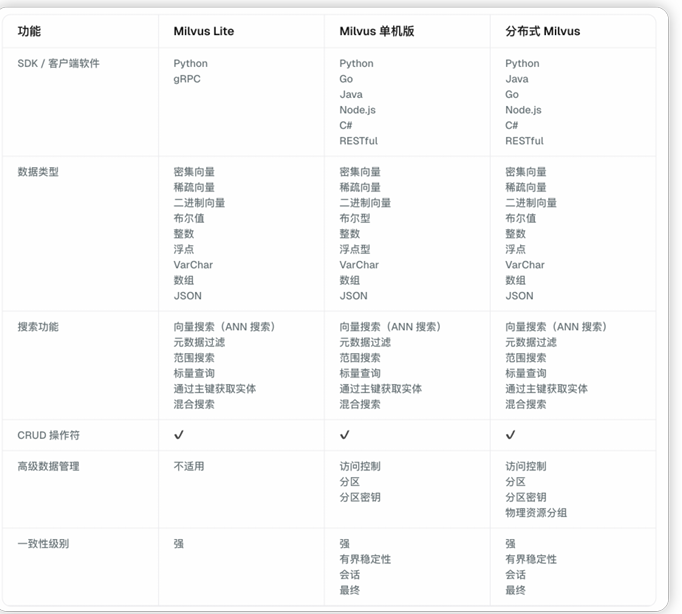
Milvus提供多种部署选项,覆盖从原型开发到企业级生产的全流程,新手可从轻量版入手:
- Milvus Lite:Python库形式的轻量级版本,无需复杂部署,适合Jupyter Notebook快速原型开发或边缘设备运行。
- Milvus Standalone:单机服务器部署,所有组件打包在一个Docker镜像中,一键启动,适合测试或小规模应用。
- Milvus Distributed:云原生架构,部署在K8S集群上,支持冗余备份,适配十亿级以上大规模生产场景。
- 云服务/BYOC:无需自建集群,直接使用云厂商提供的SaaS服务,或采用“自带云”(BYOC)模式保障数据私有性。
四、核心概念:类比关系型数据库,一看就懂
对于熟悉传统数据库的开发者,Milvus的核心概念可直接对应理解,降低学习成本:
Milvus向量数据库 | 关系型数据库 | 核心说明 |
|---|---|---|
Collection(集合) | 表(Table) | 存储结构相同的实体集合,Schema定义字段类型(主键、向量、标量) |
Entity(实体) | 行(Row) | 数据基本单位,包含主键、向量字段、标量字段(如分类、价格) |
Field(字段) | 表字段(Column) | 分为向量字段(存储高维向量)和标量字段(存储结构化数据,支持过滤) |
关键概念细节:
- 主键(Primary Key):唯一标识实体,支持整数或字符串类型,注意Milvus目前不自动去重,允许重复主键存在。
- 向量字段:需指定固定维度(如768维,对应主流Embedding模型输出),存储浮点型数组。
- 动态字段:Milvus 2.3+支持动态添加字段,无需重启集合,适配灵活业务场景。
五、Milvus架构解析:数据如何流转?
Milvus采用云原生微服务架构,核心组件分工明确,数据处理流程清晰:
1. 核心组件与职责
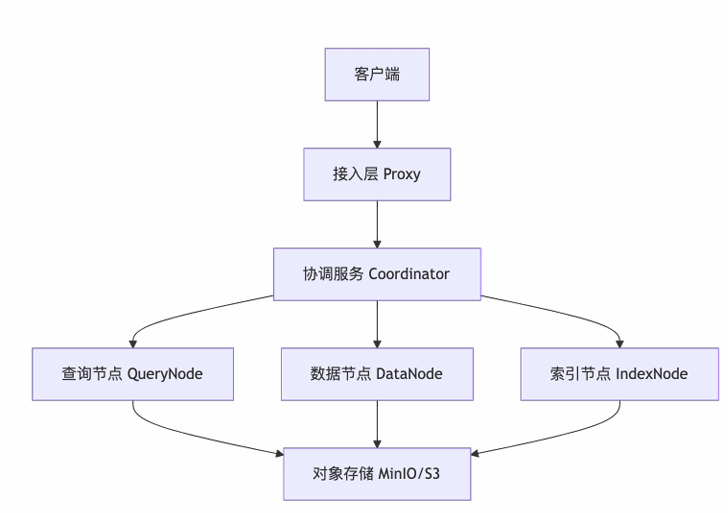
- Proxy:客户端请求入口,负责路由转发、负载均衡和协议转换(gRPC/RESTful),屏蔽底层复杂度。
- Query Node:执行向量搜索、标量过滤、相似度计算,支持内存索引加载和GPU加速。
- Data Node:处理数据插入、日志流处理和数据持久化,通过写日志(WAL)保障数据一致性。
- Index Node:后台异步构建和优化索引,不影响查询性能。
- Coordinator:管理集群元数据、调度任务,支持高可用部署(基于etcd存储元数据)。
2. 数据处理流程
插入数据 → 生成日志(保障一致性) → 持久化到存储层 → 后台构建索引 → 支持查询检索,全程无需人工干预索引构建。
六、数据组织与索引:提升查询效率的关键
1. 数据组织方式
- 分区(Partition):按业务逻辑划分数据(如按时间、地域),查询时仅扫描目标分区,减少计算量。
- 分片(Sharding):数据写入时按主键哈希分配到不同节点,实现并行写入,提升吞吐量。
- 段(Segment):物理存储单元,自动合并新增数据,分为“增长段”(持续写入)和“密封段”(持久化存储)。
2. 索引类型:按需选择平衡性能与精度
索引是提升查询速度的核心,Milvus支持多种索引类型,一个向量字段仅能指定一种:
索引类型 | 适用场景 | 核心特点 |
|---|---|---|
FLAT | 小数据集、需精准搜索 | 精度100%,构建速度快,但内存消耗高 |
IVF_FLAT | 平衡精度与性能的通用场景 | 精度99%,内存消耗中等,构建速度较快 |
HNSW | 高召回率需求(如推荐系统) | 精度98%,查询速度快,但内存消耗高 |
IVF_PQ | 超大规模数据存储 | 精度95%,内存消耗低,适合千亿级向量场景 |
七、实战代码:Python创建Collection与基础操作
下面通过简单示例,演示如何用Python操作Milvus(基于pymilvus库),适合新手入门:
1. 安装依赖
2. 定义Schema并创建Collection
3. 后续操作提示
- 构建索引:创建集合后需为向量字段构建索引,才能高效查询(如
collection.create_index("vector", index_params={"index_type": "IVF_FLAT", "nlist": 128}))。 - 插入数据:通过
collection.insert()方法插入实体数据(包含id、vector、category、price字段)。 - 查询数据:支持向量搜索(
collection.search())或混合查询(结合price < 100等标量过滤条件)。
八、适用场景:Milvus在AI中的核心应用
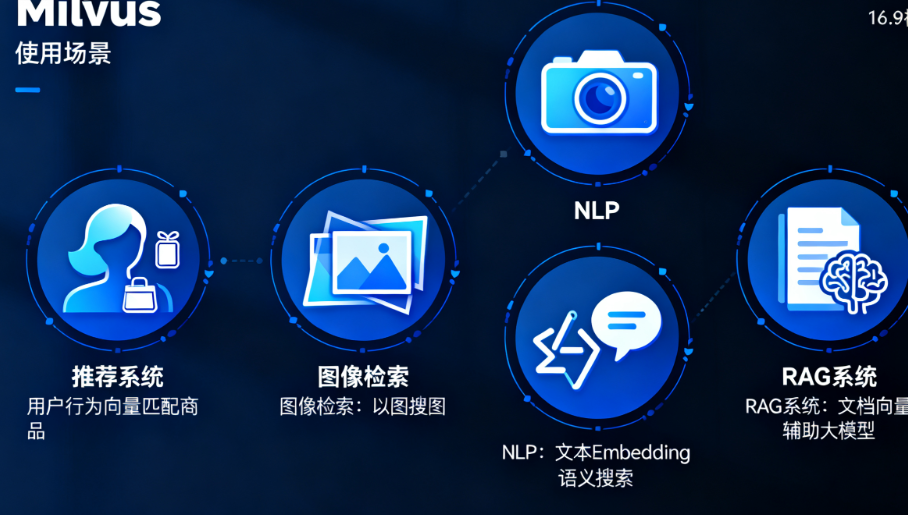
Milvus作为向量数据库的标杆产品,已被全球大厂广泛应用,核心场景包括:
- 推荐系统:基于用户行为向量(如浏览、购买记录),快速匹配相似商品/内容。
- 图像检索:提取图片特征向量,实现“以图搜图”(如电商商品检索、版权保护)。
- 自然语言处理(NLP):存储文本Embedding向量,支持语义搜索(如智能问答、文档检索)、文本聚类。
- RAG系统核心存储:承接Embedding模型生成的文档向量,为大模型提供精准的外部知识检索能力(呼应前文RAG技术)。
总结
Milvus向量数据库凭借高性能、高扩展性和丰富的生态支持,成为AI大模型(尤其是RAG系统)的核心存储组件。从新手入门的Lite版到企业级分布式部署,从简单的相似度搜索到复杂的混合查询,Milvus能满足不同阶段、不同场景的需求。
